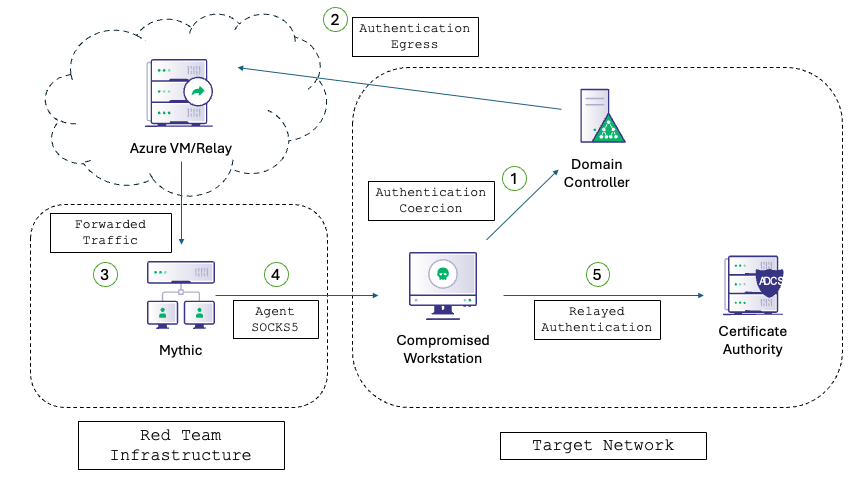
Automating Azure Abuse Research — Part 2
Automating Azure Abuse Research — Part 2
In Part 1 of this series, we looked at how to port functionality from the Azure GUI to PowerShell. Specifically, we looked at how to replicate the Azure GUI’s ability to run arbitrary commands on an Azure VM.
In this second and final part of this series, we are going to dive into the BloodHound Attack Research Kit (BARK). We will explain how the BloodHound Enterprise team uses BARK to perform so-called “continuous abuse primitive validation”. We will also explain how BARK can make your own Azure abuse research easier, faster, and more accurate.
The Problems We Are Trying To Solve
First of all, it is critical that administrators understand how to identify dangerous configurations in their Azure environments. Administrators demand and deserve more than empty statements about “best practice” — they need proof that configurations are actually abusable before we ask them to identify and remediate those configurations. Automobile manufacturers make cars safer by slamming them into walls during crash tests, understanding what went wrong, and improving that part of the car. We can make Azure safer with similar, less dramatic methods.
Problem #1: The Pace of Azure Service Expansion Exceeds Security Research Capacity
Azure is a vast landscape of services, expanding with new services all the time. Admins need to understand how an adversary may abuse those services. But fully researching those services and how they can be abused has historically taken a very long time. Researchers can’t keep up with the pace of Azure’s expansion. This is bad for admins as they may unknowingly introduce and maintain extremely dangerous configurations in their environments.
Problem #2: Blind Trust of Documentation Leads to False Positives and Negatives
One of the most vital jobs of any security professional is identifying issues and making corresponding remediation recommendations. We are all intimately familiar with the frustrations that come with false positive findings, and most of us understand the danger of false negatives. But what’s less obvious is that consistently producing inaccurate findings and guidance will eventually degrade whatever trust you have earned to the point that people will simply stop listening to you. Users demand and deserve proof, not just your interpretation of documentation.
Problem #3: The Dynamic Mechanics and Outcomes of Azure IAM Systems Invalidate Prior Research
Those of us who focus on abuse research are used to dealing with highly static systems that, for the most part, don’t change all that much. The core mechanics of Active Directory’s various Identity and Access Management systems–the Security Reference Monitor, for example–basically work the same way they always have. Microsoft patches bugs, not misconfigurations.
Unlike how Microsoft issues software updates for Windows on “Patch Tuesdays,” Azure is constantly changing. According to AzAdvertizer there were 160 changes to Azure RBAC roles between August 2021 and August 2022. Those changes may be the addition of a new role, granting more privileges to an existing role, removing privileges from a role, or something else.
The Solution: Continuous Discovery and Validation of Abuse Primitives with BARK
BARK is the BloodHound Attack Research Kit. We released BARK as free and open source software on August 3, 2022, the same day we released BloodHound 4.2.
To solve the above three problems, BARK is designed to enable three outcomes:
Accelerate abuse research
Accurately model abusable configuration outcomes
Automate ongoing validation of original research
In the last blog post, we figured out how to use PowerShell to create a lightweight API client capable of running commands on Virtual Machines hosted in Azure. Critically, we did this without any third-party libraries and stayed within the confines of the PowerShell terminal — no annoying browser pop-ups to handle authentication. This means we can build automation on top of this basic function.
The first thing we need to do is create a BARK-compliant PowerShell function to test whether a supplied token has the ability to run a command on a VM. This function will take three inputs:
- TestToken — The AzureRM-scoped JWT we are using to submit the request.
- HeldPrivilege — The human-readable name of the privilege granted to the principal identified by the token.
- TimeOfTest — The date and time the test is being performed.
The function itself will attempt to use the supplied token to run a command on a specified Virtual Machine. Once the test is complete, the function will return the results of the test, including these values:
- AbuseTestType — The human-readable type of test, ex: “Run command on VM via runCommand endpoint”
- AbuseTestHeldPrivilege — The human-readable name of the privilege granted to the principal identified by the token.
- AbuseTestOutcome — “Success” if the token was able to run a command on the VM, “Failure” if not.
- AbuseTestDateTime — The date and time the test was performed.
- AbuseTestToken — The token that was used for the test. This is helpful for future troubleshooting if a test produced an outcome we did not expect.
This is the very basic design of each abuse test function. We can visualize it like this:
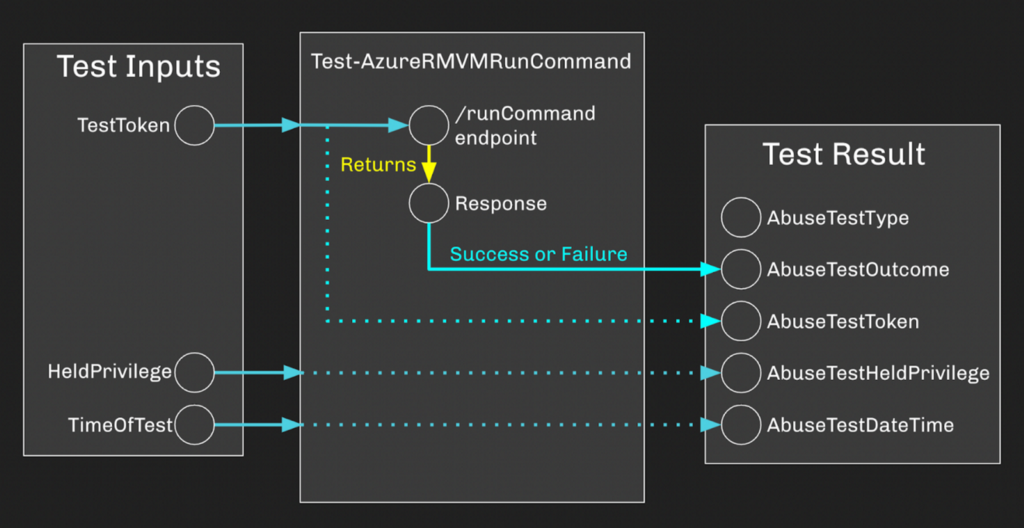
Nothing fancy. Basic. Easy. And that’s the point: we can easily take this basic structure and quickly build new tests when we discover new abuse primitives. More than that, though, we can completely automate this and start spinning up simultaneous threads to perform tests in parallel, and that’s what a function like Invoke-AzureRMAbuseTests does:
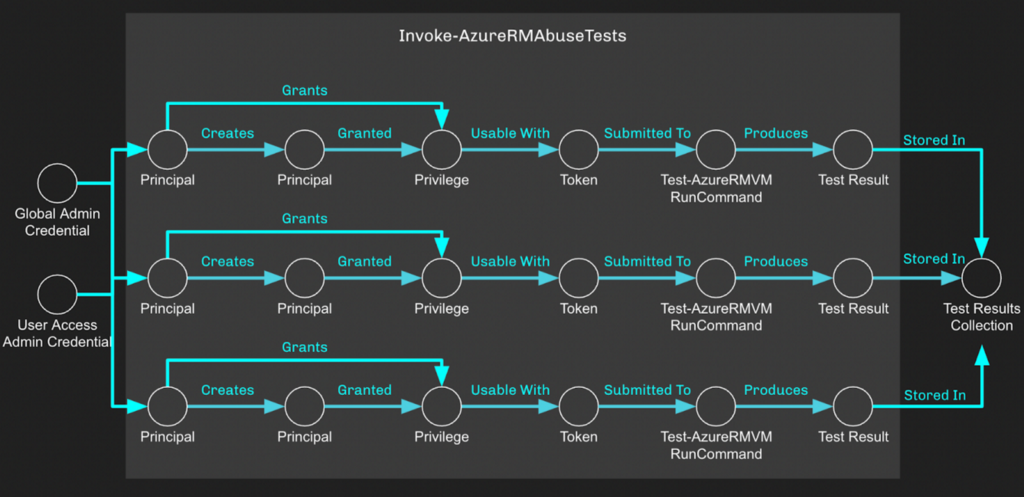
This function exists because when we are performing these tests, we need to ensure the token we are submitting holds precisely one privilege and no more. If the principal has more than one privilege, we can’t know which one was abusable and which one wasn’t.
Quick aside: it is possible that the combination of different privileges may combine to form an abusable scenario where the component privileges do not; however, the possible number of combinations of privileges greatly exceeds our practical ability to test.
With Invoke-AzureRMAbuseTests, we can run as many tests as we want to. One for each possible built-in and custom role that exists, for example. To do this, we use a feature introduced in PowerShell 7 where we can easily spin up threads by passing the -Parallel switch to ForEach-Object.
Another quick aside: running threads with PowerShell will never be as fast as running threads with C or another more performant language. But because we are interfacing with a web-based API, and because we are forced to introduce delays to wait for the Azure backend to catch up with our changes, we don’t need these threads to be fast.
Building and Running Atomic Tests with BARK
So far we’ve just talked about what BARK is designed to do and how it does it. Let’s see some results.
We will import BARK and feed a Global Admin credential and User Access Admin credential (which can be the same) to Invoke-AzureMGAbuseTests, specifying that we want to do the AzureRMVMRunCommand test. We will put the output of this function into a variable called $AzureRMAbuseTestResults:
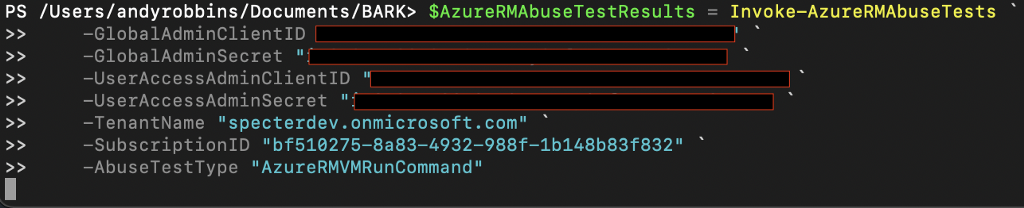
Once complete, we can see the count of test results in this object by piping this object to Measure:
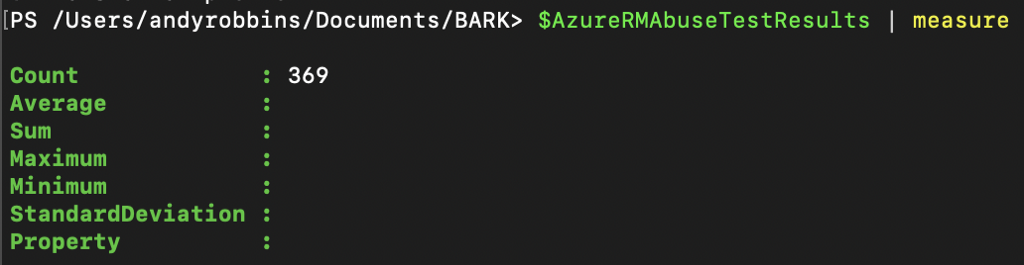
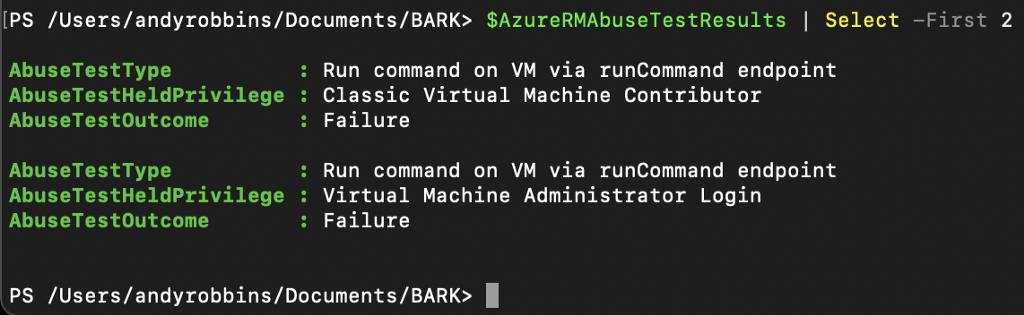
Then if we look at the first two test results we can see that the tests where the service principal was granted either the “Classic Virtual Machine Contributor” or “Virtual Machine Administrator Login” role did not succeed. In other words, those roles do not allow the principal to run commands on a VM via the runCommand endpoint:
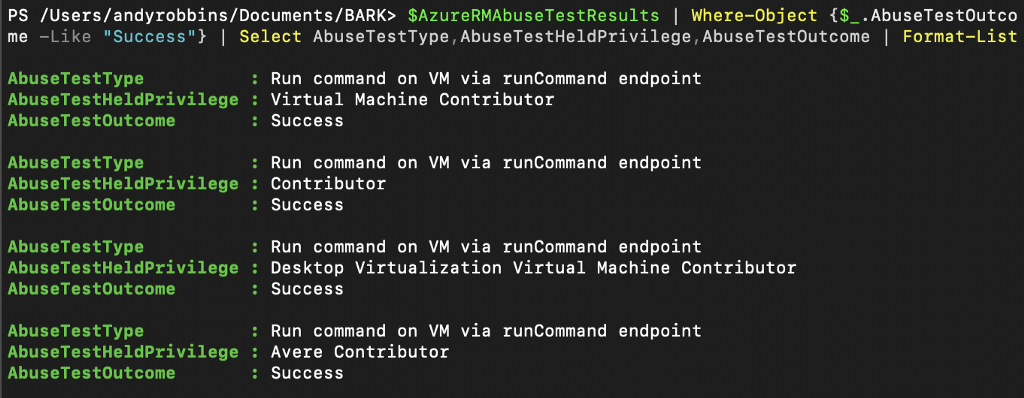
We can easily see which roles WERE able to execute this abuse with a simple pipe to Where-Object:
With a bit of object manipulation we can then get this data into a CSV format, import it into some spreadsheet software, and easily visualize these test results:
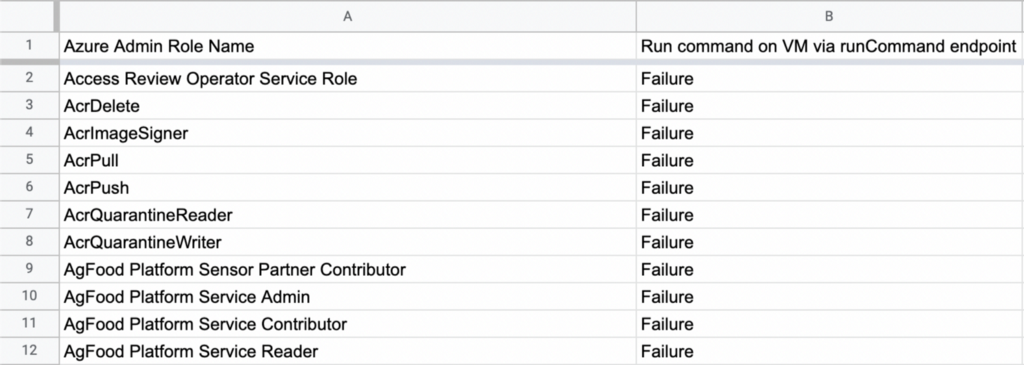
Sorted by test outcome:
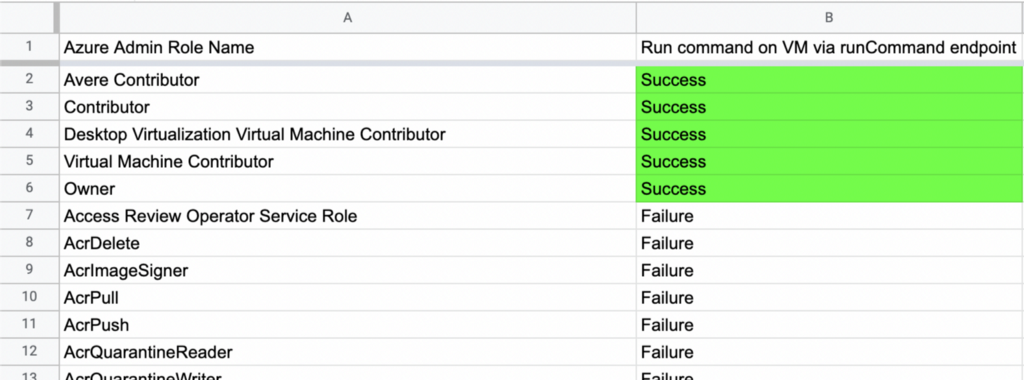
Now we know which roles are abusable in this particular way because we have tested every single one, as opposed to thinking we know which are abusable because we’ve read some documentation and parsed some settings.
Now let’s take this idea further.
Simultaneously Running All Atomic Tests
We don’t just care about knowing which roles are abusable for the sake of executing commands on a Virtual Machine. There are many other abusable objects in Azure we can run tests against, plus objects in AzureAD that can be abused through various privilege access control mechanisms.
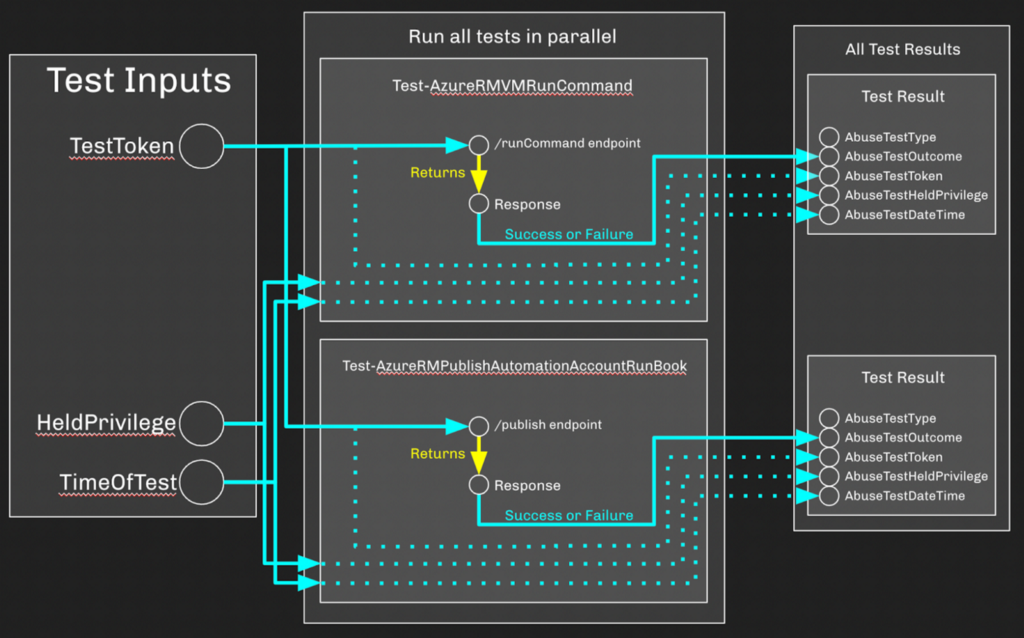
If we do not specify an AbuseTestType when running Invoke-AzureRMAbuseTests, the default behavior is to run all known tests against all known objects in AzureRM. Here’s a very basic visual of how this works if we only knew about two abuses:
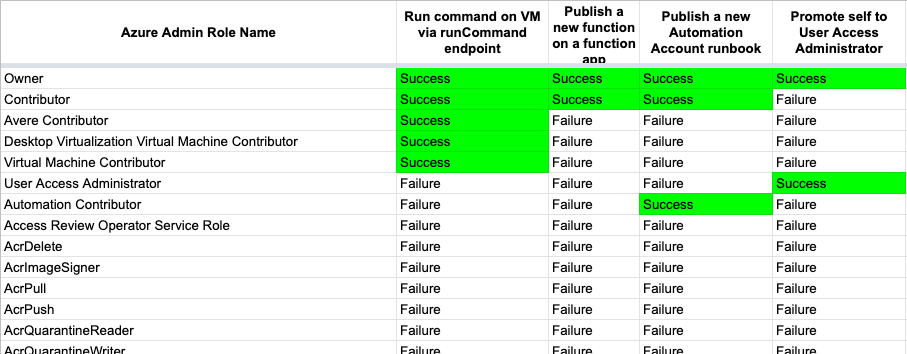
We can easily run all tests similar to our previous commands, but this time not specifying any AbuseTestType:

Then massage the output into a CSV and import that CSV into some spreadsheet software to easily visualize all test results:
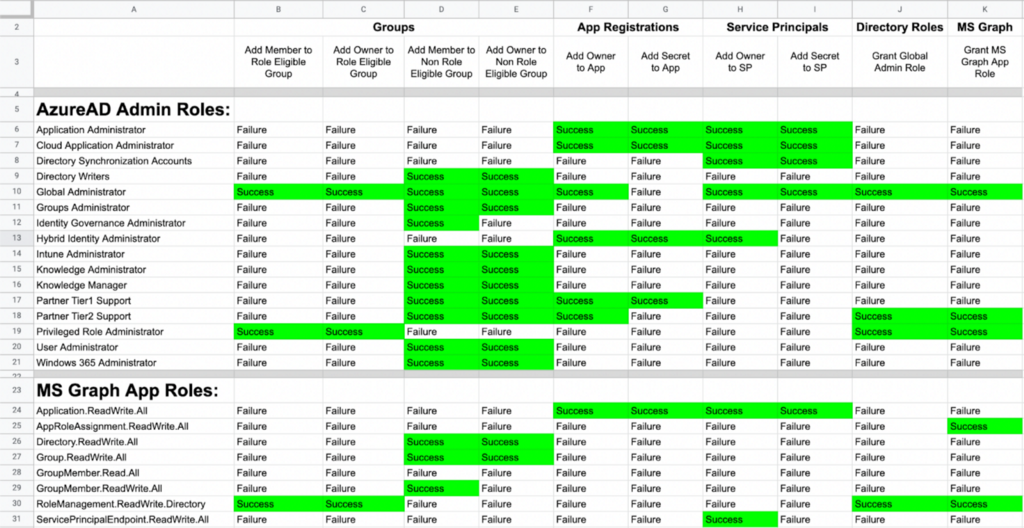
We’re not limited to AzureRM, either. We can perform tests against AzureAD objects using both AzureAD admin role as well as MS Graph App role assignments:
Future Work
Today this process still requires manual intervention to start the tests, clean up after the tests, and massage the test outputs into an easily digestible format. In the future, we will have proper automation built on top of these tests for our own internal purposes, and we also intend to make those daily test results freely available for anyone to see.
Automating Azure Abuse Research — Part 2 was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.