Part 4: Compound Functions
Introduction
Welcome back to the On Detection: Tactical to Functional series (links to all posts are at the bottom of the post). Thus far, we’ve explored the OS Credential Dumping: LSASS Memory sub-technique, specifically mimikatz, as an example to understand how this sub-technique works. The first post focused on identifying the API functions that the mimikatz’ sekurlsa::logonPasswords command uses to achieve its desired outcome. Functions are essential because they are the building blocks of functionality within the operating system. The second post introduced the concept of Operations, which act as abstract categories used to group similar functions based on their teleological outcome. Suppose I can replace one function with another, like how a developer can replace OpenProcess with NtOpenProcess. In that case, those functions perform the same Operation (Process Access in this case). The third post built on a concept I wrote about before starting this series in a post called Understanding the Function Call Stack. The idea was that documented API functions are, in fact, wrappers around the actual functionality. When we call a function like ReadProcessMemory, many functions are called before the operation is complete. This sequence of functions builds the “function call path.” In the third post, we explored how we can generate a new function call path and integrate it with other existing function call paths for the same operation, which results in the generation of a “function call graph.” The graph allows us to evaluate all of the different functional options, at least those known to us, that a developer can use to achieve an Operation.
This post is a slight detour, but it is essential nonetheless. This blog series is working to connect the Tactical to the Functional through a coherent taxonomy. Still, sometimes we make observations and build assumptions based on them only to find that our perspective was too low resolution to apply coherently to the range of implementations we should consider. This post discusses one such example.
As I alluded to earlier, the second post introduced the idea of functions. One of the fundamental axiomatic presuppositions I made was that every function represents one and only one Operation. As I continued my research of OS Credential Dumping: LSASS Memory and the building of the relevant function call graphs, I ran into some functions that contradicted this axiom. I want to use this post to show the example I ran into, explain how it works, provide language we can use to discuss it, and describe how I’ve adjusted the taxonomy to account for this phenomenon.
Revisiting ReadProcessMemory
The first article in this series analyzed the Mimikatz source code to find that it relies on a call to kernel32!ReadProcessMemory. It is then possible to use the methodology discussed in the Understanding the Function Call Stack post to generate the function call path for kernel32!ReadProcessMemory. If an application makes a call to kernel32!ReadProcessMemory, it will subsequently call api-ms-win-core-memory-l1–1–0!ReadProcessMemory, then kernelbase!ReadProcessMemory, then ntdll!NtReadVirtualMemory, and finally transition execution to the kernel via the NtReadVirtualMemory associated syscall. I thought this function call path was representative of normal functional behavior. It is quite straightforward, and execution passes from each function in the path without any detours, as shown in the graph below.

Introducing Toolhelp32ReadProcessMemory
As the Understanding the Function Call Stack post mentioned, one of the first steps during analysis is to open the implementing DLL and search the exports table for a reference to the function of interest. This search ultimately leads to the function’s code implementation, which helps us to understand how the function works. Upon searching for ReadProcessMemory in kernel32.dll, I stumbled upon a second, similarly named function called Toolhelp32ReadProcessMemory, which piqued my interest.
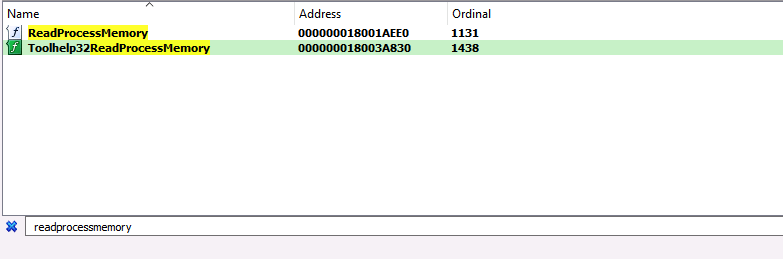
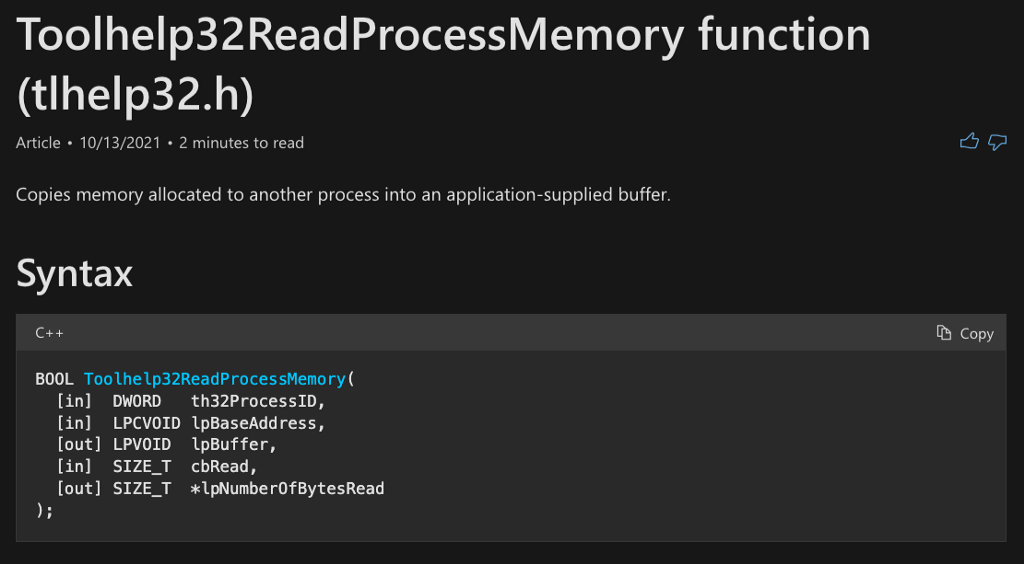
According to the Toolhelp32ReadProcessMemory function’s documentation, it acts similarly to ReadProcessMemory, but with one exception. ReadProcessMemory requires a handle to the process from which to read, while Toolhelp32ReadProcessMemory only requires the process identifier (th32ProcessID). It appears that Toolhelp32ReadProcessMemory is functionally equivalent to ReadProcessMemory, but may be easier to use or at least potentially allow for bypassing that pesky Process Access operation required for ReadProcessMemory. Skipping the Process Access operation would be useful for attackers because the vast majority of detection rules for this technique target this operation specifically.
If we open the function in IDA, we can see that Toolhelp32ReadProcessMemory actually calls ReadProcessMemory for us. It seems like it might just be another layer of wrapper code to add to our function call graph.
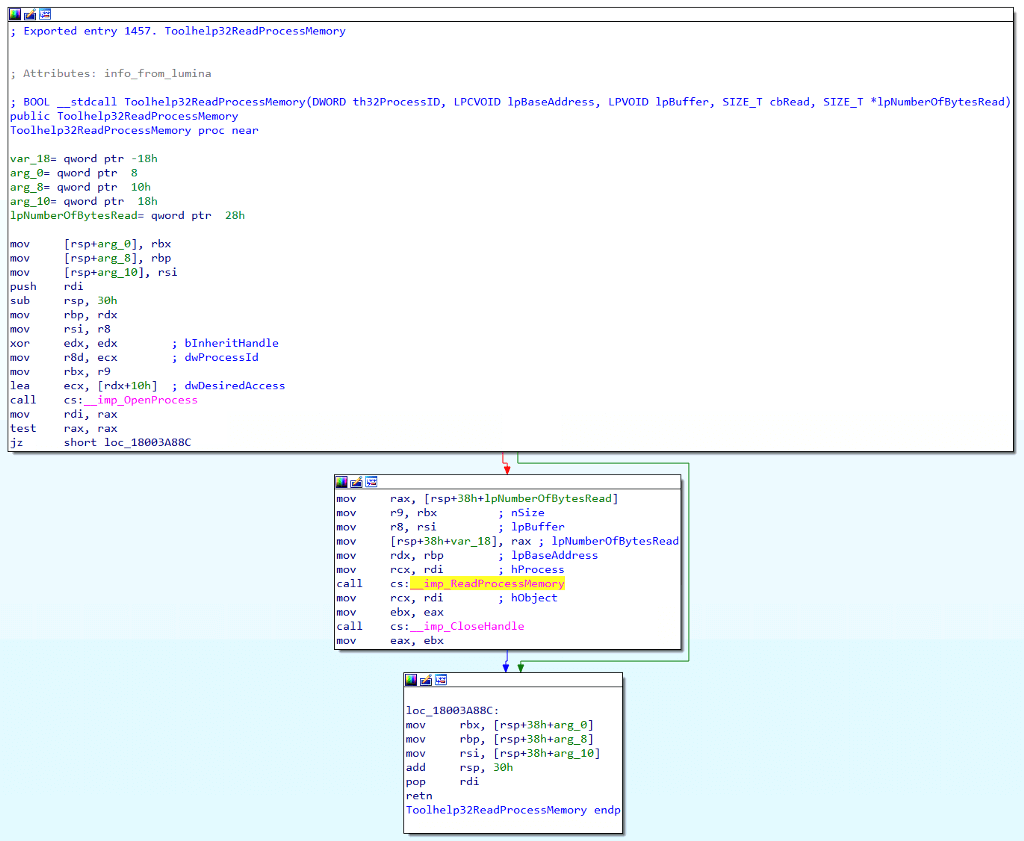
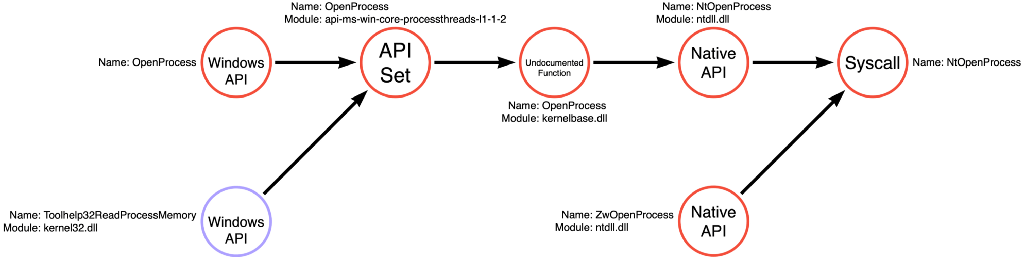
It is possible to find the exact version of ReadProcessMemory used by consulting kernel32.dll’s import table. It appears that Toolhelp32ReadProcessMemory calls api-ms-win-core-memory-l1–1–2!ReadProcessMemory.
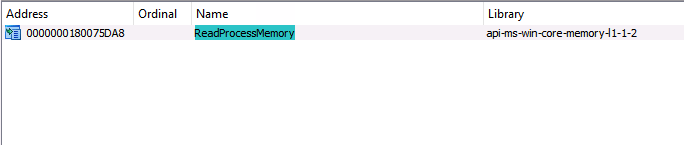
Recall that part 2 of this series introduced a new Operational abstraction layer that allows us to group functions teleologically (based on the functions’ ends, goals, purposes, or objectives). For example, ReadProcessMemory falls under the Process Read operation because it is responsible for allowing an application to read the volatile memory of a process. Meanwhile, in part 3, we demonstrated how we could combine multiple individual function call paths for a given operation to form a function call graph that is aligned to the operation and describes all known functional options to execute the particular operation.
My first thought was that we could add Toolhelp32ReadProcessMemory to the ReadProcessMemory function call path earlier to produce a function call graph for the Process Read operation.
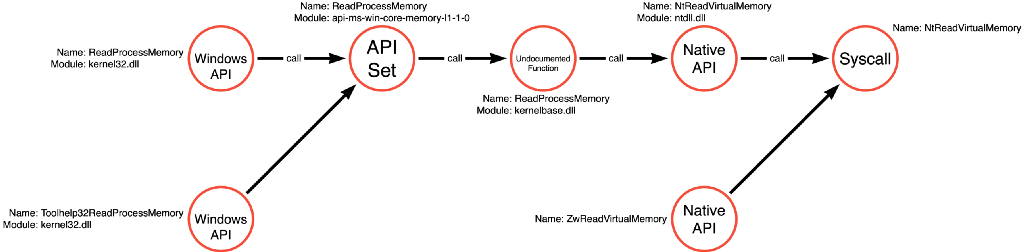
While this seemed like a simple enough solution, it bothered me because something seemed off. Toolhelp32ReadProcessMemory wasn’t as simple of a function ReadProcessMemory. While it is true that it calls the API Set version of ReadProcessMemory, that isn’t everything it does. Remember when we observed that Toolhelp32ReadProcessMemory only required a process identifier instead of a process handle, and we thought that maybe we could skip the Process Access operation altogether? If we look again closely, this time at the code produced by IDA’s decompiler, we see that Toolhelp32ReadProcessMemory doesn’t ONLY call ReadProcessMemory. It calls OpenProcess, ReadProcessMemory, and CloseHandle.
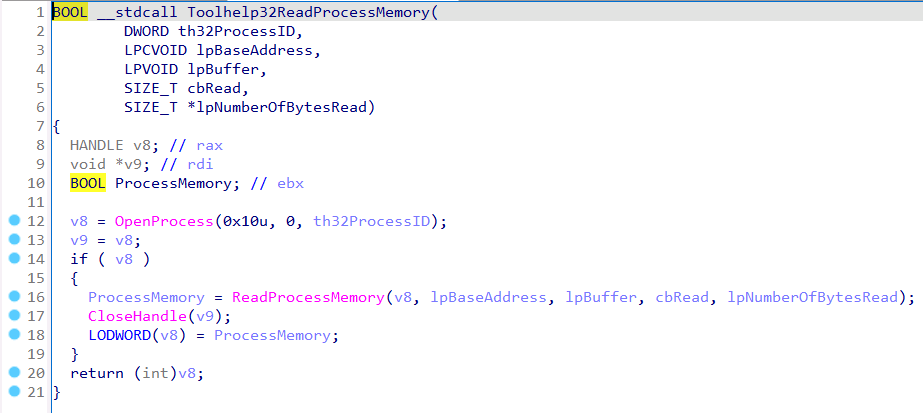
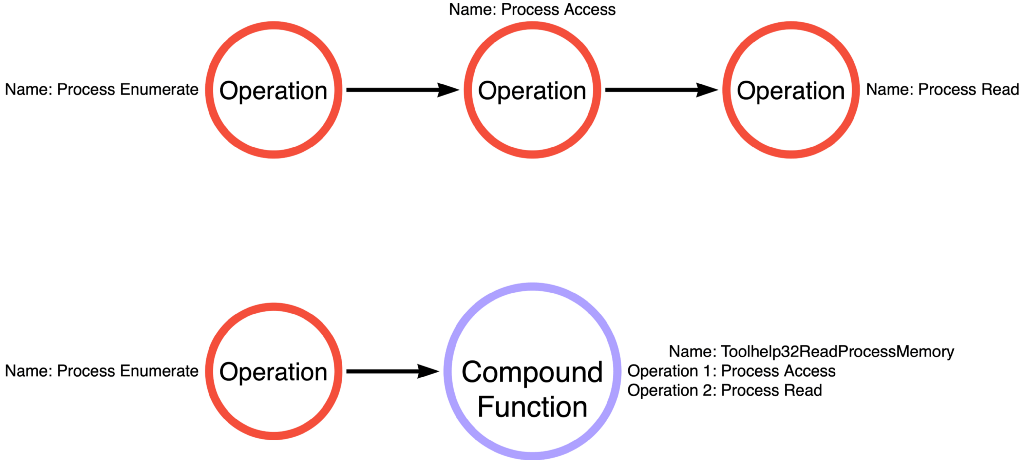
Toolhelp32ReadProcessMemory is a single function that performs multiple (3) operations. OpenProcess for the Process Access operation, ReadProcessMemory for the Process Read operation, and CloseHandle for the Handle Close operation. While kernel32!ReadProcessMemory follows a straightforward function call path, which isn’t ALWAYS the case. Some functions, like Toolhelp32ReadProcessMemory, actually act as miniature self-contained applications. I’ve started referring to these multi-operational functions, like Toolhelp32ReadProcessMemory, as “compound functions” while referring to single-operational functions, like ReadProcessMemory, as “simple functions”.
Toolhelp32ReadProcessMemory presents a conundrum for our graphing efforts. While it is true that it performs the Process Read operation and therefore should be included in the Process Read function call graph, it also belongs in the Process Read and Handle Close function call graphs.
The problem is that this function is no longer atomic, meaning it cannot be mixed and matched with other functional implementations of a given operation. Suppose an application chooses to use NtReadVirtualMemory for the Process Read operation. In that case, the application can generally select to pair NtReadVirtualMemory with any simple function in the Process Access graph. This pairing ability is not the case with Toolhelp32ReadProcessMemory. Applications that use this compound function are, in essence, locked into using OpenProcess and ReadProcessMemory.
Visualizing Compound Functions
Understanding how compound functions work within function call graphs and operations, I’ve created two ways to visualize these functions. The first is to view the function atomically in what I call the “compound function graph,” and the second is to view it within the context of the relevant operations’ function call graphs.
Compound Function Graph
The compound function graph is an interesting way to understand how a compound function works. The compound function is on the left side of the graph, and its node is colored purple. We then see arrows originating with the compound function and pointing to yellow nodes, representing the compound function’s operations. We see Process Access, Process Read, and Handle Close in this case. Then we see that each operation node points to the entry point into the relevant operation’s function call graph and shows the subsequent function calls made. For instance, Toolhelp32ReadProcessMemory calls api-ms-win-core-processesthreads-l1–1–2!OpenProcess to implement the Process Access operation. The compound function graph is useful for getting the full picture of how an individual compound function works.
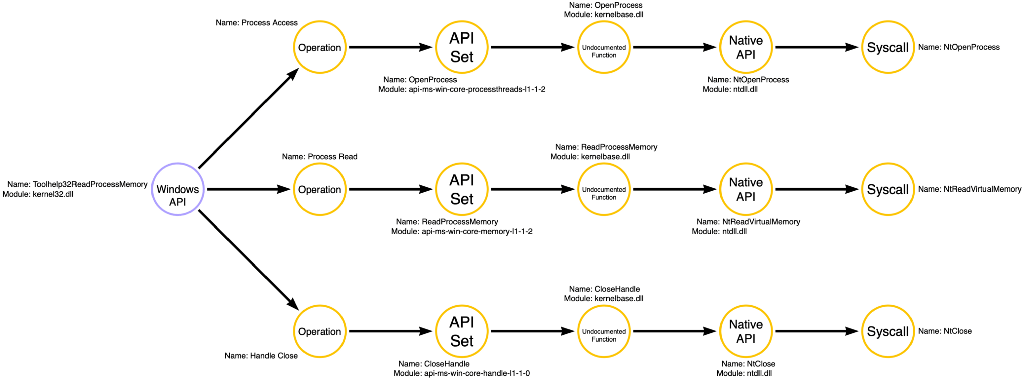
Combined Graph
The second way to visualize compound functions is to integrate them into the relevant operations’ function call graph. For instance, the function call graph for the Process Read operation below includes the Toolhelp32ReadProcessMemory compound function. This time, however, the compound function’s node is purple to indicate that it is a compound function and therefore cannot be used atomically like the other functions with red-colored nodes.
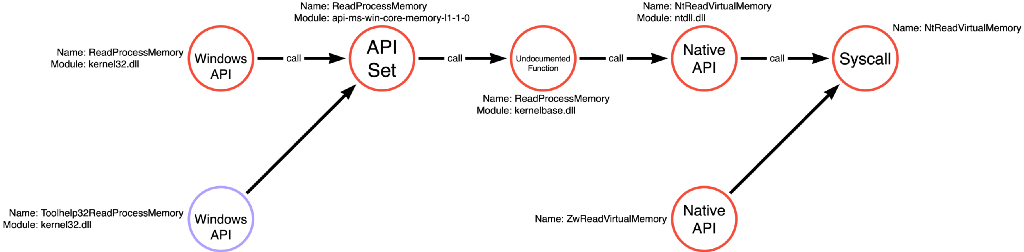
I’ve also included the function call graph for the Process Access operation to demonstrate that we should add compound functions to all relevant operations’ function call graphs.
Remember that the Operational Graph we created for mimikatz sekurlsa::logonPasswords was Process Enumerate -> Process Access -> Process Read, but Toolhelp32ReadProcessMemory allows that to be collapsed into Process Enumerate -> Toolhelp32ReadProcessMemory as shown below:
Additional Example
I thought it’d be helpful to include a second example of a compound function. A technique that I’ve been interested in for a while is Access Token Manipulation. Robby Winchester and I initially presented about Access Token Manipulation at Black Hat Europe in 2017 and subsequently released a white paper on that topic. The paper identified three categories of token theft that are now classified as sub-techniques in MITRE ATT&CK for the Access Token Manipulation Technique (Token Impersonation/Theft, Create Process with Token, and Make and Impersonate Token). Access Token Manipulation is a technique that the industry seems to have a decent understanding of, and yet we keep refining that understanding over time. Some great examples are Justin Bui and Jonathan Johnson’s work (here and here).
SetThreadToken vs. ImpersonateLoggedOnUser
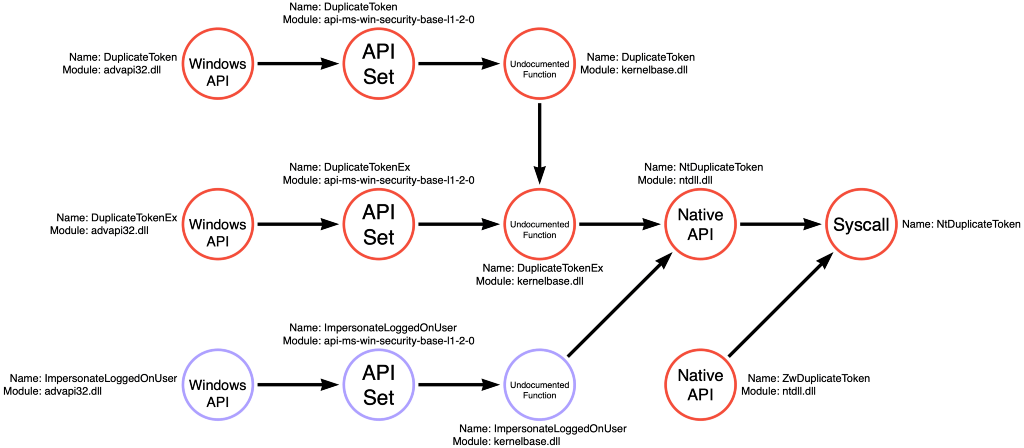
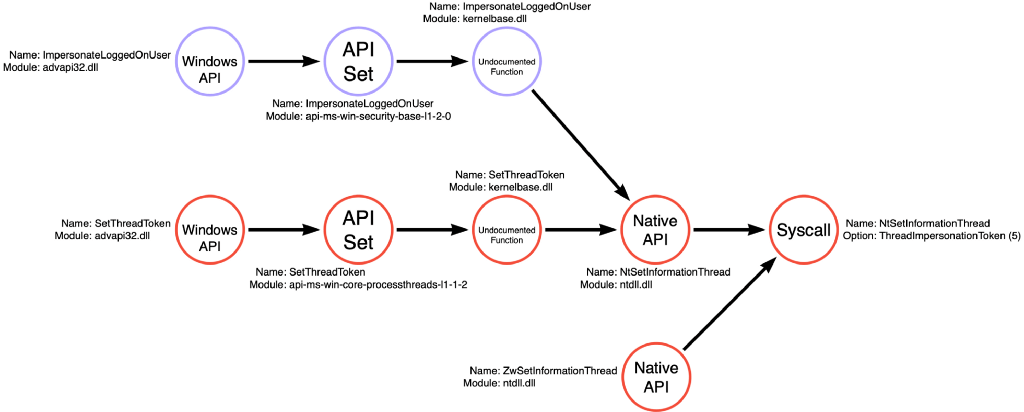
I recently looked back into this technique to build function call graphs, and I rediscovered an interesting divergent use case that seems germane to this article. Applications can choose between two functions to apply an impersonation token to the current thread. The first is SetThreadToken, and the second is ImpersonateLoggedOnUser. Justin Bui previously spent some time investigating the relevant API functions to perform SYSTEM token theft (think of meterpreter’s getsystem command), so I asked him about the difference. In our conversation, one of the significant differences between the two functions was that applications must first create a duplicate copy of the target token before calling SetThreadToken. At the same time, ImpersonateLoggedOnUser does not require this step. This difference seemed to make ImpersonateLoggedOnUser advantageous, but does that change when we look into their code implementation?
Below is the function call path followed by SetThreadToken. Like ReadProcessMemory or OpenProcess, SetThreadToken is a simple function that only performs a single operation, Thread Write (it writes the desired token to the thread using NtSetInformationThread).
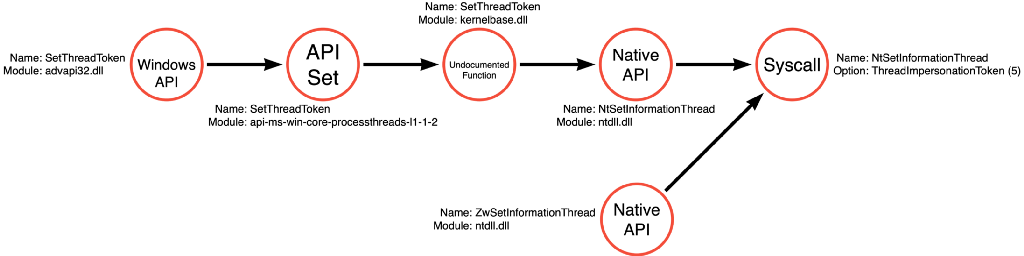
Upon investigating ImpersonateLoggedOnUser, we see a slightly different and more complicated picture. It turns out that ImpersonateLoggedOnUser is a compound function that again performs three operations, Token Read (getting information about the token itself), Token Copy (creating a duplicate copy of the target token), and Thread Write (applying the token to the target thread). We see that it isn’t entirely true that ImpersonateLoggedOnUser doesn’t require a duplicated token. Instead, it performs the duplication implicitly via NtDuplicateToken.
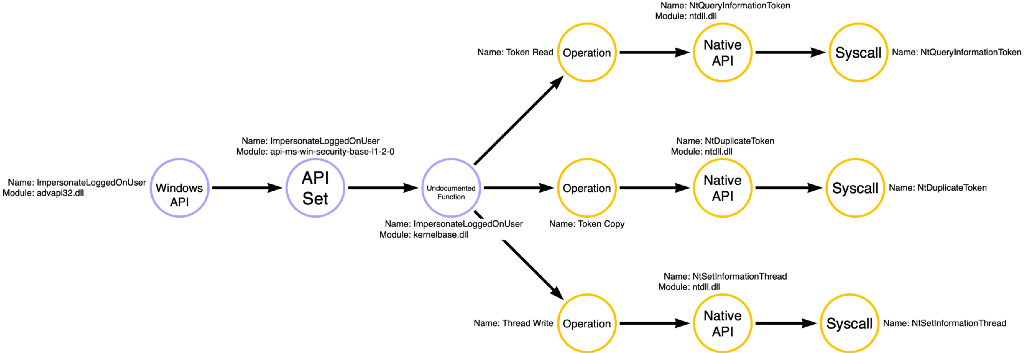
Above we saw the compound function graph for ImpersonateLoggedOnUser. Still, we can see how this compound function integrates into the function call graph for both the Token Copy and Thread Write operations. One crucial detail I want you to notice is that this time there are three purple nodes instead of the one we saw with Toolhelp32ReadProcessMemory. ImpersonateLoggedOnUser has a similar layering structure to many of the simple functions we’ve seen. It has a documented function, an API Set, and an undocumented function component. The key is that applications can call any of these three functions, but all three will result in the compound result. As a result, I’ve included all three nodes in our function call graphs. However, all three nodes are colored purple to indicate their compound nature.
Conclusion
My goal with this work and this blog series is to explore the emergent taxonomy that seems to exist from Tactics down to Functions. As I explore and build layers and categories, I occasionally stumble upon some examples that don’t quite fit into the schema I’ve created. This discordance is a fantastic problem because it lets me expand or refine the schema to represent reality better or demonstrates that my schema has a fundamental error. In this case, compound functions challenged one axiomatic presupposition of my schema: that all functions perform a single operation. This axiom is demonstrably false, and I had to update how I viewed the world (the cyber world) to deal with this fact. It seems that categorizing functions as simple functions, those that perform one and only one operation, and compound functions, which act as miniature self-contained applications and perform multiple operations, works perfectly fine and is coherent with the rest of the schema (for now). Hopefully, this also helps you to understand, whether you are on the red or blue side, that there’s more to things than meets the eye, and just because you don’t explicitly call a function doesn’t mean you aren’t calling it implicitly. Please let me know what you think on Twitter or in the comments, and stay tuned for the next edition of the On Detection: Tactical to Functional series.
On Detection: Tactical to Functional Series
- Understanding the Function Call Graph
- Part 1: Discovering API Function Usage through Source Code Review
- Part 2: Operations
- Part 3: Expanding the Function Call Graph
On Detection: Tactical to Functional was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.