Part 1: Discovering API Function Usage through Source Code Review
Welcome to my new blog series, “On Detection: Tactical to Functional,” where I intend to explore and expand my understanding of that which we attempt to detect. We’ve all operated within the Tactics, Techniques, and Procedures paradigm for so long that I feel our ability to discuss complex technical topics is often stunted by our ability to express ideas. My recent observation is that a three-tiered taxonomy (such as TTP) is far too limiting to facilitate the necessary conversation to improve our thinking about detection. I believe there are more than three tiers that exist which means our three-tier taxonomy necessarily leads to grouping different things at the top or, in our case, at the bottom of the taxonomy. For this reason, it seems to me that the term “Procedures” is used too broadly to describe too many things and limits our ability to really get into the technical details. Tactics, Techniques, and Procedures are all abstract concepts that serve as categories to group concrete things together. I want to start at the concrete and work my way up to explore all of the levels in between.
For this reason, we will start with an analysis of API Functions which, in some sense, are the base component of functionality within an operating system. This first post will dig into a well-known attack tool, Mimikatz, and determine which API functions it is using to accomplish a particular task. I hope you enjoy it!
Introduction
In my Understanding the Function Call Stack post, I introduced the nesting nature of Windows API functions. There is almost always a superficial/documented version of the API that then goes through a series of calls to deeper, more fundamental functions that are less likely to be documented but still able to be called directly by applications. I then explained that malware developers could use the knowledge of this nesting to call the less expected/documented version of a function to evade some sensors making their actions “invisible.” In that post, we explored CreateFileW specifically and dug into it, but what we didn’t explain was the process for how we might identify which function we should be interested in.
This post will introduce one process, source code review, for determining which function(s) are used by a given malware sample. For this demonstration and the next couple of posts in this series, we will use everyone’s favorite tool Mimikatz and explore exactly which API functions it relies on to perform its most popular command, sekurlsa::logonPasswords. Remember that a tool is often just functioning as an even more superficial wrapper on top of a series of API functions doing the hard work. This is a fundamental concept that is described in my Capability Abstraction post. Here we will work through analyzing Mimikatz’s source code to understand which function(s) it calls, and then we can leverage the process demonstrated in my previous post to see how those functions nest underneath.
As a result, this post provides a detailed walk-through of how I analyzed the Mimikatz source code to tie the logonPasswords command to its respective function call(s).
Analyzing Mimikatz’ sekurlsa::logonPasswords
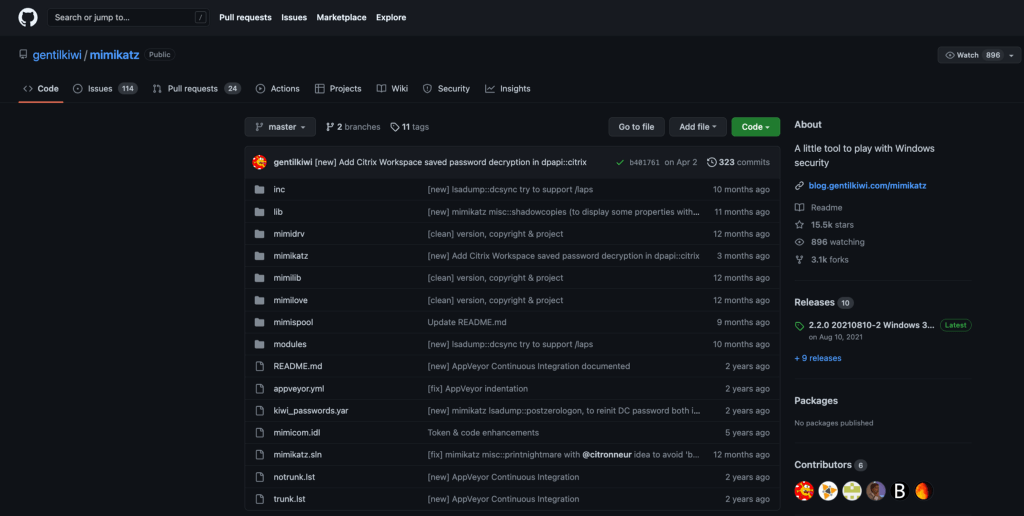
The first obstacle is determining where to start the analysis within the code base. The Mimikatz Github project provides numerous versions of the same First, we are planning on digging into the main component of Mimikatz, so we will skip the mimidrv, mimilib, and other folders and navigate to the mimikatz folder.
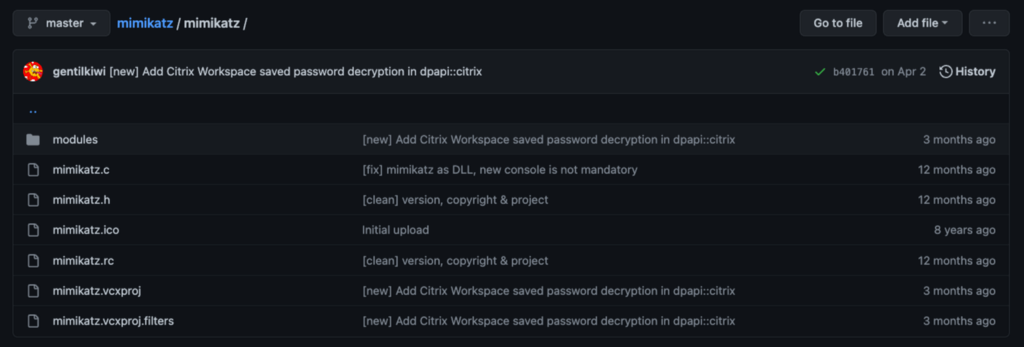
Within the Mimikatz folder, we see some files related to the visual studio code project and the main mimikatz.c file. Let’s think about how Mimikatz commands work. Every Mimikatz command follows the module::command syntax. This means that we are interested in digging into the modules folder.
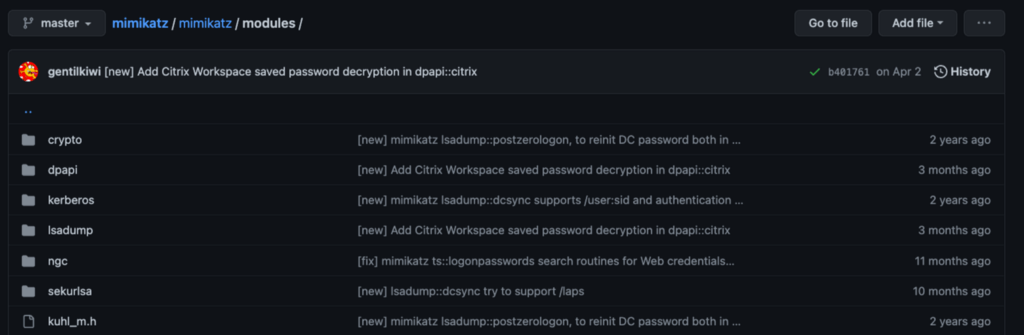
Once in the modules folder, we can consider the exact command used. This is an excellent time to think about the command to tell Mimikatz to dump credentials from LSASS. If we are unfamiliar with the tool’s usage, then we might not know. In that case, I’d recommend revisiting the source that brought the tool to our attention in the first place to see EXACTLY how it was used there. Maybe this would be a threat report, or maybe it is a blog post, but either way, a good source document should include the specific commands that were used.
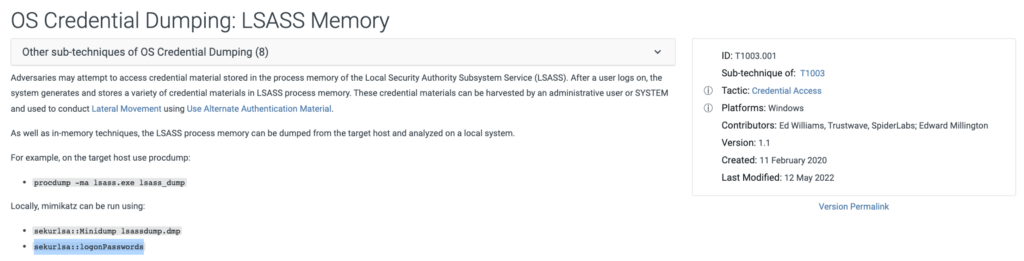
The most common or canonical Mimikatz command to dump credentials from LSASS process memory is sekurlsa::logonPasswords. That means the code we are interested in is in the sekurlsa folder. Let’s check it out.
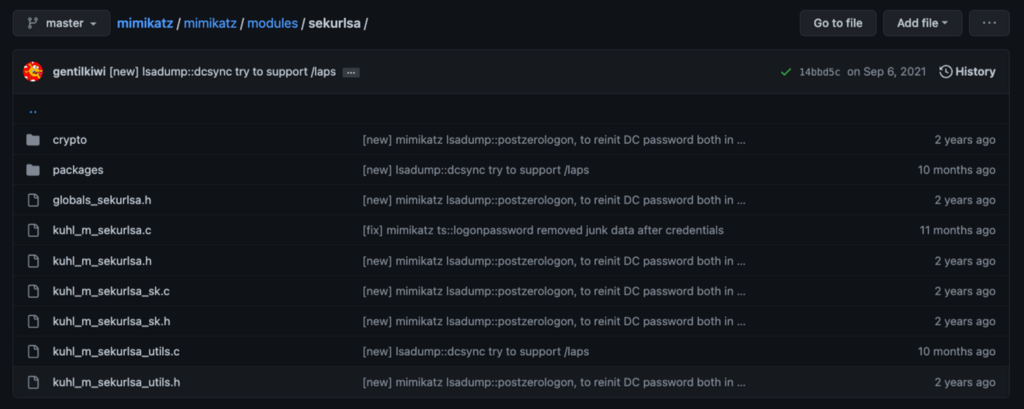
In the sekurlsa, we find several files. The main file is kuhl_m_sekurlsa.c, so we can click on that and dig in.
Getting Started
Each module in Mimikatz has a central file (named after the module), and at the beginning of the main file, we find a function table. This table is used to correlate a command to the internal function that is executed when it is issued. Here we see that the logonPasswords command points to kuhl_m_sekurlsa_all.
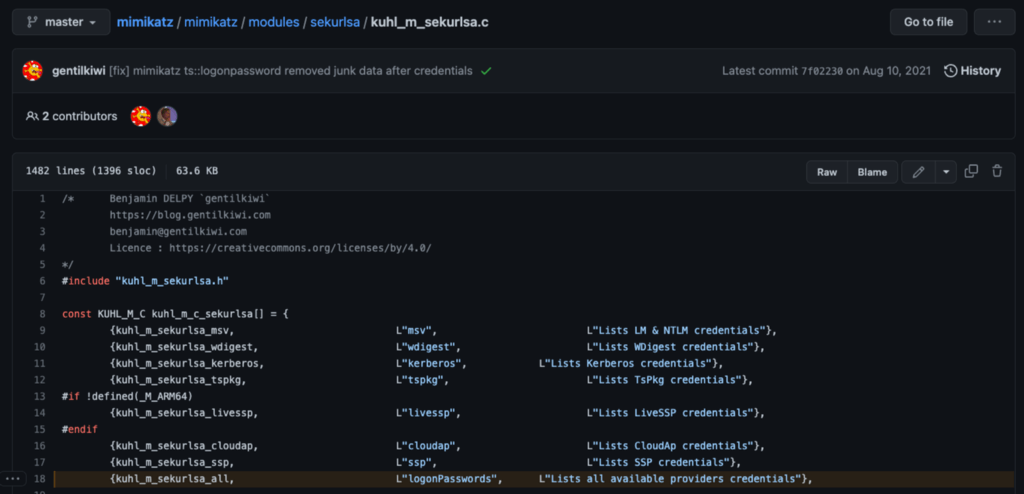
At this point, we begin to follow a series of calls to internal functions. The kuhl_m_sekurlsa_all function calls the kuhl_m_sekurlsa_getLogonData function with two parameters. The first parameter is called lsassPackages, and the second appears to measure the size of the lsassPackages array.

Let’s take a second to see what the lsassPackages array contains. This constant contains an array of type PKUHL_M_SEKURLSA_PACKAGE instances, which represent the different Security Support Provider/Authentication Packages that come default on Windows. We can look at the PKUHL_M_SEKURLSA_PACKAGE structure definition to better understand what is contained in each.
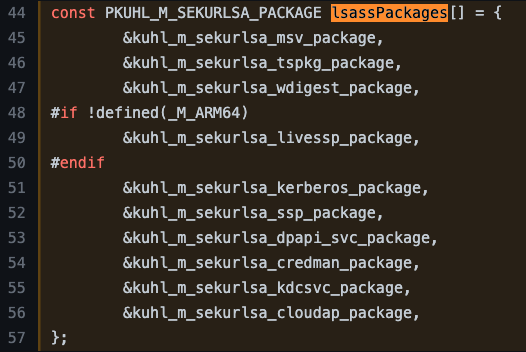
The KUHL_M_SEKURLSA_PACKAGE structure is defined as having 5 fields in total. The first is the Name, presumably of the Authentication Package itself. The second field is called CredsForLUIDFunc, which appears to be some sort of callback function, possibly intended to retrieve credentials from the package. The third is simply a boolean value called isValid. However, there isn’t enough information here to understand EXACTLY what this field’s intended use is. The fourth field is the module’s name (DLL) that implements the Authentication Package. The fifth and last field is called Module and is of type KUHL_M_SEKURLSA_LIB.
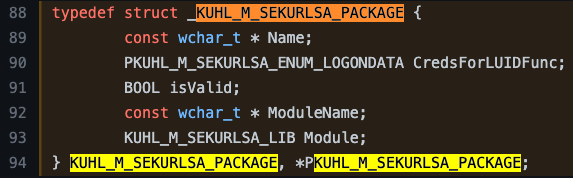
Now we can look at the definition of the kuhl_m_sekurlsa_kerberos_package instance where we see that the name is set to kerberos, a function called kuhl_m_sekurlsa_enum_logon_callback_kerberos is set as the CredsForLUIDFunc value, the isValid field is set to TRUE, the ModuleName is set to kerberos.dll, and lastly, it appears that the final field is being initialized as a NULL instance of KUHL_M_SEKURLSA_LIB.
KUHL_M_SEKURLSA_PACKAGE kuhl_m_sekurlsa_kerberos_package = {L"kerberos", kuhl_m_sekurlsa_enum_logon_callback_kerberos, TRUE, L"kerberos.dll", {{{NULL, NULL}, 0, 0, NULL}, FALSE, FALSE}};
With that understood, let’s check out the implementation of the kuhl_m_sekurlsa_getLogonData function. It turns out that there isn’t much to get excited about here. We see the lsassPackages array being passed in along with the number of packages in the form of the nbPackages parameter. These parameters are added to an OptionalData variable and then passed as the second parameter to a new function called kuhl_m_sekurlsa_enum. Additionally, we see that the first parameter is kuhl_m_sekurlsa_enum_callback_logondata which seems to be some sort of callback function that we should investigate.

The following function is where things REALLY start to get interesting and a little convoluted. The kuhl_m_sekurlsa_enum function has a few decisions that must be made and a few functions that must be called. We will explore what we see and explain how to determine which path, for example, the code will choose. The first interesting thing we notice is the call to kuhl_m_sekurlsa_acquireLSA. Let’s take a look at its implementation.
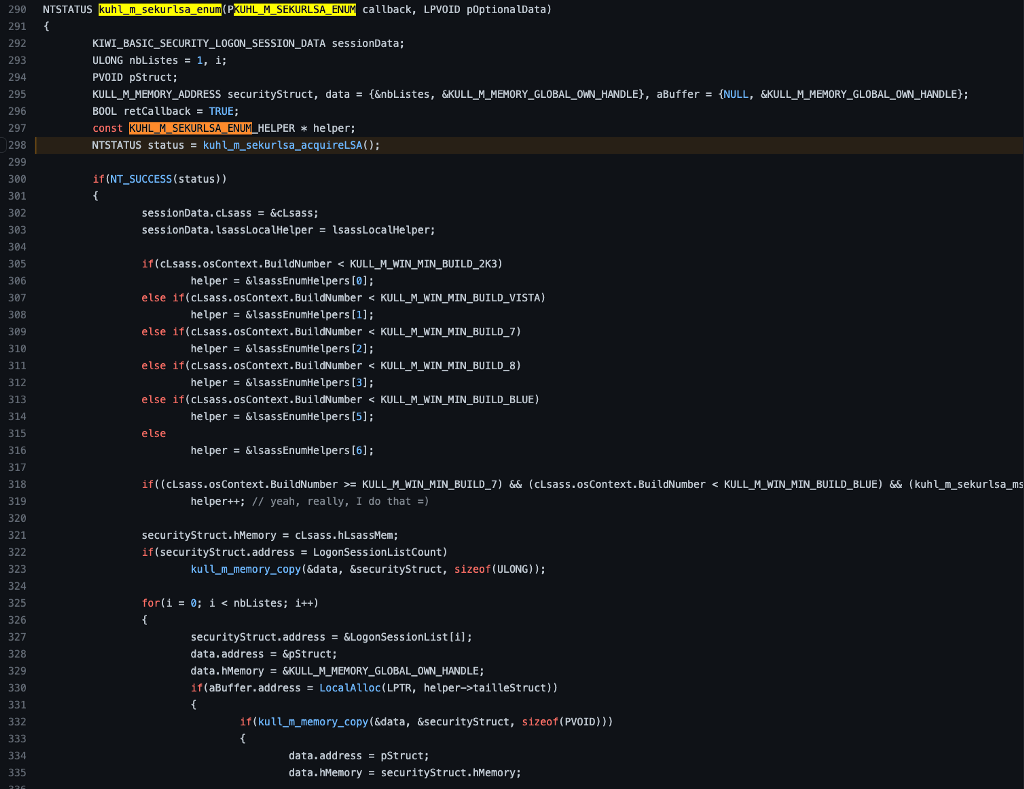
The kuhl_m_sekurlsa_acquireLSA function has a couple of decisions to make. The first decision is to check whether a handle, presumably to the LSASS process, already exists. If it doesn’t, it follows up with a check to see if the pMinidumpName variable has been set. We can check the code to see if either of these conditions is met.
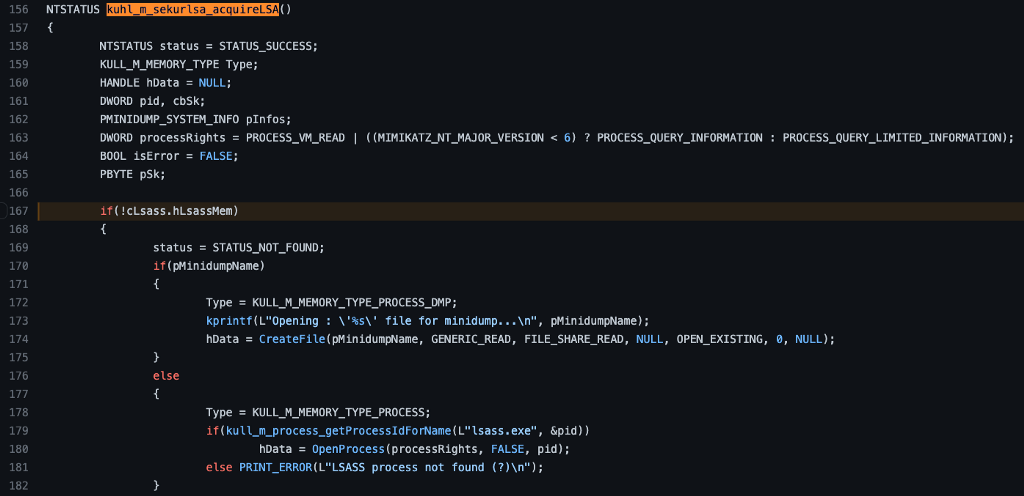
The first if clause checks to see if cLsass.hLsassMem is set as NULL. If we find where the cLsass variable was first declared, we find this bit of code cLsass = {NULL, {0,0,0}};. It appears as if cLsass is a structure with two fields. The first is set explicitly to NULL, while the second, a different type of structure, is set to three zeros. We should check the type definition for KUHL_M_SEKURLSA_CONTEXT to see the significance of either or each.

According to the KUHL_M_SEKYRLSA_CONTEXT structure’s definition, the first field is hLsassMem, the name of the value checked in kuhl_m_sekurlsa_acquireLSA. This means we can revisit the instantiation of the cLsass variable and see that the hLsassMem is NULL, which means that the conditional statement (!cLsass.hLsassMem) evaluates as true, which means we will execute the code contained within the if statement.

The next check is related to the pMinidumpName value. You may have noticed this value was set in an earlier screenshot when we saw the cLsass value being declared.
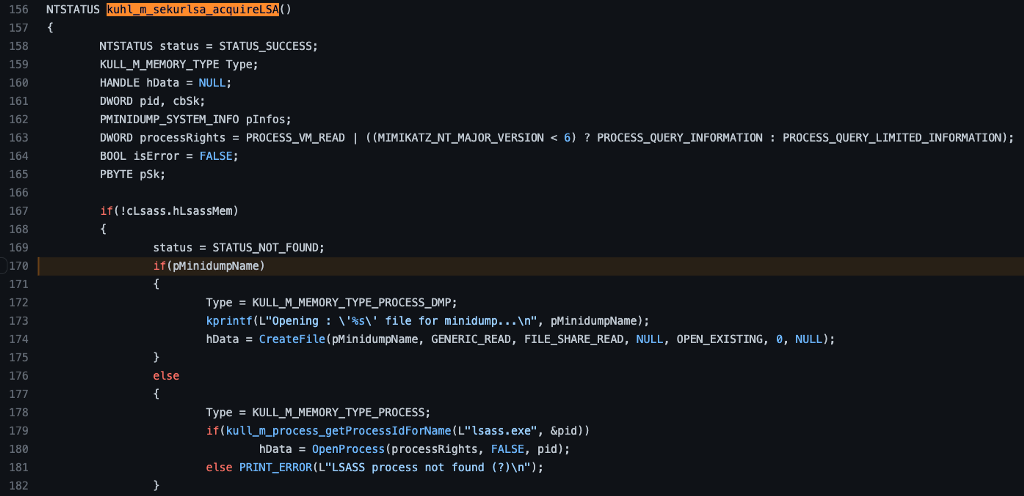
I’ve reshared the image, and we can see that the pMinidumpName variable is set to NULL.

This means that the conditional statement (pMinidumpName) evaluates to false, which results in execution being passed to the else block.
Process Enumeration
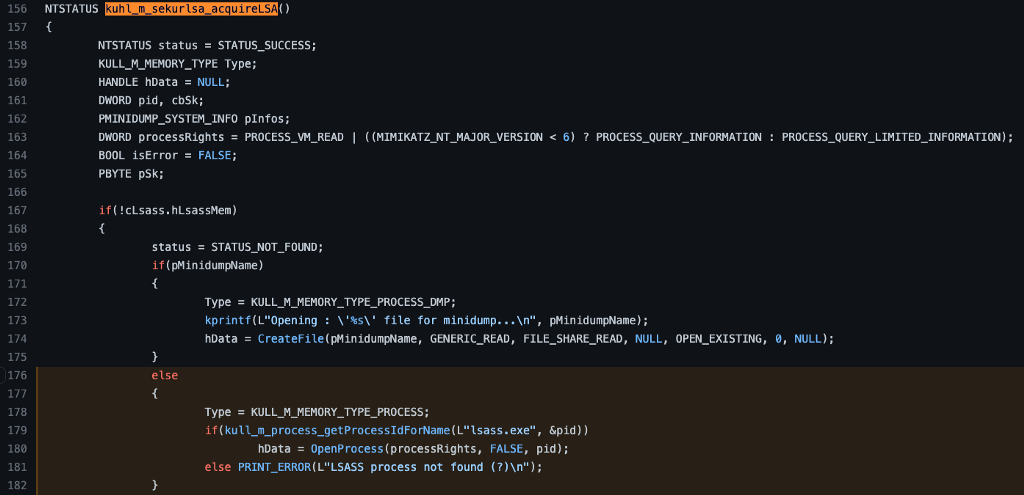
Let’s look at the first line in the else block where we see that a variable called Type is being set to the valueKULL_M_MEMORY_TYPE_PROCESS. Notice line 159, where the Type variable is being declared as the type KULL_M_MEMORY_TYPE.
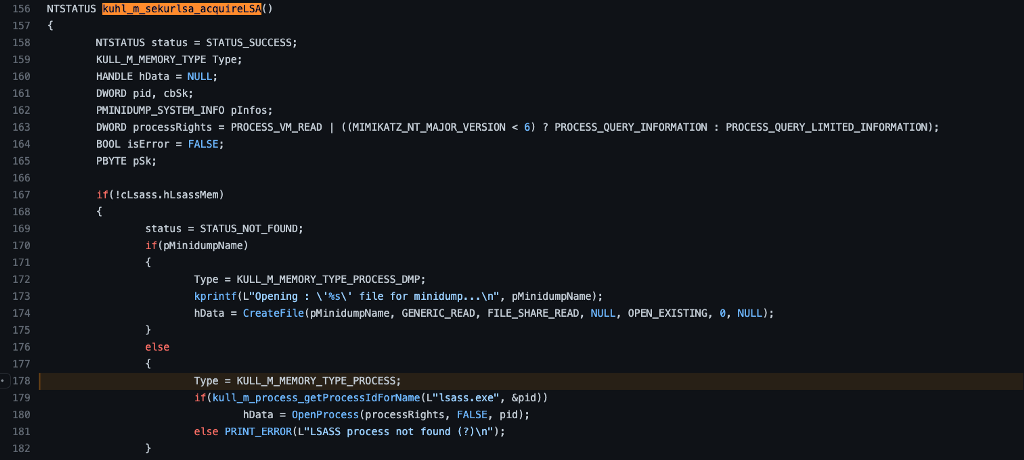
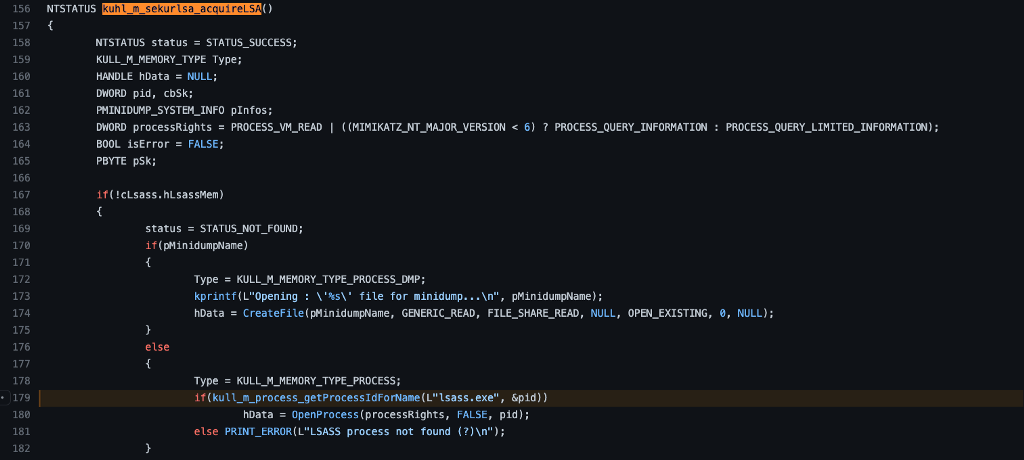
Next, we see the kull_m_process_getProcessIdForName subroutine being called. Notice that it takes two parameters, the first is the string lsass.exe, and the second is a pointer to a pid variable. The variable definition (line 161) shows that pid is a DWORD. Based on the function’s name, we might expect it to retrieve the process information, specifically the Process Identifier, for a process named lsass.exe. Let’s check it out.
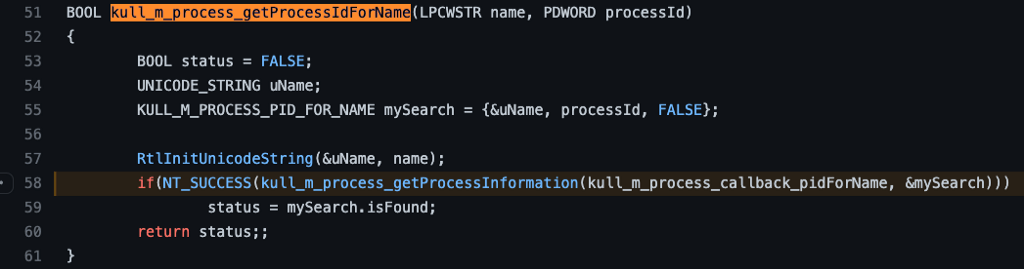
We start our analysis of the kull_m_process_getProcessIdForName function by noticing a few variables being initialized. Importantly we observe the mySearch variable being instantiated as an instance of the KULL_M_PROCESS_PID_FOR_NAME structure. This structure is instantiated with three fields, the first is a pointer to the previously instantiated uName variable, the second is the second parameter to the function, which is called processId here, and the third is the boolean value FALSE. Remember that the calling function passed in a pointer to a variable called pid, which is now called processId in this function. Next, we see a call to an API function called RtlInitUnicodeString, which passes in a pointer to the uName variable we just talked about and the first parameter, which is now called name. We know that the calling function passed the string lsass.exe as the first parameter, so this appears to be applying that value to a particular data structure type expected later. Lastly, we see a pointer to the mySearch variable being passed as the second parameter to a new function called kull_m_process_getProcessInformation. Let’s check it out.
The kull_m_process_getProcessInfroamtion function is pretty simple and straightforward. We see a call to the kull_m_process_NtQuerySystemInformation function where the first argument is an enum value SystemProcessInformation (the source of this enumeration can be found here), the second argument is a pointer to a buffer, and the third argument is 0.
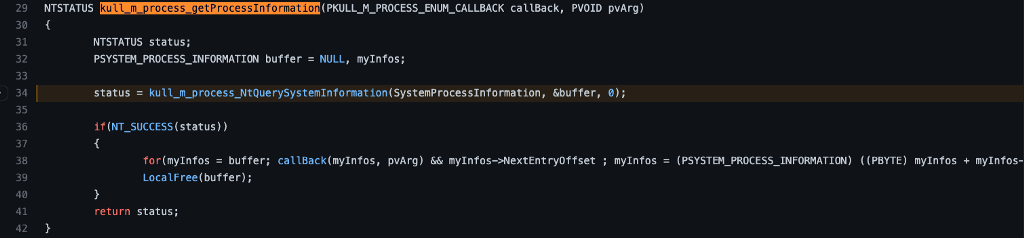
When we investigate the kull_m_process_NtQuerySystemInformation function, we see that it is built simply to make a call to the NtQuerySystemInformation API function. NtQuerySystemInformation is a function meant to facilitate the enumeration of many different bits of information, one of which is related to running processes (this is indicated to the function by the SystemProcessInformation enumeration value seen earlier). The problem is that because NtQuerySystemInformation can return results of unpredictable types and sizes, the authors created a mechanism to enumerate the expected output size (buffer). This feature works because the function writes the actual length of the information requested to the parameter, represented here by returnedLen, and if that value is greater than the buffer size (represented by informationLength here), the function fails. The program can then use the value held in returnedLen to allocate an appropriately sized buffer and pass it in a second time.
However, if we look at line 19, it appears this code doesn’t leverage that built-in process for determining the size required for the output data. Instead, it seems the buffer is initialized to a length of 0x1000 bytes, and if the function fails, the sizeOfBuffer value is shifted to the left one bit (sizeOfBuffer <≤ 1), the buffer is reallocated, and the function is called again. This process repeats until the call is successful.
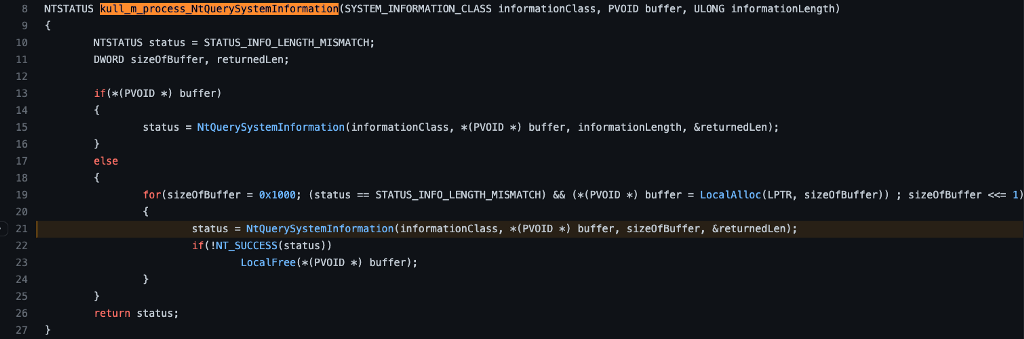
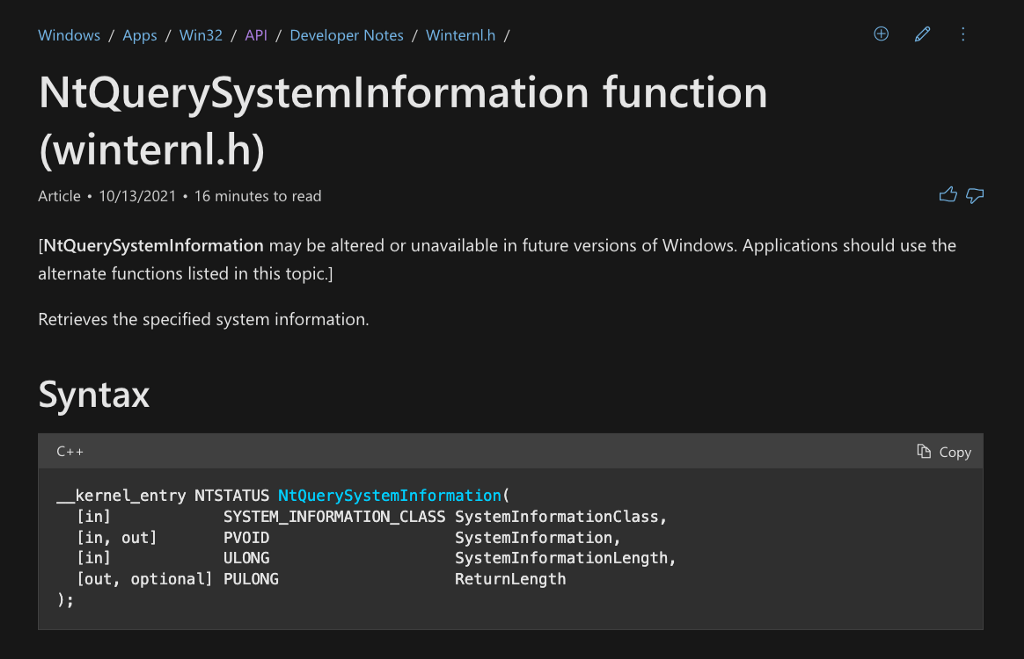
With this understanding, we can then check the API documentation for NtQuerySystemInformation to better understand how it works. Generally speaking, this code section is meant to enumerate all processes and iterate through them until it finds lsass.exe. Once it finds the process it is looking for, it records the process identifier and returns it to be used in the next step.
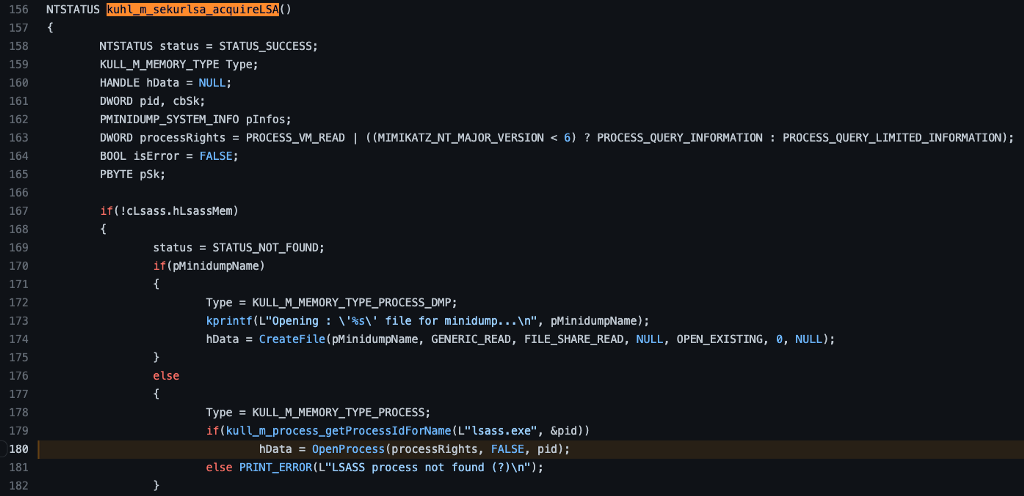
Process Access
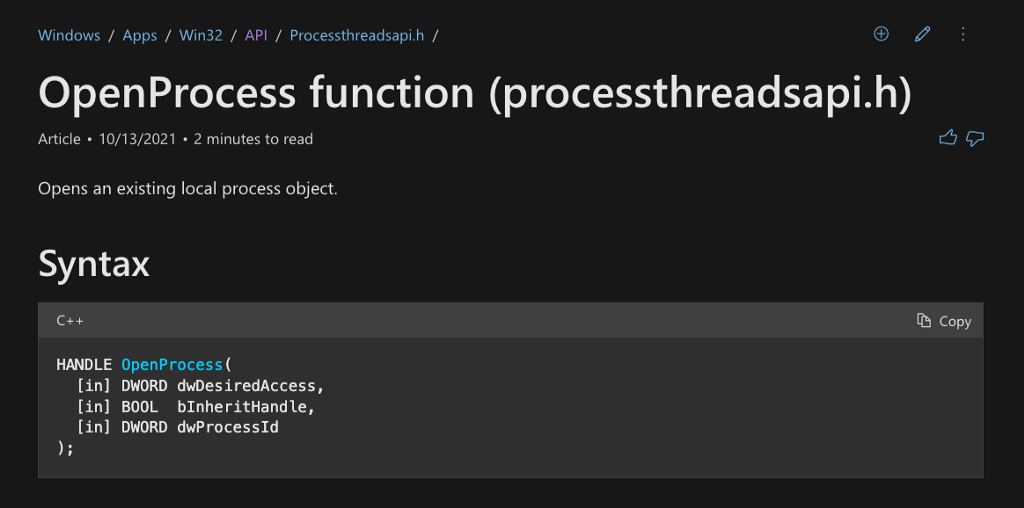
After a short detour, we are back at kuhl_m_sekurlsa_acquireLSA, where the following line of interest calls the OpenProcess Windows API Function. Notice that there are three parameters being passed. The first is the processRights variable which is set on line 163 to either be PROCESS_VM_READ | PROCESS_QUERY_INFORMATION or PROCESS_VM_READ | PROCESS_QUERY_LIMITED_INFORMATION depending on the system’s Major Version.
It’s worth noting that PROCESS_VM_READ | PROCESS_QUERY(_LIMITED)_INFORMATION is the minimum necessary access rights required in order for the resulting handle to be used with the next function call (which we will encounter later in the post). Since the processRights value is a bit field, it is possible for alternative tools to add access rights even if they aren’t needed in order to evade static detections.
The second parameter is simply a boolean FALSE value, and the third is the pid variable derived from the call to kull_m_process_getProcessIdForName. In other words, it is the Process Identifier for the LSASS process.
If we weren’t familiar with what OpenProcess is used for and what parameters it takes, we could reference the documentation to better understand how to use it. This function is used to open a handle to a process. This is necessary because processes reside in the kernel, which means user-mode code cannot access them directly. Instead, the operating system provides an interface, OpenProcess, to request access to a process. It then grants access according to the Discretionary Access Control List (DACL). Check the documentation page for more information on how OpenProcess is used and what the parameter signifies.
Process Read
Now that we’ve finished the analysis of kuhl_m_sekurlsa_acquireLSA, we can return to kuhl_m_sekurlsa_enum and continue our investigation there. After opening the process handle to LSASS, we can continue skimming the code, and the following function call is kull_m_memory_copy. It appears it is taking three parameters, two pointers to KULL_M_MEMORY_ADDRESS structures (the data and securityStruct variables are instantiated on line 295) and one DWORD. Let’s take a look at the code for kull_m_memory_copy.
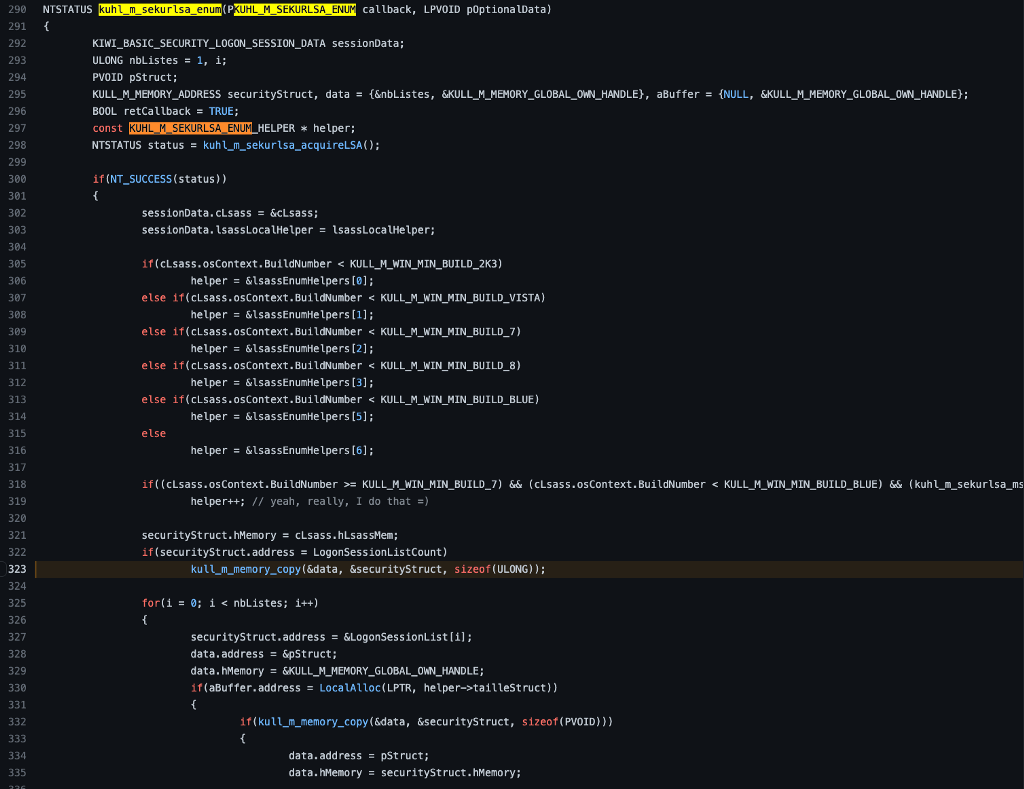
We see that the code implementation of kull_m_memory_copy is made up of a series of nested switch statements which means that it behaves differently depending on a few variables we must explore to understand the proper flow for the logonPasswords command.
The first switch statement investigates the Destination variable, which was passed in as the first parameter to kull_m_memory_copy.
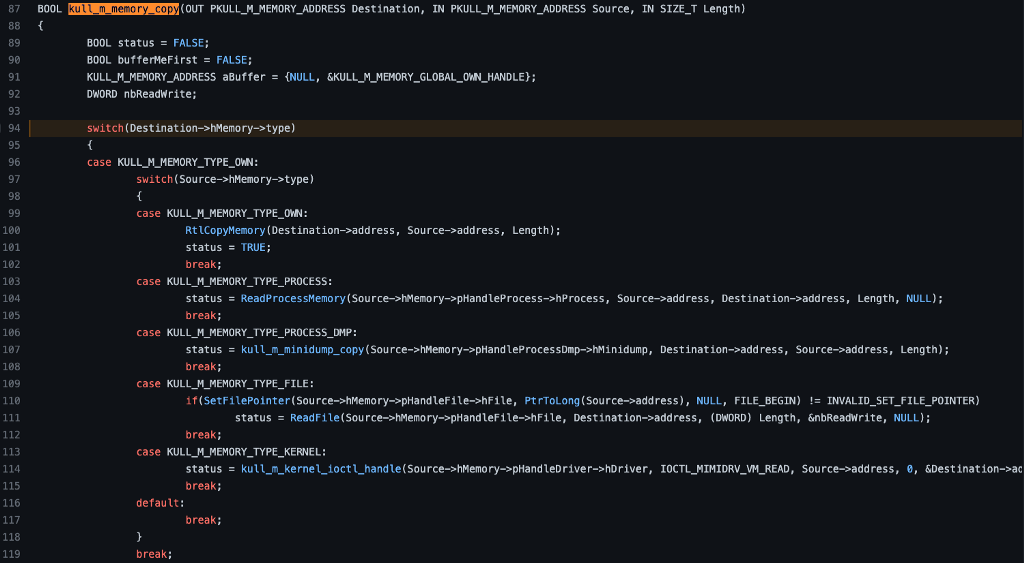
If we look at the call to kull_m_memory_copy (line 323), we can see that the first parameter is &data which is a pointer to a variable called data. We can scroll to the top of the kuhl_m_sekurlsa_enum function to find where the data variable is declared (line 295) and see that it is of the type KULL_M_MEMORY_ADDRESS, and the first field (nbListes) is set to a pointer to a ULONG which is set to 1 and the second field is a pointer to a constant value called KULL_M_MEMORY_GLOBAL_OWN_HANDLE.
Remember that the switch statement in kull_m_memory_copy looks into the Destination variable, but precisely the Destination->hMemory->type value. To determine exactly what that value is, we must check out the definition for the type assigned to the Destination variable, which is KULL_M_MEMORY_ADDRESS.

From this definition, we can see that the first field represents an address of some sort. Remember that a pointer to a ULONG with the value of 1 was assigned to this field. The second field is a pointer to a different structure called PKULL_M_MEMORY_HANDLE. Notice the name of this second field is hMemory. This means we are on our way to understanding the value embedded in Destination->hMemory->type as we’ve identified that hMemory is set to a constant called KULL_M_MEMORY_GLOBAL_OWN_HANDLE. Now we need to figure out what that constant represents.
We can search the code base for the definition of the KULL_M_MEMORY_GLOBAL_OWN_HANDLE structure and find that it is of the type KULL_M_MEMORY_HANDLE. The structure’s first field is an instance of the KULL_M_MEMORY_TYPE_OWN type (this looks like what we are interested in), and the second field is set to NULL.

Let’s check out the structure definition for the KULL_M_MEMORY_HANDLE type to see what we are dealing with. The first field is a KULL_M_MEMORY_TYPE type and is called type (this is the missing piece of the puzzle). We can refer back to the KULL_M_MEMORY_GLOBAL_OWN_HANDLE global variable definition and see that the type is set to KULL_M_MEMORY_TYPE_OWN. This gives us the information that we need to determine the choice that will be made in this first switch statement.
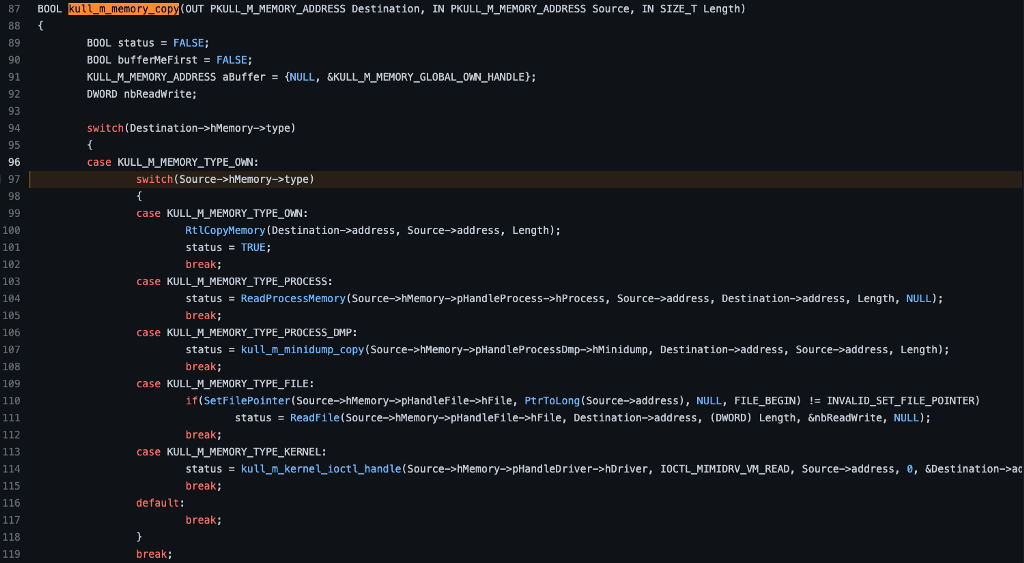
Upon returning to kull_m_memory_copy, we can see that because Destination->hMemory->type is set to KULL_M_MEMORY_TYPE_OWN that the switch statement will choose the first case.
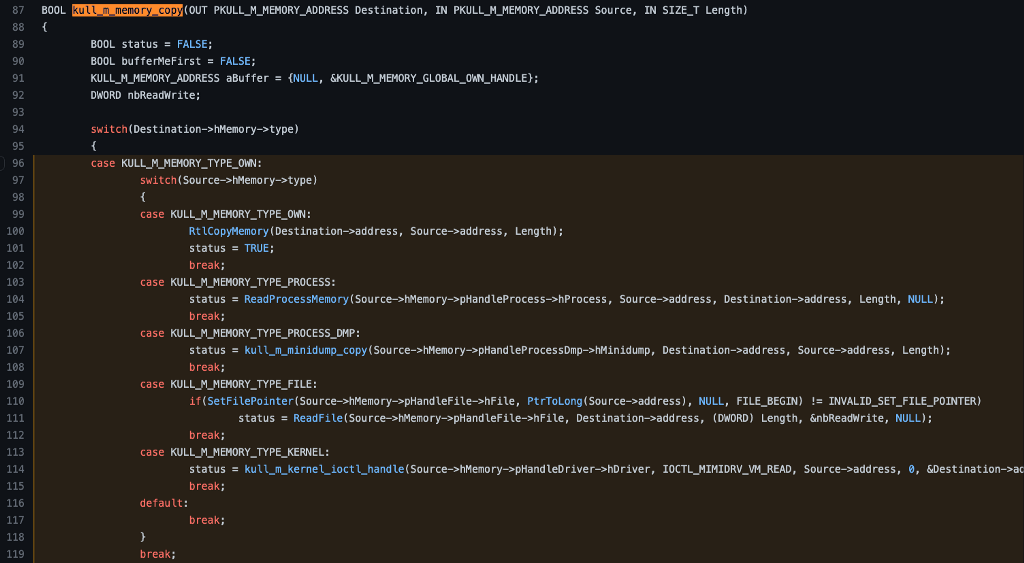
Don’t celebrate too much because as soon as we start following the code inside our selected case condition, we find ANOTHER switch statement. This time it is investigating the Source parameter, specifically the Source->hMemory->type field. This is the same as the aforementioned switch statement but focused on Source instead of Destination this time. The Source parameter is the second parameter passed into kull_m_memory_copy, so let’s go back to the calling function and check it out.
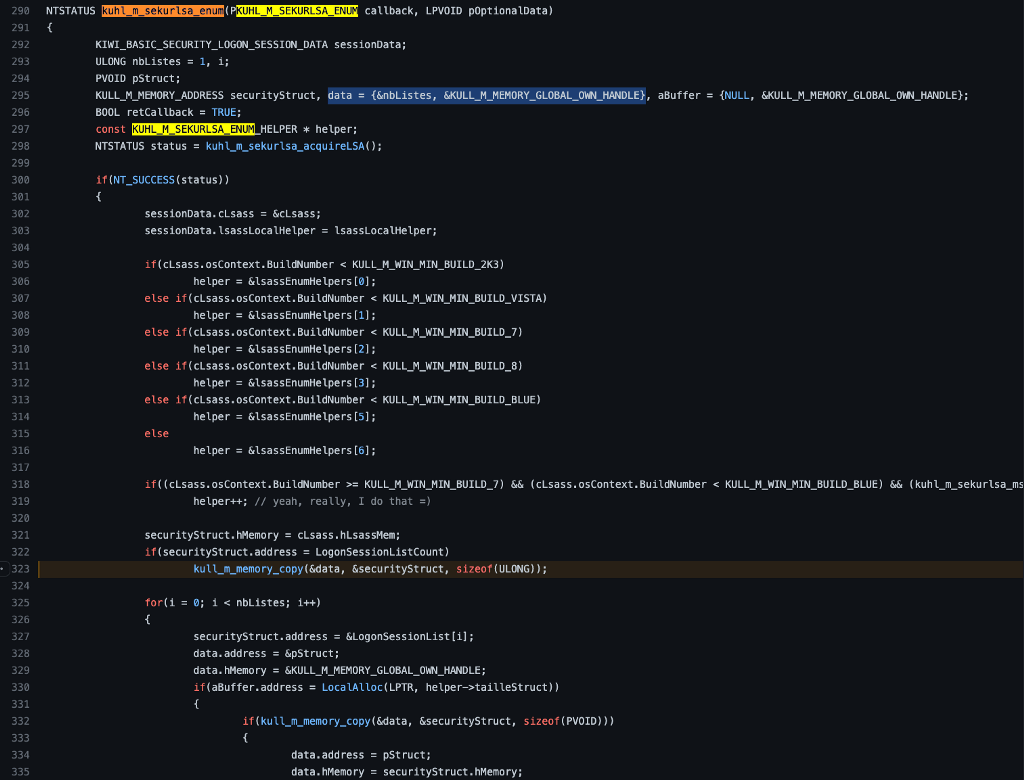
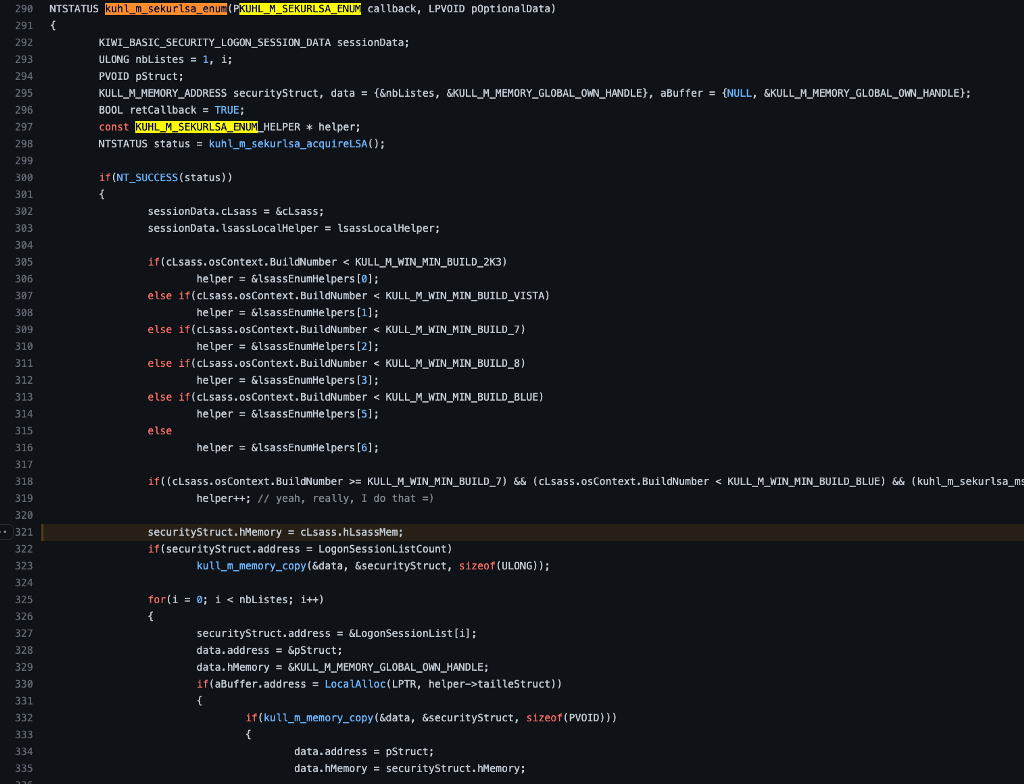
We can see (line 323) that the second parameter to the kull_m_memory_copy function call is a pointer to a variable called securityStruct, which is instantiated at the beginning of kuhl_m_sekurlsa_enum (line 295) as a null value of type KULL_M_MEMORY_ADDRESS. We also see (line 321) that securityStruct.hMemory is being set to the value of the cLsass.hLsassMem variable.
Now would be a good time to revisit the KUHL_M_MEMORY_ADDRESS structure definition, where we can see that the hMemory field is of the type KULL_M_MEMORY_HANDLE.

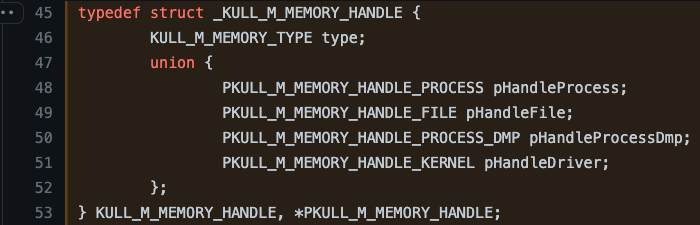
We can then review the KULL_M_MEMORY_HANDLE structure definition to see that it has two fields. The first field is called type, the value we are interested in to determine which case we will follow in the switch statement. The second field can be any of four possible handle types (PKULL_M_MEMORY_HANDLE_PROCESS, PKULL_M_MEMORY_HANDLE_FILE, PKULL_M_MEMORY_HANDLE_PROCESS_DMP, or PKULL_M_MEMORY_HANDLE_KERNEL).
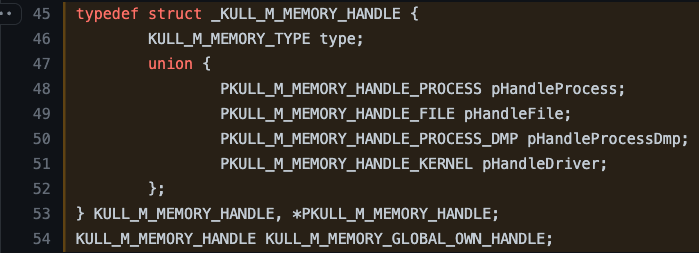
So now we need to figure out where the cLsass variable is being set to understand the contents of the securityStruct variable. Recall that we discovered earlier that the cLsass variable is designated as a global variable and instantiated with NULL values.
This means it must get set somewhere in the code we’ve already investigated. Remember in kuhl_m_sekurlsa_acquireLSA that it first checks to see if cLsass.hLsassMem contains a valid handle. If not, it checks to see if pMinidumpName is set. If not, it executes the section of code highlighted in the image below.
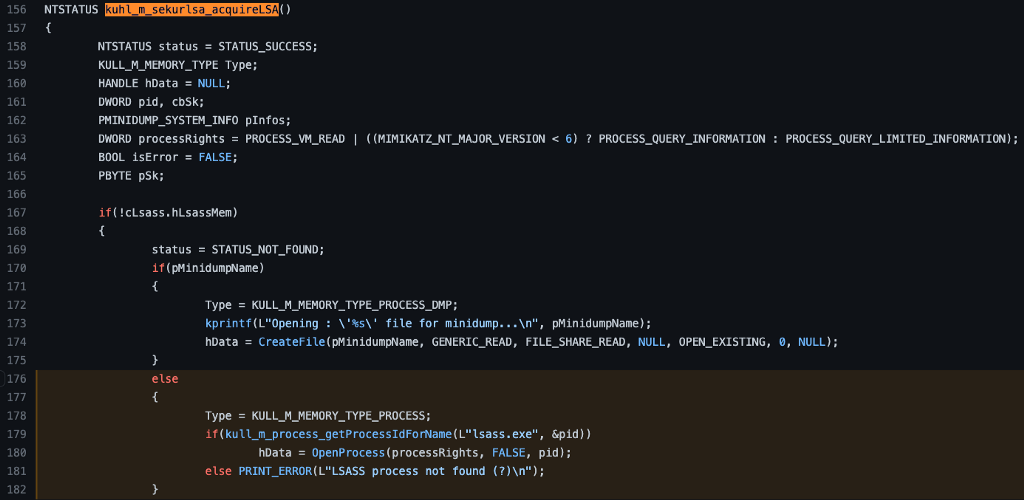
Here we see that a variable called Type is being set to KULL_MEMORY_TYPE_PROCESS. We can see that Type is declared at the beginning of the kuhl_m_sekurlsa_acquireLSA function as an instance of the KULL_M_MEMORY_TYPE type. We are interested in this value, but we must first understand how this value is assigned to the cLsass variable.
If we keep following the code after the OpenProcess call, we find another if statement where it validates that hData is valid. Assuming that the call to OpenProcess succeeded, then it would be. This means the subsequent line would be executed where the kull_m_memory_open function is called. Notice the three parameters that are being passed to it. Type is the variable set (line 178) to KULL_M_MEMORY_TYPE_PROCESS, hData is the output of OpenProcess, which is a process handle to LSASS, and cLsass.hLsassMem is the value that is being used to determine which case we choose in the switch statement we are exploring.
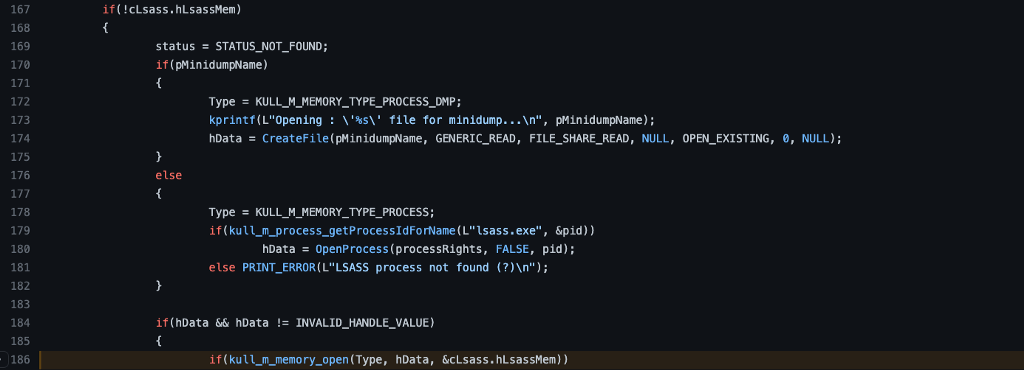
We can now investigate the kull_m_memory_open function to see what it does with its parameters. In the function, we see that the third parameter passed in as cLsass is now called *hMemory. We first see (line 17) that (*hMemory)->type, otherwise known as cLsass->type in the calling function, is set to the Type parameter.
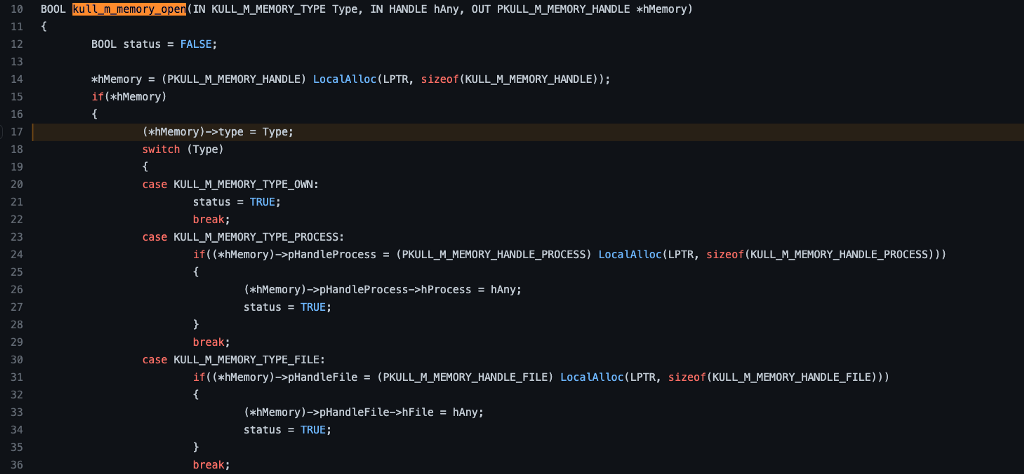
Next, we encounter a switch statement based on the first parameter, Type. We know from the calling function that Type is set as KULL_M_MEMORY_TYPE_PROCESS, so we can see that the code would select the second case.
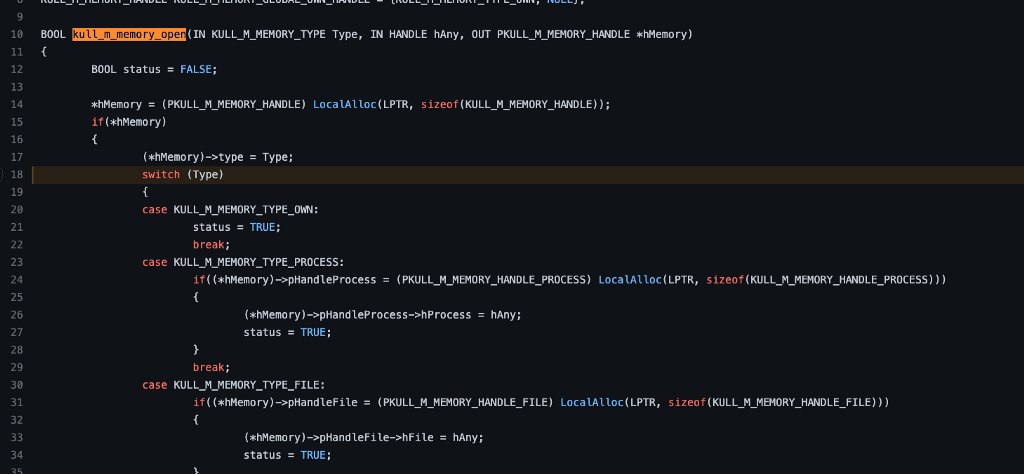
Before we start analyzing the code, it is essential to understand that the name of the parameter, when passed in from the calling function, does not necessarily correspond with the name of the parameter in the called function. For instance, in the calling function, kuhl_m_sekurlsa_acquireLSA, the second parameter is called hData, but in the called function, kull_m_memory_open, the second parameter is called hAny. Similarly, the kuhl_m_sekurlsa_acquireLSA function’s third parameter was a pointer to cLsass, but in kull_m_memory_open, it is referred to as *hMemory.
In the code, we see (line 26) that hAny is assigned to (*hMemory)->pHandleProcess->hProcess. This means that cLsass->Type is KULL_M_MEMORY_TYPE_PROCESS and that cLsass->pHandleProcess-hProcess is the handle generated from the OpenProcess API call.
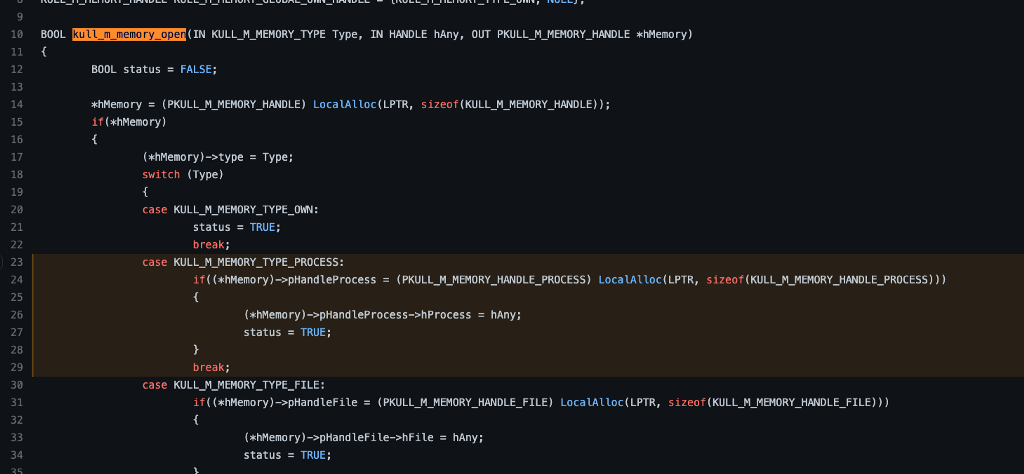
Finally, we have determined that the value of Source->hMemory->type is KULL_M_MEMORY_TYPE_PROCESS which means we can see that the code will follow the second case as highlighted in the image below. From here, the code is relatively straightforward as we see a call to the Windows API function ReadProcessMemory, which is used to read the memory of the LSASS process from the source address (as you could probably figure out from the function’s name).
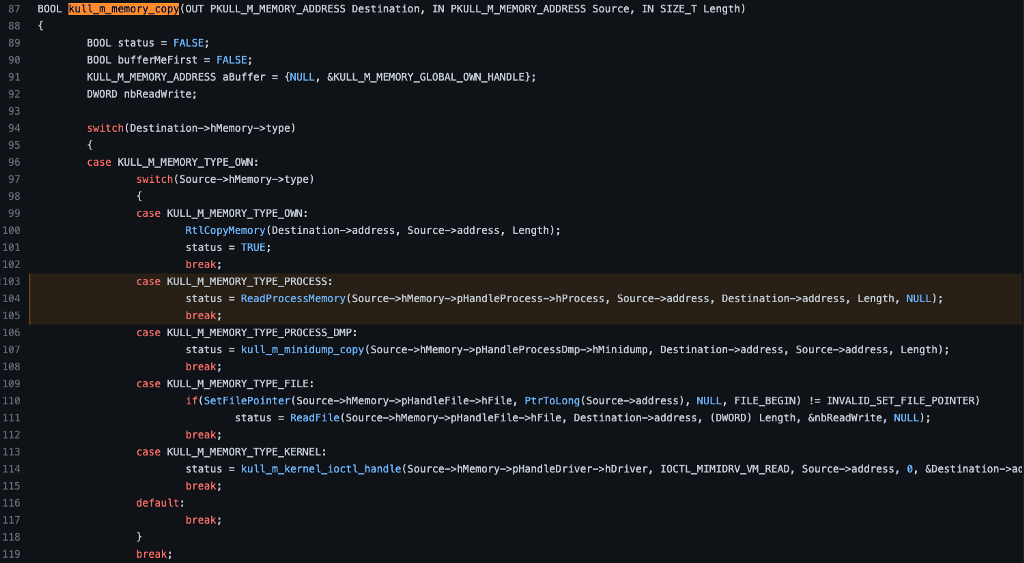
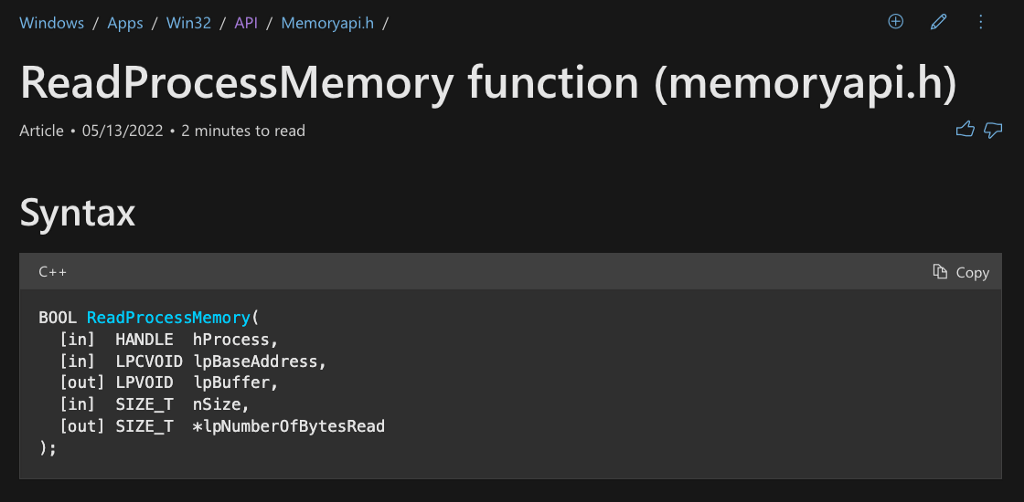
As with the previous two function calls, we can check the Microsoft documentation for ReadProcessMemory to understand how it is used and what it does when called. This represents the end of our analysis today, where we discovered that Mimikatz’s sekurlsa::logonPasswords command uses the ReadProcessMemory Windows API function to access the contents of LSASS’s process memory and access the target credentials.
Conclusion
After analyzing Mimikatz’ sekurlsa::logonPasswords command we found that it is generally calling three Windows API functions: NtQuerySystemInformation to get the process identifier (PID) for the LSASS process, OpenProcess to open a read handle to LSASS, and ReadProcessMemory to read the contents of LSASS memory where presumably the credentials that are being dumped are stored. To show the relationship between these calls I created a graph below:
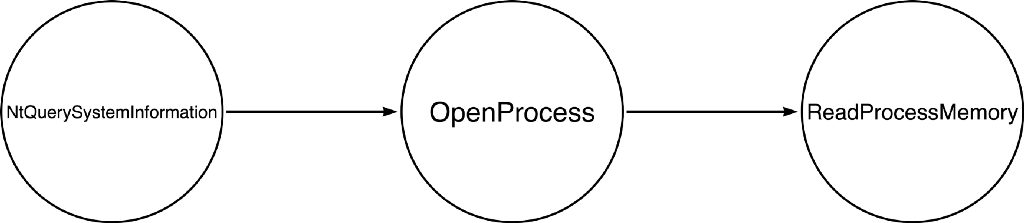
We can now follow the process described in my Understanding the Function Call Stack post to dig into each of these function calls. An interesting side effect is that we can see that these function calls are intertwined in the sense that the output of the first call is required as an input to the second call, and the result from the second call is required as an input to the third call. This means that the sequence of functions is potentially as interesting as the individual functions themselves.
When I first started in information security (before I actually understood how API functions work), it was common to hear people describe a pattern indicative of “process injection.” The pattern was VirtualAllocEx, WriteProcessMemory, and CreateRemoteThread (interestingly, they don’t mention OpenProcess because that is needed as an input for all three), and we were often told that if you see this pattern, then you are witnessing Process Injection: Dynamic-link Library. We’ve established at least one pattern that might be commonly seen in OS Credential Dumping — Lsass Memory type behavior (NtQuerySystemInformation, OpenProcess, ReadProcessMemory). Still, we should not assume that every instance of this pattern IS credential dumping or that this is the ONLY valid pattern of credential dumping. Can you think of any other function combinations that might be indicative of credential dumping? We will explore the answer to this question in the next post!
On Detection: Tactical to Functional was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.