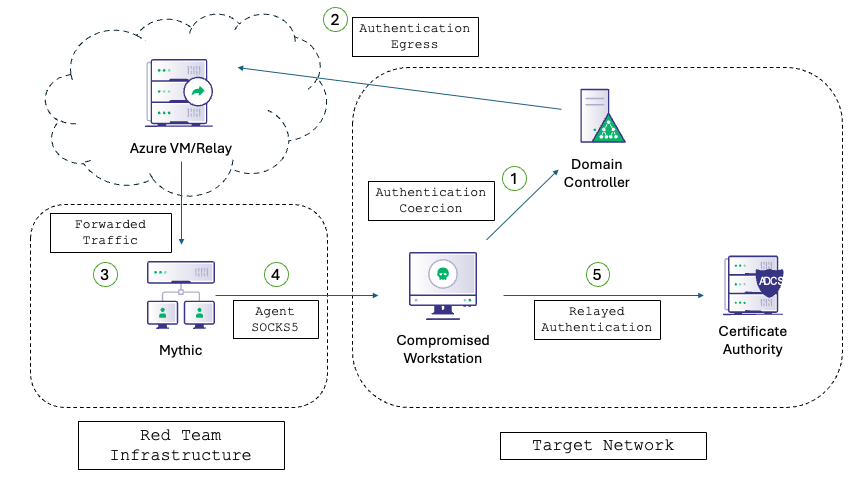
On Detection: Tactical to Functional
Part 11: Functional Composition
Introduction
Welcome back to part 11 of the On Detection blog series. This next article serves as a conceptual foundation upon which we will build over the next few posts. It may not be immediately obvious why this is important, but understanding this concept will make many subsequent ideas much easier to parse.
A colleague of mine, Max Harley, introduced me to the idea of composition in functional programming. In doing so, he introduced me to a book called An Invitation to Applied Category Theory: Seven Sketches in Compositionality. Among other things, this book explores using Category Theory to hide complexity in some cases, but also the idea of how functions compose together through shared inputs and outputs. For instance, consider the image below (Figure 1) which came from the book and represents a recipe for lemon meringue pie as a wiring diagram.
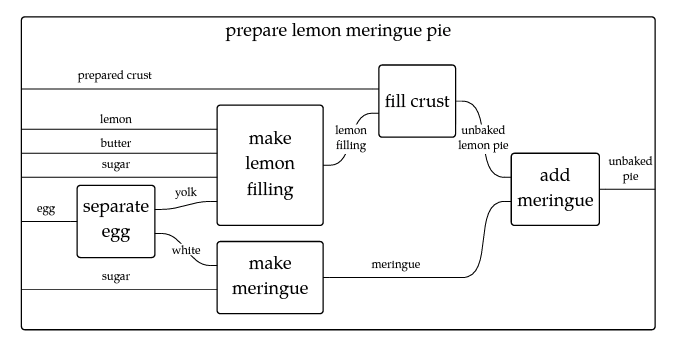
In this diagram, we see how one can move from the raw ingredients to the final product, assuming all necessary ingredients are on hand and the chef understands the functions that each of the boxes represent. If you have an egg, then you can separate the yolk from the white. Those two different components then serve as inputs to different subroutines, specifically “make lemon filling” and “make meringue.”
The goal of this blog post is to encourage you to begin thinking about malicious function chains in this same context. What are the raw ingredients that are necessary to implement this function chain, what are the subroutines that must be implemented in order to produce an intermediate ingredient (such as the meringue), and what are the steps and their order that is necessary to produce the final product?
In the next section, we will investigate three different function chains (i.e., Token Impersonation/Theft, Process Injection, and File Mapping) to understand how composition manifests and discuss some of the implications of composition on our detection engineering efforts. Once we have adjusted our conception of function chains to fit this model, we can begin to make educated decisions about how to construct resilient detection rules based on these “dependency graphs.”
Token Impersonation/Theft
The first example that we will dig into is standard Token Impersonation/Theft. This is the implementation that you would expect to see in many so-called getsystem tools, such as the Get-System function I wrote for my PSReflect-Functions PowerShell module (Figure 2).
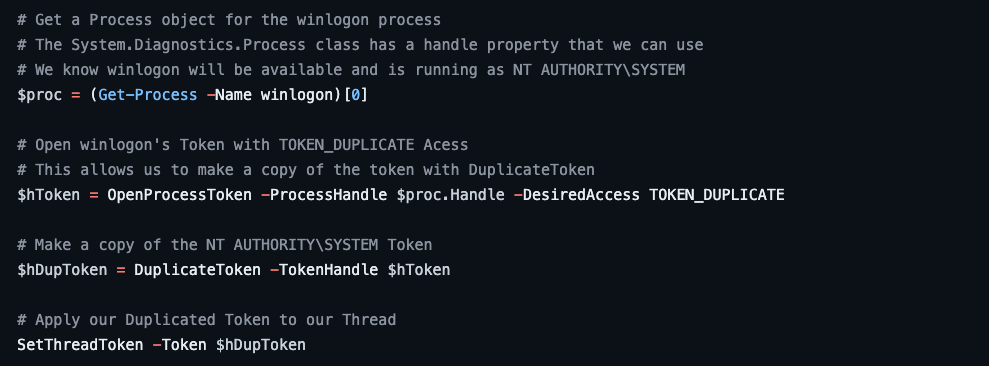
The source code, shown above, indicates that four Windows API functions are called in order to implement this behavior.
Note: The first function, OpenProcess, is hidden behind the Get-Process PowerShell function.
- OpenProcess — Opens a handle to the remote/target process; this process will run in the context of the target user
- OpenProcessToken — Opens a handle to the primary token for the primary process (i.e., the token to be “stolen”)
- DuplicateToken — Creates a duplicate copy of the token so it can be applied to the calling thread
- SetThreadToken — Applies the duplicate copy of the token to the calling thread, thus impersonating the target user
Below, we see a function chain representing this implementation of System Token Impersonation/Theft (Figure 3).

Mapping Functional Dependencies
Since this is the first example, it seems useful to explicitly map how functional composition works in practice. In this section, we will view the syntax section of the Microsoft documentation for each function and trace the output of each function as it is used as an input to subsequent function(s).
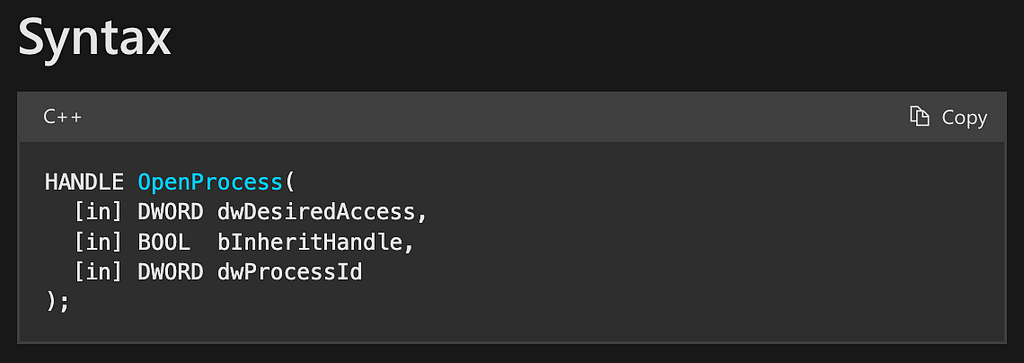
The first function is OpenProcess. This function takes three parameters and outputs a HANDLE to the specified process. The first parameter is dwDesiredAccess, which indicates the type of access that the calling program is requesting to the target process (This value must include at least the PROCESS_QUERY_LIMITED_INFORMATION access right). The second parameter, bInheritHandle, specifies whether “processes created by this process will inherit the resulting handle.” There’s no requirement for handle inheritance in this use case so this value can be set to FALSE. The final parameter is dwProcessId which is the process identifier of the target process. There are many ways for programmers to derive this value, but for this discussion we will assume the attacker already has this information.
We can then begin by using GraphViz to model the OpenProcess function where the box in Figure 6 represents OpenProcess and each row represents its output (the first row) and parameters. Since OpenProcess is the first function in the chain, there aren’t any interesting relationships for us to draw yet.
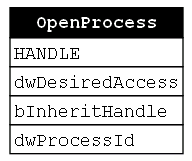
The second function in the chain is OpenProcessToken. Next, we look at the syntax section for OpenProcessToken and see that the function takes three parameters namely ProcessHandle, DesiredAccess, and a pointer to a HANDLE called TokenHandle. We also notice that the return value for this function is of the type BOOL (Figure 7).
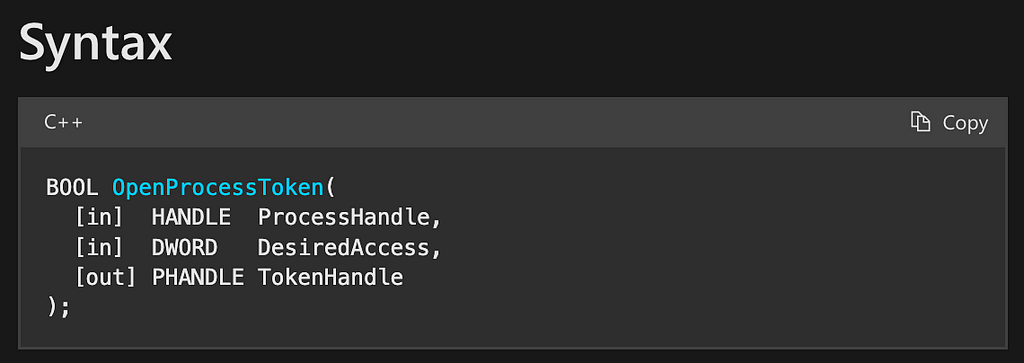
After consulting the specific details for each parameter, we find that ProcessHandle should be “a handle to the process whose access token [will be] opened,” which means this will be the process handle that was returned from the OpenProcess call. We are starting to see composition in action. The output of the OpenProcess call is being used as the input to the OpenProcessToken call.
The second parameter, DesiredAccess, expects “an access mask that specifies the requested types of access to the access token.” This is dependent on what the programmer wants to do next (in this case TOKEN_DUP_HANDLE), but the value is predictable and thus does not depend on some prior function call.
Finally, the third parameter, TokenHandle, is actually where the handle to the “newly opened access token” is returned. This function acts slightly differently than OpenProcess. In this case, the handle is returned as an output parameter instead of to the return value. A short consultation with the Return value section tells us that the BOOL return value simply reports whether the request was successful or unsuccessful.
We can now update our GraphViz diagram to include an OpenProcessToken record and an arrow which represents the relationship between the HANDLE value that the OpenProcess function returns and the OpenProcessToken function’s ProcessHandle parameter (Figure 8).
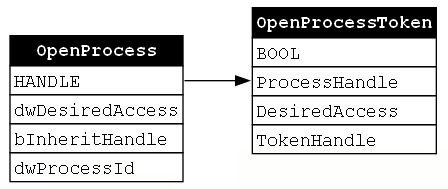
Now that we have a token handle, we can start to think about using it. There’s only one problem: our token handle is already in use by an existing process. To impersonate the token, we must first make a copy of it. Luckily, our third function, DuplicateToken, does just that.
The syntax section of the DuplicateToken documentation page shows that the function takes three parameters, namely ExistingTokenHandle, ImpersonationLevel, and DuplicateTokenHandle. Also, much like OpenProcessToken, we see that it returns a BOOL value which, according to the documentation, also reports on whether the function executed successfully or unsuccessfully (Figure 9).
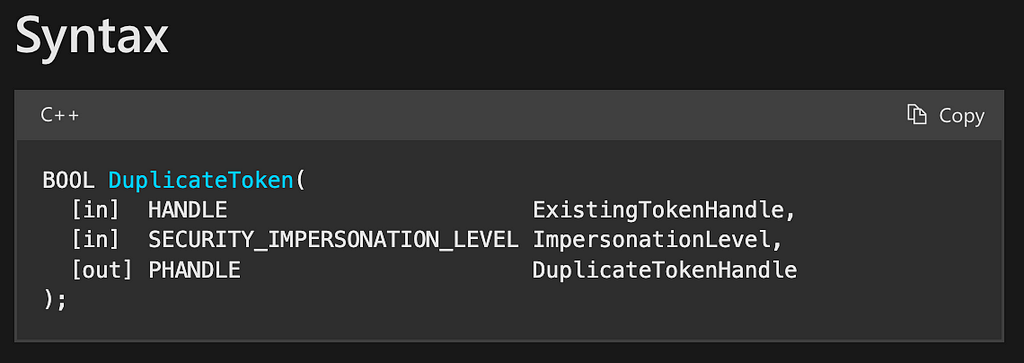
Digging a bit deeper into the Parameter section, we find that the ExistingTokenHandle parameter is a handle to an access token. This is where the value that was returned from our call to the OpenProcessToken function will be passed. Again, we see that OpenProcessToken and DuplicateToken compose. The ImpersonationLevel parameter specifies the SECURITY_IMPERSONATION_LEVEL of the new token. This is a predictable value and therefore has no dependencies. Finally, the DuplicateTokenHandle parameter is another output parameter where the new copy of the access token is returned.
We can now update our GraphViz diagram to include the DuplicateToken function call and show how the value that is returned to the OpenProcessToken’s TokenHandle parameter becomes an input for the call to DuplicateToken; specifically the ExistingTokenHandle parameter. We are now 3/4 of the way through our function chain and we see that, so far, all of the functions compose into a “valid” function chain (Figure 10).
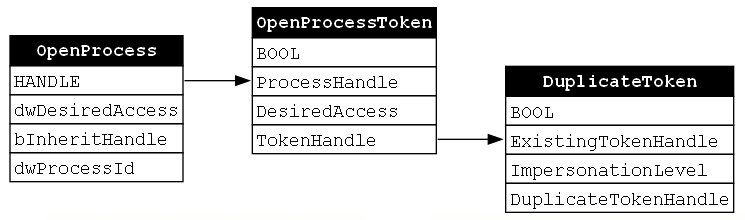
At this point, we have a copy of the target access token. Now all we have to do is apply it to our current thread. This will allow us to take over the identity of the target account (NT AUTHORITYSYSTEM in this example). In order to do this, the final function call is to the SetThreadToken function. This function is quite simple as it has only two parameters, Thread and Token, and returns a BOOL value reporting successful execution (Figure 11).
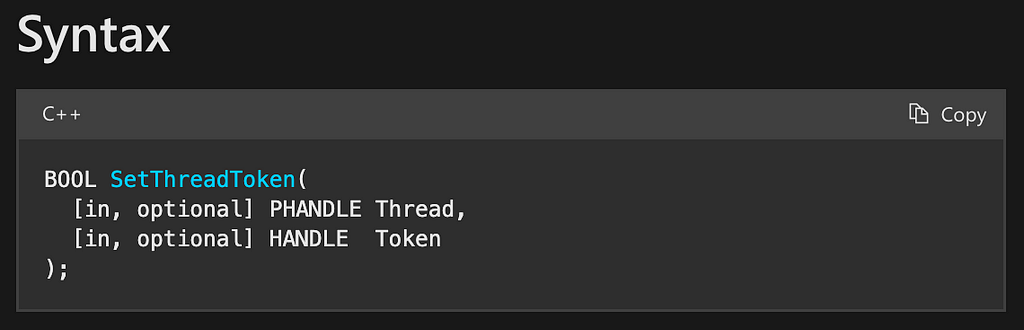
According to the parameter details found in the documentation, the Thread parameter identifies “the thread to which the function assigns the impersonation token”; however, it also mentions that if this parameter is set to NULL, then “the function assigns the impersonation token to the calling thread.” This means that the attacker can just set this parameter to NULL and the token will be assigned to their thread.
The Token parameter is the handle to the token to be impersonated. This parameter will be set to the copy of the token that was returned from the call to the DuplicateToken function. Again, this is where our functions compose!
We can now produce our final GraphViz diagram for this function chain and we will see that each function in the chain composes with the subsequent function (Figure 12).
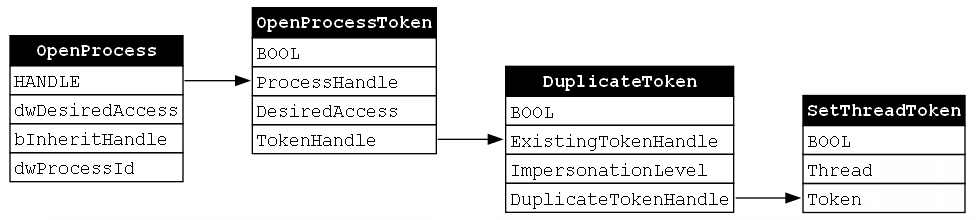
This diagram tells us a few things. First, each function in the chain is necessary to accomplish the target behavior, namely token impersonation. Second, the order of the functions in the chain is fixed. Since each function is dependent on the output of the proceeding function, we cannot call these functions in any other order. With those observations in mind, we must remember that we have only analyzed one function chain. As we look into more chains, we should keep our eyes open to determine whether these observations are general rules that apply to all function chains or whether they are idiosyncratic in that they apply only to this specific or to similar function chains.
Process Injection
Our second example is the traditional implementation of Process Injection. Here, we will examine the standard function chain that includes OpenProcess, VirtualAllocEx, WriteProcessMemory, and CreateRemoteThread as this is the most common function chain seen to implement Process Injection (Figure 13).
- OpenProcess — Opens a handle to the remote/target process
- VirtualAllocEx — Allocates a memory buffer in the target process that will be used to hold the payload
- WriteProcessMemory — Writes the shellcode payload into the previously allocated memory buffer in the target process
- CreateRemoteThread — Creates a thread in the target process that executes the payload

Mapping Functional Dependencies
Let’s now take a look at how the functions in this function chain compose.
If we were to perform the same type of analysis of each function that we did for the previous example, we would find that OpenProcess outputs a handle to a process of type HANDLE. Then we would find that VirtualAllocEx, WriteProcessMemory, and CreateRemoteThread all take that process handle as an input. This means that the call to OpenProcess is NECESSARY for each of the subsequent calls. The resulting dependency graph would then appear as such (Figure 14):
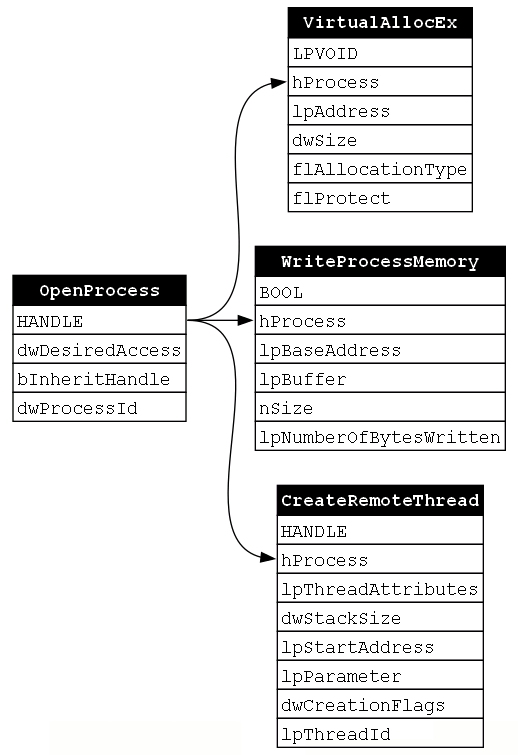
Now the question is to understand the rest of the dependencies. We saw that our sample function chain calls the VirtualAllocEx function next. Was this just preference or is this order required due how the functions compose? If we look at the VirtualAllocEx documentation, we see its stated purpose as “reserves, commits, or changes the state of a region of memory within the virtual address space of a specified process.” This tells us that the memory buffer is being allocated before we eventually write our payload to it.
Next, we see that the return value is an LPVOID (a pointer to a memory buffer) and the documentation says that “if the function succeeds, the return value is the base address of the allocated region of pages.” It turns out that this base address will be used as an input for both WriteProcessMemory’s lpBaseAddress parameter and CreateRemoteThread’s lpStartAddress parameter. This indicates that VirtualAllocEx MUST come second in the function chain because it depends on OpenProcess, but it is depended upon byWriteProcessMemory and CreateRemoteThread. With this knowledge, we can update the dependency graph as shown below (Figure 15):
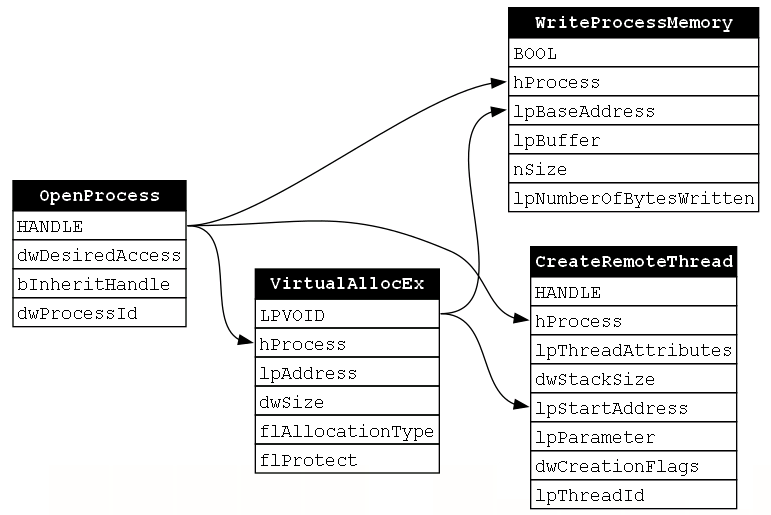
The third function is WriteProcessMemory. In this context, this function is used to write code to the previously allocated memory buffer. Upon analyzing the relationship between our final two functions, WriteProcessMemory and CreateRemoteThread, there does not seem to be an explicit relationship like we’ve seen previously. There is no output from WriteProcessMemory that is used as an input to CreateRemoteThread. However, we do know that the purpose of CreateRemoteThread is to execute the payload which is written by WriteProcessMemory. If WriteProcessMemory doesn’t happen, then there is no use in calling CreateRemoteThread. Therefore, there is still an element of necessity to the ordering of these two functions.
To represent this more implicit relationship between WriteProcessMemory and CreateRemoteThread, I used a gray arrow to point from WriteProcessMemory’s lpBuffer parameter (i.e., the parameter where the payload is passed to the function) and CreateRemoteThread’s lpStartAddress parameter which is a pointer to the buffer in process memory where that payload lives. We can now produce our final dependency graph for this function chain as shown below (Figure 16):
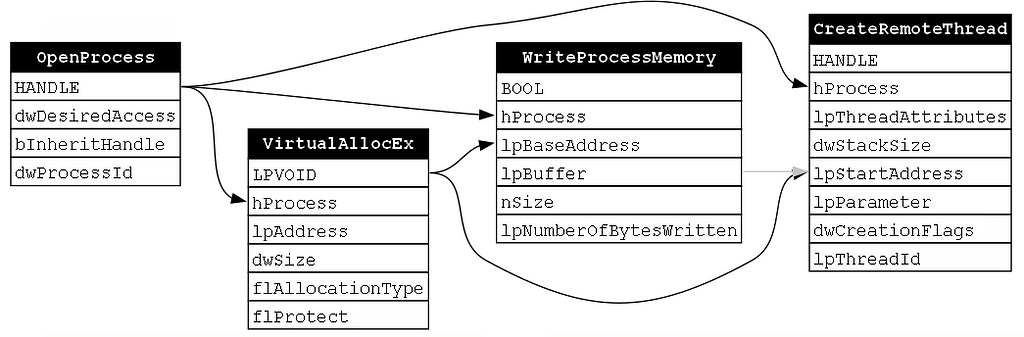
Our analysis of this second chain again shows the fixed nature of the order of functions in the chain. These relationships allow us to say things like OpenProcess is NECESSARY for VirtualAllocEx and also show that we can start to make inferences about which functions are likely to have happened once we see a subsequent function. For instance, if we see a call to WriteProcessMemory, or more generically a Process Write operation, we can infer that OpenProcess was likely called and that the request included the PROCESS_VM_WRITE access right. This is a useful capability for detection engineers because modern endpoint detection and response (EDR) solutions present one event at a time. This means that we must base our detection rules on a single operation.
This is something I intend to delve more deeply into with the next article, but this inference is an important component in selecting which event to base a detection rule around.
File Mapping
Many readers will be familiar with the traditional “Process Injection’’ functional mechanics that we just explored in the previous section. A common way of expressing this chain more abstractly is that in order for Process Injection to occur, memory must be allocated, code must be written to that buffer, and the code must be executed. The aforementioned classic injection approach uses VirtualAllocEx as the allocation primitive, WriteProcessMemory as the write primitive, and CreateRemoteThread as the execution primitive. However, over the years, we’ve seen many evolutions of Process Injection that change the functional sub-chain that is used for one or more of these primitives.
In this section, we will investigate File Mapping Injection where the CreateFileMapping -> MapViewOfFile -> MapViewOfFile2 function sub-chain is used to replace the classic allocation primitive and memcpy (i.e., a local copy function) is used to replace the write primitive. Below (Figure 17) is a function chain that represents how one sample I found was implemented.
- OpenProcess — Opens a handle to the remote/target process
- CreateFileMapping — Creates an in memory file mapping object
- MapViewOfFile — Maps the file mapping object to the calling process
- MapViewOfFile2 — Maps the file mapping object to the target process
- Memcpy — Copies the payload to the locally mapped address of the file mapping object
- CreateRemoteThread — Creates a thread in the target process set to execute the payload located in the file mapping object

Mapping Functional Dependencies
Since this example is a bit more complicated, I will take a slightly different approach and only represent the relationship between functions once we’ve discussed both the source and the destination function. As we will see, while uncommon, it is possible for some function chains to be dynamic with regard to the order of functions. We will see why in this analysis.
The first function we encounter in this function chain is OpenProcess (Figure 18). Again, the point of this call is to open a handle to the target process of our injection.
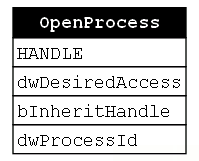
Next, we see a call to CreateFileMapping. Remember that this is a sub-technique of Process Injection where the goal is to change the manner in which memory is allocated and the code is written to the target process. This allows the malware to skip over the potentially “dangerous” calls to VirtualAllocEx and WriteProcessMemory. The CreateFileMapping function creates a file mapping object which allows multiple processes to “share a view of the same file mapping object.” Typically, this would be used to load a shared file, but if the hFile parameter is left NULL then an empty file mapping object is created and that can serve as a buffer for the malicious payload. Notice that none of the CreateFileMapping’s parameters take a process handle, so there is no relationship or dependency between OpenProcess and CreateFileMapping. This is the first time we’ve seen two consecutive functions in a function chain that do not compose (Figure 19).
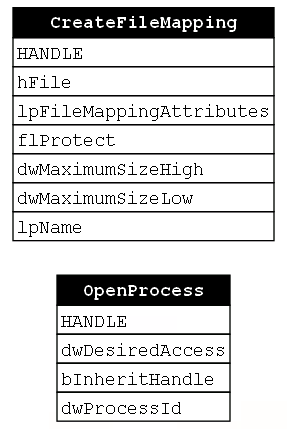
Now that the file mapping object has been established and we have a handle to it, we can begin mapping it into our source and target processes. By default, the file mapping object is not associated with any process, so the MapViewOfFile function must be called to “map a view of [the] file mapping into the address space of the calling process.” In this case, the calling process is the malware, so this is a local call. MapViewOfFile takes a number of parameters but the first, hFileMappingObject, is the one we are most interested in because we must pass the handle to the file mapping object that was returned from CreateFileMapping to it. Here we see that the CreateFileMapping and MapViewOfFile functions compose (Figure 20).

Next, a view of the file mapping object must be mapped into the target process. This will create a situation where the source and target processes can access the same memory buffer which will be quite useful once the payload is written to it. The MapViewOfFile function does not have the ability to map a view of the file mapping object to a remote process, but a separate function called MapViewOfFile2 does have that ability. In this case, both the handle to the process that was opened using OpenProcess and the handle to the file mapping object that was created via CreateFileMapping are passed to the ProcessHandle and FileMappingHandle parameters respectively. Now we are starting to see how OpenProcess and CreateFileMapping are indirectly related (Figure 21).
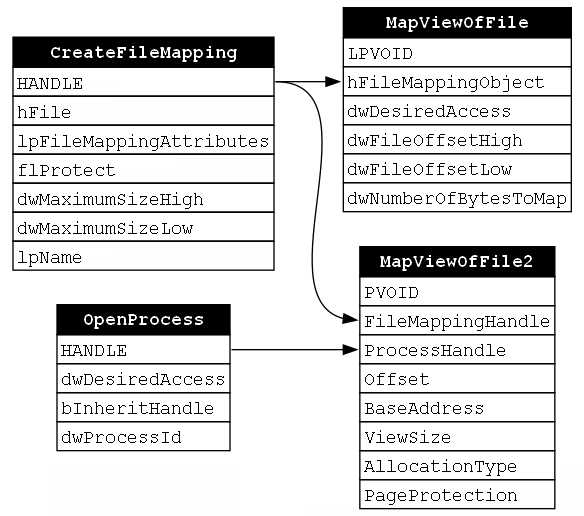
At this point, you might be wondering what the implications of this “indirect” relationship is between OpenProcess and CreateFileMapping. The answer, as we’ll see in more detail after we finish building the dependency graph, is that the order of functions in this function chain is not fixed in the same way that we saw in our previous examples.
Now the memory buffer has been allocated without calling VirtualAllocEx. Next, the payload must be written to the buffer without calling WriteProcessMemory. To do this, the C function memcpy is called. memcpy copies a source buffer to a destination buffer; however, it can only do this within the memory context of the calling process. This is why views of the file mapping object had to be mapped to the local process. The payload will be written using the local view (the view mapped via MapViewOfFile) and it will be executed using the remote view (the view mapped via MapViewOfFile2). This function requires the address of the local view (signified by the return value LPVOID of the MapViewOfFile call) to be passed to the dest parameter of memcpy. Once that is done, the code is written to the buffer and accessible to both the calling and target processes (Figure 22).
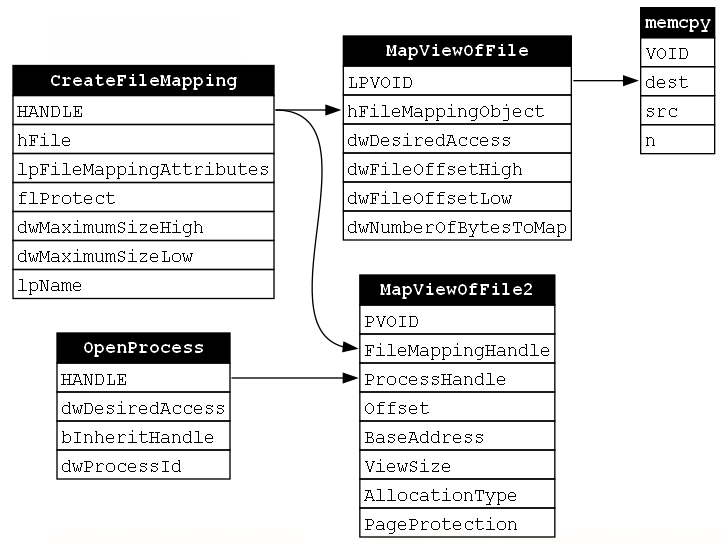
Finally, we must execute the malicious payload. While there are a few different ways to achieve this, we are sticking to using CreateRemoteThread which we saw in our previous example. CreateRemoteThread is going to require the handle to the target process that was opened via OpenProcess. It will also require the address of the view that was mapped via MapViewOfFile2 (represented by the return value PVOID). Additionally, as we discussed in the previous example, CreateRemoteThread only makes sense to execute once to code has been written to the buffer, so we will again include the implicit relationship (signified by the gray arrow) from the src parameter of the memcpy function to the lpStartAddress parameter of the CreateRemoteThread function (Figure 23).
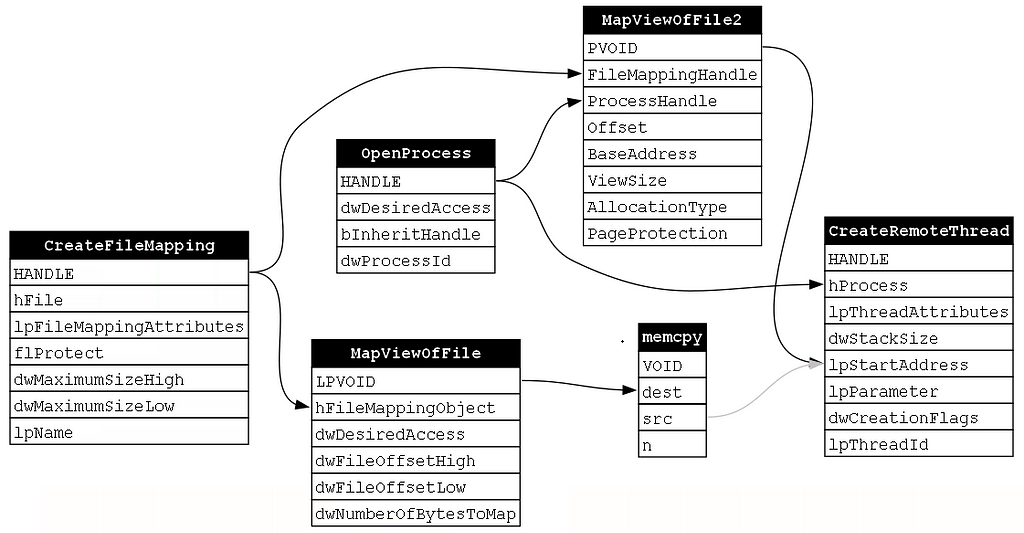
At this point, we recognize that this dependency graph is different from the previous examples we’ve analyzed; specifically, we see that there is not a single fixed function chain based on dependencies. Instead, there are multiple possible function chains. Consider the following two function chains. The first (Figure 24) is the example we started with and the second (Figure 25) is an alternative chain.

These chains have the same exact functions, but they are called in a different order. If you encountered two malware samples that respectively implemented these chains, would you consider them to be implementing the same “behavior?” This was a problem that I ran into while analyzing different technique implementations. Composition, specifically the dependency graph, gave me an answer to this question. The answer in question is that two function chains can be considered “functionally equivalent” if they produce the same dependency graph; therefore, from a detection perspective, the order does not matter.
Conclusion
As mentioned in the introduction, this post is not the most practical of the posts in this series. Instead, the goal is to set the conceptual foundation that we will use in subsequent posts.
It is important for detection engineers to understand the function chains that can be composed to produce certain effects in their networks. By understanding the raw ingredients needed and the different subroutines that are necessary to produce the adversary’s desired result, we can create more robust security controls by either denying those ingredients or subroutines or by monitoring for their instantiation. It is also important for us to understand that two tools can implement their functions in a different order while still being “functionally equivalent.” The dependency graph seems to be a better model for understanding “similarity” than the pure function chain.
Before I close, I’ll leave you with one last parting thought. In the aforementioned book, when they introduce the lemon meringue diagram (Figure 1), they provide the following prompt:
To obtain the things we want requires resources, and the process of transforming what we have into what we want is often an intricate one. Consider the following three questions you might ask yourself:
– Given what I have, is it possible to get what I want?
– Given what I have, what is the minimum cost to get what I want?
– Given what I have, what is the set of ways to get what I want?
This prompt is relevant to the question of attacker tradecraft. What resources does the attacker have naturally or has gathered through prior actions? What is it that they want to achieve? Is it possible to get from Point A to Point B? If so, what are the different ways (thinking function chains at this point) to get there? Which way achieves the objective with the lowest cost in terms of tradecraft exposure? This series is all about understanding what attackers need in order to achieve certain goals and the different ways in which they can get from raw resources to their desired end state.
On Detection: Tactical to Functional Series
- Understanding the Function Call Graph
- Part 1: Discovering API Function Usage through Source Code Review
- Part 2: Operations
- Part 3: Expanding the Function Call Graph
- Part 4: Compound Functions
- Part 5: Expanding the Operational Graph
- Part 6: What is a Procedure?
- Part 7: Synonyms
- Part 8: Tool Graph
- Part 9: Perception vs. Conception
- Part 10: Implicit Process Create
On Detection: Tactical to Functional was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.