Hang Fire: Challenging our Mental Model of Initial Access
For as long as I’ve been working in security, initial access has generally looked the same. While there are high degrees of variation within each technique (i.e., payloads, pretexts, delivery mechanisms, obfuscations) used by most threat actors there is very little, if any, variation at different layers. This observation has grown into more of a concern for me as I’ve watched teams struggle to detect even slight variations to the expected flow. I began to dig into this issue more and wanted to share what I’ve found with you all.
When we think about initial access on both the offense and defense sides, we generally have an idea of what it should look like. An attacker sends their thing. A user clicks the thing. The thing goes boom. The attacker has a callback. This is a well-understood flow of events. It’s simulated in nearly every penetration test and red team, included in every threat intelligence report, and shows up in pretty graphs in our EDR dashboards. Detections of this behavior can generally be found in the form of “Internet connection made by atypical process” and “process X spawned abnormal child Y,” among many others.
On offense, we’ve been conditioned for instant gratification. When we phish, our success condition is if we get a callback. The payloads for our exploits are agent shellcode. We’ve been trained on this, and it has become standard practice at every place I’ve worked and with every group with which I have advised.
On defense, we’ve been conditioned to think that all initial access looks like this instant gratification. When a user falls victim to a phish, we look for odd child processes, network connections, and other suspicious activity associated with the host process (e.g., WINWORD.EXE for document-based phish). What would you do if a user reported a phish that you investigate to find none of the previously listed conditions?
This is no one’s fault. We’re responding to an effective stimulus. We see adversaries using this technique with great deals of success, so we build detections for it. We seek to emulate it. We build processes around it. We build biases towards it.
Let’s use the following scenario as our example: say that you know that your target organization makes use of Microsoft Teams. Your first thought may be to create some pretext built around Teams that you’ll fit a payload to in order to get access. Maybe you even send your target the lure over Teams as an attachment (side note: why can any outside user message any user on Teams by default?). They open your attachment, and your agent runs as a child process of Teams, calling back out to your infrastructure. You’ve probably either pulled this off or seen it in the environment you defend countless times. The standard detection risks apply:
- Abnormal child process of Teams
- Abnormal network connection from the suspicious child process
- Evidence of remote process injection
- Shellcode in the child process
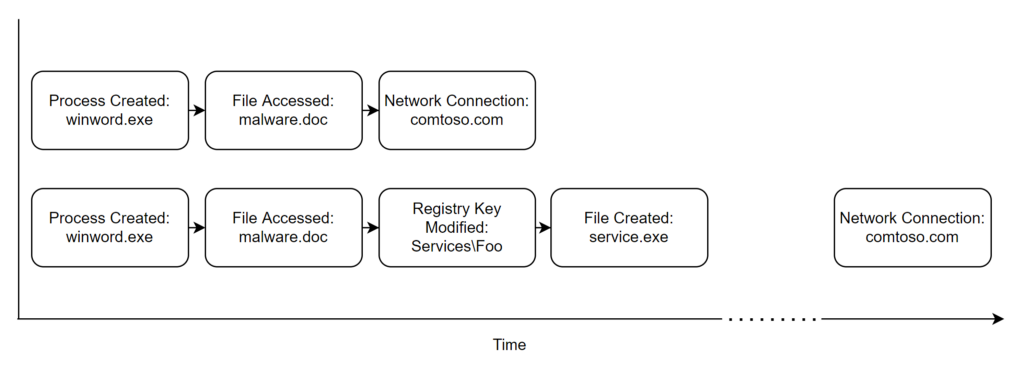
What happens if we change things up a little bit? An approach, which is by no means novel, that we’ve seen great success with over the past year is phishing for persistence instead of access. Say you happen to know that there is a DLL hijack in Teams. Instead of going through the process of building a payload which will execute your shellcode, you instead build something that simply drops your DLL into the appropriate location. You send this to the target who again falls victim to it, but instead there are much different indicators:
- Teams writing a DLL to disk
- Malicious code in the DLL
The next time Teams is restarted, the DLL will be loaded, and you get a callback. The same objective of access has been achieved, just without the instant “click-bang” gratification and the indicators of compromise that are inherent to those techniques. Because we may have biases when responding to an endpoint compromise, this delay may break our mental model of what successful phishing looks like.
Furthermore, this situation creates a delay between action and outcome — a hang fire of sorts. If our detection models are built around a series of activities that should happen within five minutes of each other, what happens if an attacker draws that out to five hours? Does this break alert logic?
The DLL hijack is just one example of what is possible, and the options are nearly limitless. Despite this, there may still be some concerns. How will you know if your phish landed if you don’t have an direct indication that it did? What if we need access as fast as possible and don’t have time to wait around? What if we don’t have the resources to find these techniques? These are valid issues, but I have absolutely no doubt that we can solve them. For example, can we send a message to our infrastructure telling us that persistence was dropped without having to establish full C2 with the host? In situations where we need access fast, are there techniques available that could execute more frequently? If we don’t have the resources to invest into R&D, can we adapt what we have we been doing for all of our more traditional payloads?
If you’re on the offense side, I challenge you to come up with an alternative payload that establishes persistence instead of immediately executing an agent. If you’re a defender, I challenge you to look at your playbooks and personal thought processes to see if you have a bias towards initial access that is centered around the host process running the malware.
If we always do what we’ve always done, we’ll always get what we’ve always gotten.
Hang Fire: Challenging our Mental Model of Initial Access was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.