DeepPass — Finding Passwords With Deep Learning
DeepPass — Finding Passwords With Deep Learning
One of the routine tasks operators regularly encounter on most engagements is data mining. While exactly what operators are after varies from environment to environment, there is one common target that everyone’s always interested in: passwords.
After diving into machine learning from an adversarial perspective I started to pay attention to any offensive security problems that could be augmented with ML. In one of my previous posts, I mentioned the differentiation between Adversarial Machine Learning and Offensive Machine Learning– Will Pearce defines Adversarial ML as the “Subdiscipline that specifically attacks ML algorithms” and Offensive ML as the “Application of ML to offensive security problems” and I agree with these definitions. My previous posts covered an introduction to adversarial ML, where we crafted adversarial samples to evade target existing models. Offensive ML includes things like sandbox detection, augmenting password guessing attacks, or improving spear phishing. In this post, we’re going to try to tackle password recognition.
We’re obviously not the first people to think of this. Two years ago Tom Kallo from Hunnic Cyber released a post titled, “Password Hunting with Machine Learning in Active Directory” and an associated tool called SharpML. Their approach was an interesting one, summarized by their graphic:
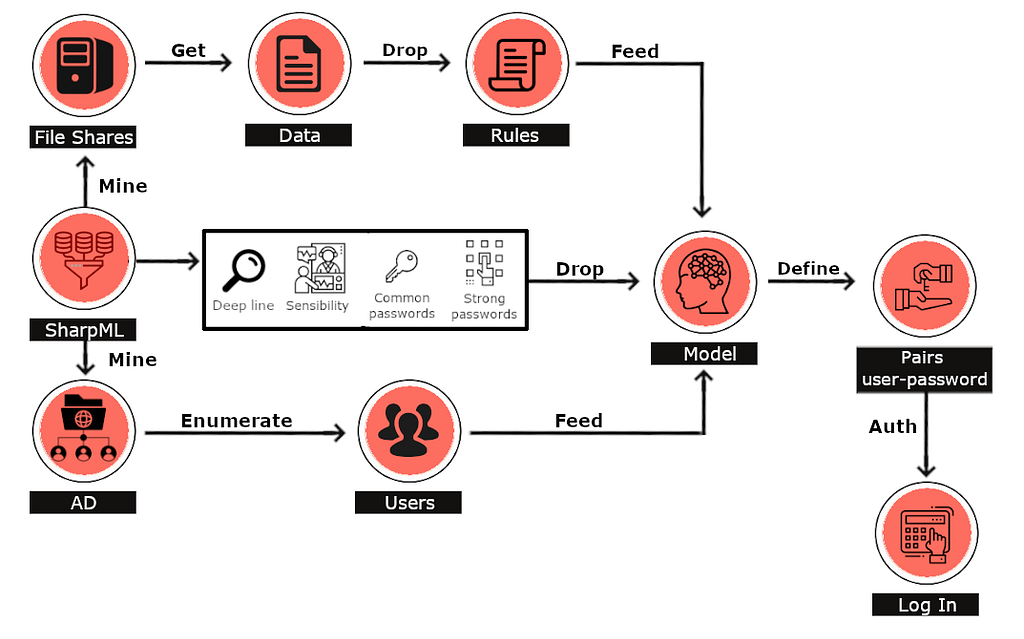
While the post states, “We will also be seperately [sic] releasing the un-compiled Machine Learning model and rules for you to play with, which will be similarly hosted on Github.” as of the writing of this post that hasn’t yet occurred. Without knowing what the model’s architecture, performance metrics, or exactly how it was trained (though my guess based on the repo is that it utilized 10k leaked passwords), I wanted to recreate a password recognition model and provide as much detail as possible. I also wanted to avoid the live password verification component, so this means I didn’t have to worry about transporting and executing the model on an arbitrary host in a target environment.
Full note upfront: this model is not perfect, and I’ll be explaining its shortcomings as we go. There’s actually a StackExchange post on some of these difficulties, including a topic we’re going to talk about here, “…the tricky part is figuring out how to get decent training data at sufficient volume.”

The Jupyter notebook and Dockerized model are not publicly available in the DeepPass GitHub repository.
The Problem
A lot of things in machine learning are easier said than done. When I started learning this discipline, the mystery of ML felt similar to when I started learning offensive security: I thought anything was possible. Now I still believe that anything is possible, but some things are definitely more possible than others.
So what’s the exact problem we want to tackle here?
Our operators download a larger number of documents on most engagements, whether through an agent or through various sites like Sharepoint. Reading through a large amount of text searching for specific key words or things like look like passwords is time consuming and something that machine learning could possibly help with (note, I didn’t say “solve” ; )
I’m going to skip over the topic of auto-ingestion here, and will focus on how to build an abstracted API that we can submit an arbitrary document to and receive password candidates back. Architecture-wise this is a common deployment scenario for ML models, and I’ll cover the Dockerized implementation in a later section.
Our API needs to:
- Accept documents of various data types (.docx, .pdf, .pptx, etc.)
- Extract plaintext words (often known as tokens in machine learning lingo) from each document type
- Run the extracted text through some type of machine learning model
- Return password “candidates” from the model results along with a bit of surrounding context
Before we start building and training, once again there’s an elephant in the room mentioned in the StackExchange post: how do we get good training data?
The Problem of Data
When we manually triage documents as humans we bring a wealth of experience and internalized pattern recognition to bear. Anyone who’s performed offensive operations can look at any number of documents and easily identify if a password is present. Consider the following sentences:
- In order to login, use the following password: Password123!
- We’ve reset your credentials to ‘ChangeMePlz?’, please change this at some point in the future.
- The creds for the database are user:Qwerty123456.
Obviously there is almost always a good amount of juicy context surrounding a password in a document that holds up a big red “PASSWORD!” flag to us when doing document triage. However, if we wanted to train a predictive model for that specific problem set we need labeled data, and a good amount of it, if we’re not just doing a basic regex-style search. That means we need a large number of documents similar to what we would encounter in the field where we know a subset has passwords within them and we know a subset has no passwords at all. We don’t preserve client data past reporting, and I don’t know of any public document corpus that satisfies these requirements.

There are few things more frustrating in ML than believing you could solve a problem if you just had the right (non-existent) dataset.
So my approach was an idea for the next best, but not ideal, approach: I focused on differentiating passwords themselves from “regular” words. To reiterate, I know that this isn’t perfect but it was the best approach I could think of given the constraints. The relative rarity of passwords in a document’s text also creates a class-imbalance problem that we’ll talk about tackling in later sections. In English: training a model to detect events that are relatively rare has its own unique set of challenges!
For an input dataset, I needed a large number of passwords and non-passwords. For passwords, I downloaded the “real human” password dump from CrackStation. I randomly selected 2,000,000 passwords that were between 7–32 characters to function as the known-password half of the dataset.
I then ran a large number of Google dorks to find technical/IT related documents of a number of different formats, ultimately gathering ~1,300 public “benign” documents. While there are possibly passwords contained within these documents, the normal text greatly outnumbers any possible outliers. I ran these documents through Apache Tika, an established toolkit that, “…detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF)” — I’ll also use Tika later in the model serving section. I selected 2,000,000 random words/tokens from this set for the known-word half of the dataset.
The Model
In my previous posts I detailed using a number of different model architectures for our tabular obfuscated PowerShell AST data set. I also mentioned that gradient boosted trees tend to outperform Neural Networks on tabular data. For text, specific types of Neural Networks generally outperform other approaches like Naive Bayes or N-Gram approaches, though this sometimes does depend on the amount of data you have. For this case, since we’re doing character tokenization of individual words instead of word tokenization of an entire document, I experimented with a variety of Neural Networks. This took a decent amount of time due to the 4,000,000 word dataset, so I wasn’t able to experiment quite as much as I would have liked. I’m confident that there is either a different architecture or a differently tuned approach that performs better than what I have here.
I tried a number of architectures, from stacked LSTMs to a variety of 1-Dimensional ConvNets (including multichannel variations). The best resulting architecture was a 200 node Bidirectional Long Short Term Memory (LSTM) network with a manual embedding layer and a bit of dropout:
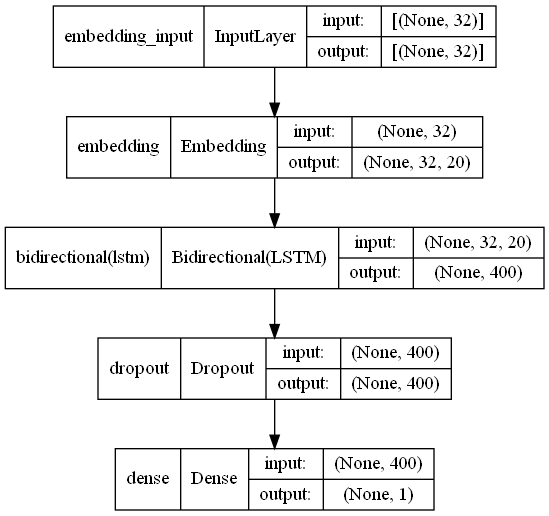
If this is you after reading the last few paragraphs, I’ll try to add some context:

There’s no way that I can fully explain token embedding for Neural Networks or the bidirectional LSTM architecture in this post, and I doubt many want me to. So I’ll provide a short, high-level explanation and some references in case you’re interested.
Text is sequential data. In a sentence, the sequence of words matter, and for a word (i.e., password) situation like we have here, the sequence of characters matter. We can’t treat sequences how we treated our tabular/matrix-type data, we need a different type of model. This is where LSTMs come in.
LSTMs are a special type of deep learning architecture called a recurrent neural network (RNN) which were designed to handle various types of sequence data. Neurons in a RNN have a loop that allows them to “remember” information about data in a sequence. LSTMs are an advanced RNN architecture that has proven to be very effective for text data, and was the de facto text architecture before transformers took over a few years ago. I specifically used a bidirectional LSTM which trains one LSTM running forward and one running backward on the input sequences. This helps us ensure we capture as much about the pattern of a password as possible.
- A detailed explanation of Long Short Term Memory networks (LSTMs)
- More information about bidirectional LSTMs
- More information on word embeddings
- More information on dropout
Nerd sidenote: “Why didn’t you use transformers??!” Well, I thought about it and played around a bit, but pretty much all transformer examples I found deal with word sequences and not character sequences. I’m also not completely convinced that neural attention is the best tool for word-length character sequences. However, let me reiterate my usual “i not an expert and don’t math too good” statement, and that I’m completely open to someone telling showing me I’m wrong!
For training, I also used a technique called Early Stopping to help prevent overfitting. Deep learning involves multiple “epochs”, where the entire data set is trained in batches that chunks all of the data to the model once per epoch. Early stopping is used to monitor specific performance metrics of the model during training and stops the training if performance doesn’t improve after a certain number of epochs. This helps preserve runaway overfitting.
So how did the model perform?

Pretty well actually, with almost 99% accuracy! However, this is still a big issue because of the ratio of rare events (like a word in a document being a password) thanks to our old friend the base rate fallacy. Let’s think about a simplified example to understand why.
Let’s say we download 100 documents that average 5000 words each, and 10 of those documents have a single password within them. That means among the 500,000 candidate words we’re going to process only 10 are passwords. Where does a 99% accuracy rate get us?
499,990 non-passwords * 99% accuracy = 494990 true negative non-passwords + 5000 false positive passwords
10 passwords * 99% accuracy = 0 false negative non-passwords, 10 true positive passwords
We likely will flag all of the passwords, but we’ll also have 5000 false positives! This is a big issue that’s similar to the false positive problem that plagues detection analysts. When a true positive is a relatively rare event in a large dataset, like a password in a document or real intrusion on a host in a large network, even very accurate models will produce a large number of false positives.

Often when training a model on rare events, the dataset itself is imbalanced. That is, the dataset would reflect the distribution of data in the real world, like the password frequency I described previously. There are various methods for handling imbalanced datasets, like upsampling/downsampling the class samples, data augmentation, etc. However in our case due to how we generated the dataset it’s perfectly balanced.
In order to deal with the false positive problem I had two ideas I experimented with. The first was changing the probability decision threshold for the model output. Our model, with its single Sigmoid output neuron, doesn’t output a hard label of “password” or “not password” but rather a probability that the input word is a password. Most of the time we use a threshold of 0.5 to decide the labels, with >=0.5 here signifying the input is a password. However we can manually adjust this, only returning results that have a higher, say 0.9, probability of being a password. One advantage here is that we can adjust the threshold multiple times after the model is trained.
The other option is to weight each class differently when training the model. This modifies the loss function to more heavily penalize incorrect classifications for a specific class, which can change the ratio of false positives or false negatives depending on how things are weighted. A disadvantage here is that once we train the model on the weighted classes, this can’t be changed like adjusting the threshold. However this ultimately outperformed the threshold option in this particular case, though we could possibly combine the approaches if wanted. The final model I trained used class weights of .9/.1 which penalized false positives more heavily. This is detailed in the ./notebooks/password_model_bilstm.ipynb notebook in the DeepPass repo.
For a final evaluation, I used the best performing early-stopping model on the test set to produce the performance metrics below. If you’re not familiar with the confusion matrix or validation/test sets, check out my introduction post on machine learning.
accuracy : 0.98997
precision : 0.99629
recall : 0.98358
F1 score. : 0.98990
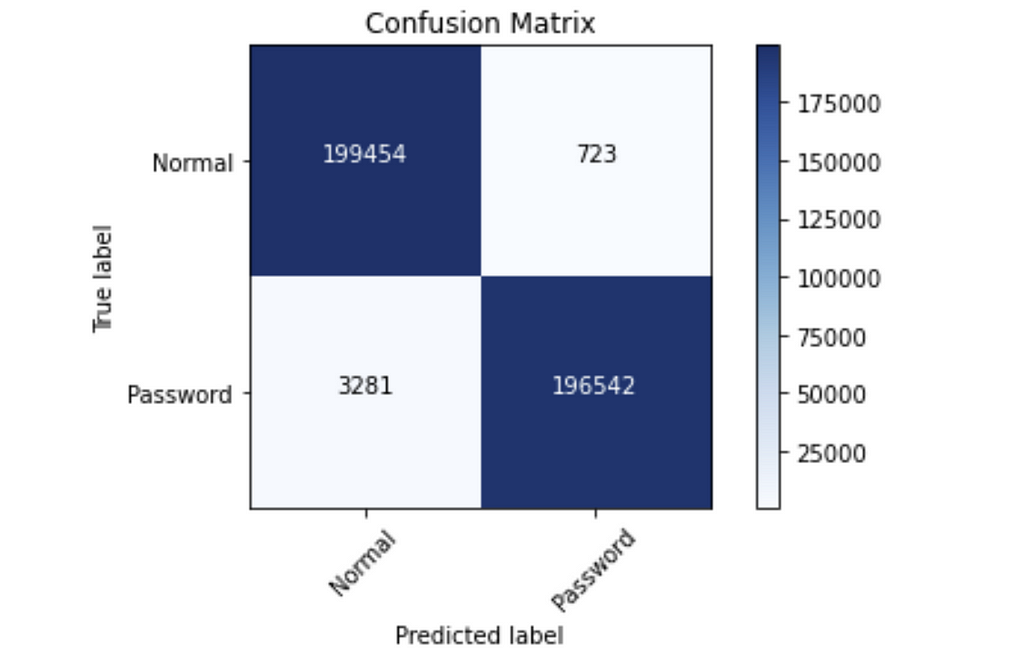
This is definitely more manageable, with 723 false positives out of 400,000 balanced input words. False positives and false negatives are intrinsically linked, and reducing one will increase the other. Using class weighting to reduce false positives here means that false negatives, or potential passwords we miss, will increase! However I felt that this tradeoff was necessary for the approach to hope to be usable. I also gained even more empathy for defenders who have to triage a deluge of alerts every day : )
Model Deployment
OK, neat, we have a nifty Keras LSTM model that seems like it performs decently well for our task. How do we actually use this thing?

In keeping with our API design goal, I chose to use Docker to package everything together. Luckily for us, there’s an officially supported Apache Tika Docker Image we can use to replicate the text extraction step, and TensorFlow (the underlying fabric for the Keras Deep Learning framework we used) has an awesome project called TensorFlow Serving. TensorFlow Serving is a lightweight approach for serving up model functionality after training and has a nice Docker Image as well.
The final step is to create a small application to handle the input requests and call all of the pieces. Additionally, I wanted to provide the ability to supply custom regex terms to search through each document text as well, as well as providing a few words of surrounding context for each result. All of this code is properly dockerized and up in the DeepPass repo. Here’s how the (janky, I know) tiny front end proof-of-concept web app looks:
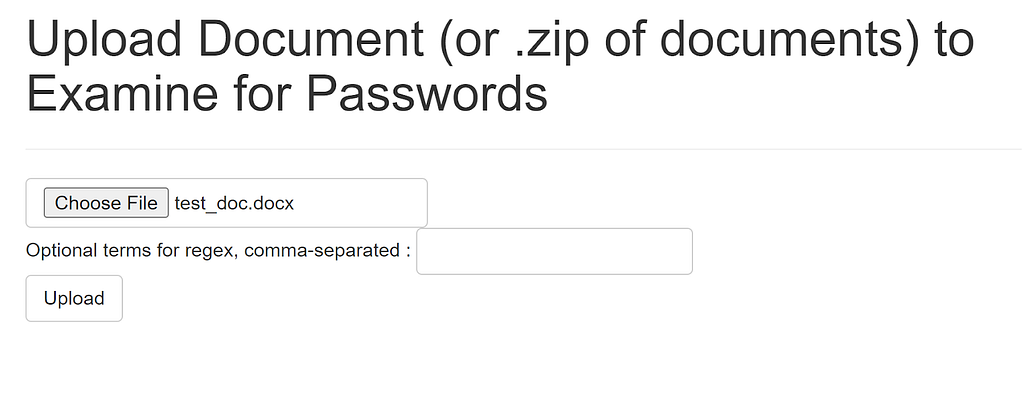
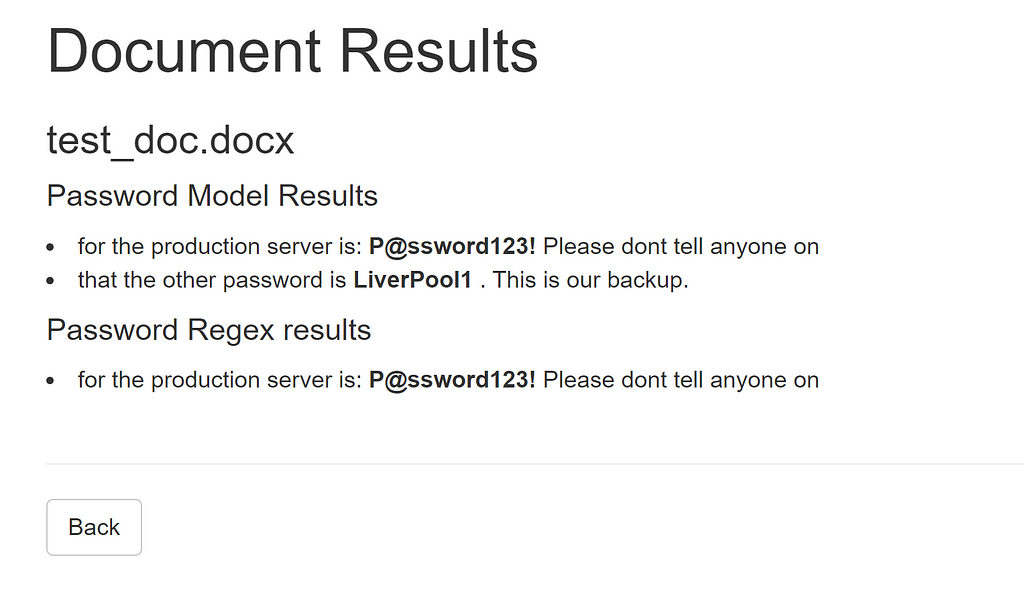
And here’s an example result:
The whole system can obviously be used as a straight API at http://localhost:5000/api/passwords
C:Usersharmj0yDocumentsGitHubDeepPass>curl -F “file=@test_doc.docx” http://localhost:5000/api/passwords
[{“file_name”: “test_doc.docx”, “model_password_candidates”: [{“left_context”: [“for”, “the”, “production”, “server”, “is:”], “password”: “P@ssword123!”, “right_context”: [“Please”, “dont”, “tell”, “anyone”, “on”]}, {“left_context”: [“that”, “the”, “other”, “password”, “is”], “password”: “LiverPool1”, “right_context”: [“.”, “This”, “is”, “our”, “backup.”]}], “regex_password_candidates”: [{“left_context”: [“for”, “the”, “production”, “server”, “is:”], “password”: “P@ssword123!”, “right_context”: [“Please”, “dont”, “tell”, “anyone”, “on”]}], “custom_regex_matches”: null}]
As a reminder, the file formats are what Apache Tika supports. Also, I previously mentioned the decision probability threshold- this can be adjusted in the app.py file on line 221 if wanted to further reduce false positives.
Conclusion
This is my first application of “offensive” machine learning and was an interesting project for me. I hope this was interesting to others and that the model is of use, even if it’s not perfect. I also hope that this might spark ideas in others regarding password detection during data mining. This effort definitely impressed upon me yet again that getting good quality, labeled data is usually the hardest part of any machine learning project.
If you’d like to retrain the model with a different dataset more tailored to your operations, the Jupyter notebook in the DeepPass repository should show you how. Just build a new dataset.csv with columns of “word”,”is_password”, retrain the model, save the model off, and substitute the model into the ./models/ section of the Docker project.
DeepPass — Finding Passwords With Deep Learning was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.