Part 16: Tool Description
On Detection: Tactical to Functional
Why it is Difficult to Say What a Tool Does
Introduction
Over the years, I’ve noticed that we have a difficult time describing a specific tool’s functionality. I participated in conversations or listened to lectures where someone inevitably attempts to describe the techniques or behavior that they associate with a given tool. Someone might say “mimikatz is used for Credential Dumping” which is technically true, but does not provide a comprehensive description of mimikatz’s capabilities. In these interactions, I’ve often found this problem to be obvious, even to the speaker, but it has been difficult to pin down exactly what to do about it.
In this article, I plan to demonstrate WHY this problem exists. We will dig into two examples, the first shows that a single sample can implement multiple, independent techniques, while the second shows that changing a parameter can cause a different procedure to be executed. In reality, the problem is that a tool is an arbitrary bucket for tradecraft. Some tools are purpose built for one purpose and one purpose only, while others are frameworks that facilitate many different capabilities. Our analysis must go deeper than the tool layer to really discern what we are attempting to detect and I hope that this post provides a perspective on that topic.
One Tool, Multiple Techniques
This section dissects a sample that appears to implement a single technique, Token Impersonation, but upon a deeper review we find that the functionality of the tool can be broken apart. Specifically, we find that the tool builds in a design decision that causes two related but independent techniques to be combined in one chain. Depending on the execution context, the first half of the chain could be omitted completely, or it could have been implemented by a separate, purpose built, tool.
Dependency Graph Review
I want to start with a review of the Dependency Graph. This is a topic that I described in detail in Part 11 of this series, but a quick review will help this article stand on its own.
While the function chain is helpful in describing the actual sequence of functions that were called by the sample, a single function chain does not always tell the entire story. In my previous post I introduced functional composition which we then used as a mechanism for evaluating whether two function chains were equivalent. At the end of the post we showed two function chains that ostensibly implemented the same Process Injection variant (seen below).


The two samples called the same functions, however, the samples called the functions in a different order. An obvious question that might arise is “how important is the order of the functions in the chain?” These chains are not literally the same due to the difference in their function order, but are they equivalent? We were able to answer that question using functional composition because both function chains produced the same dependency graph (shown below):
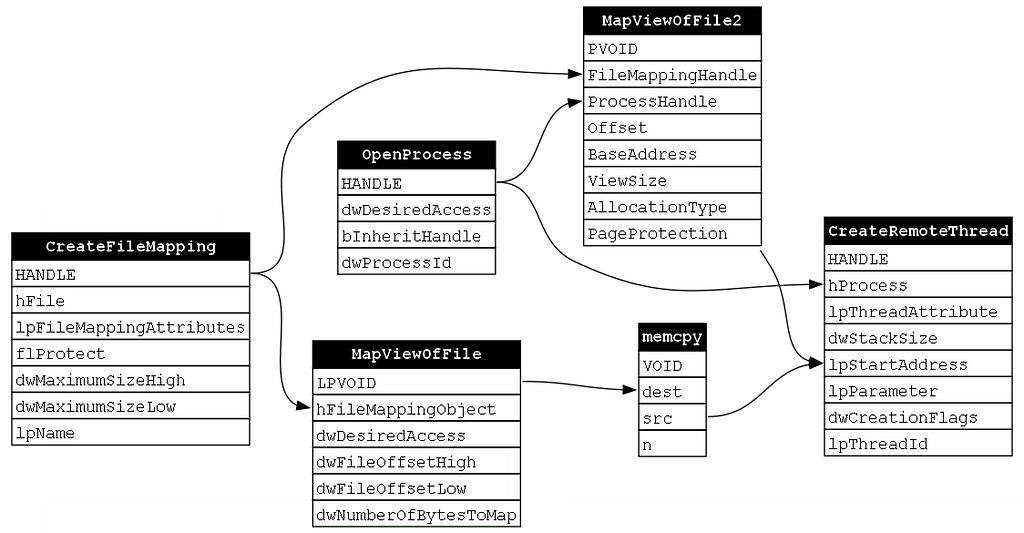
This analysis shows that dependency graphs can be used to evaluate equivalency between samples, but is that the only use case for dependency graphs? In this post, I want to explore a different use case for this analytical tool that will put another tool in our tool belt for understanding how to describe and categorize adversary tradecraft.
Can a single tool implement multiple techniques?
For this section we will assess the function chain implemented in Justin Bui’s PrimaryTokenTheft tool. I’ve included a diagram showing the layout of the code implementation.
Note: I highly recommend spending some time comparing the code itself to this diagram, especially if you are are relatively new to programming or operating system APIs.
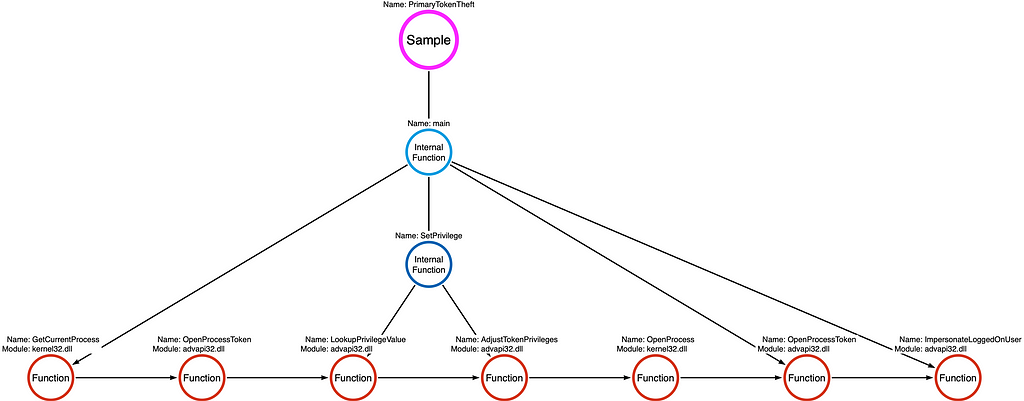
The function chain
The result of analyzing the tool is a function chain as shown below:

If we were working towards building a robust behavioral detection rule, we would work to derive the corresponding operation chain. However, in this post, we are interested in looking at the function chain from a different direction. Our goal is to understand how the functions in the function chain are interconnected and what the implications of those relationships are.
Dependency as Techniques
While the function chain is a useful analytical tool, it leaves out a lot of details. For example, it is impossible to tell from the function chain alone how the different functions interact with one another and what the implications of those interactions are. I think of the function chain as viewing the sample in 2D. We are able to derive a general gist of what the sample does, but we are missing something. So what happens when we add an extra dimension, composition, to the mix? I’ve included the dependency graph for the PrimaryTokenTheft sample below:
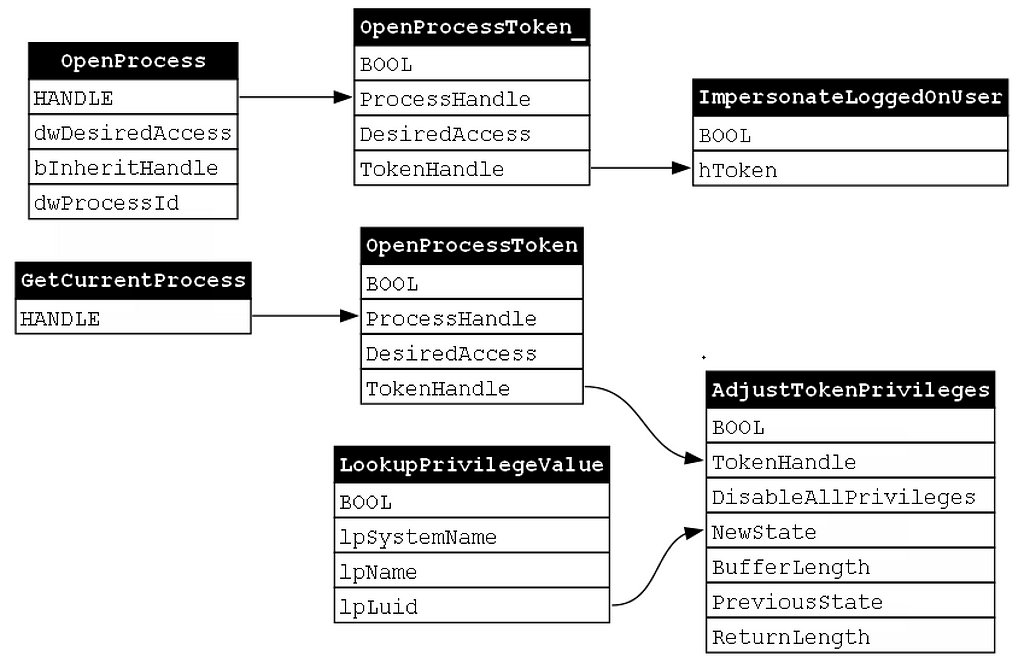
Notice that the functions break out into two discrete/disconnected dependency graphs. The top dependency graph, which I will label as “token impersonation”, is composed of OpenProcess, OpenProcessToken, and ImpersonateLoggedOnUser. The bottom dependency graph, which I will label as “privilege enablement”, is composed of GetCurrentProcess, OpenProcessToken, LookupPrivilegeValue, and AdjustTokenPrivilege. We can then analyze the two dependency graphs to understand what sub-functionality each performs. For example, the token impersonation dependency graph opens a handle to a target process (OpenProcess), opens a handle to the target process’s primary token (OpenProcessToken), applies that token to the calling thread (ImpersonateLoggedOnUser). Thus we can say that the purpose of this dependency graph is to perform token impersonation. Hmmm, token impersonation is the purpose of the tool itself, so what is this second dependency graph responsible for? Let’s take a look! It appears that this second dependency graph opens a handle to calling process (GetCurrentProcess), it opens a handle to its own primary token (OpenProcessToken), it then looks up the value associated with the SeDebugPrivilege (LookupPrivilegeValue), it then enables the SeDebugPrivilege privilege (AdjustTokenPrivileges). If we refer back to the function chain, we can see that the functions that make up the second dependency graph are called first. This is because the SeDebugPrivilege ensures that the calling process is able to perform token impersonation without any issues. For this reason I will refer to this dependency graph as Privilege Enablement for the remainder of this post.
So what are the takeaways from this analysis? An interesting observation is that each dependency graph seems to represent some minimum viable capability. While it is technically possible to create a program that simply calls OpenProcess with no follow on functions, the resulting program will not behave in a consequential way. In order for the program to do anything useful, it must implement the full dependency graph.
Another important observation is that multiple dependency graphs can be implemented within the same sample or tool. We can imagine many situations where the a tool is not required to implement Privilege Enablement as part of its Token Impersonation workflow. If the tool is run as a high privilege context, it would be able to perform the token impersonation without enabling SeDebugPrivilege first.
One Tool, Multiple Procedures
In this section I want to explore an idea that was first pointed out to me by Nathan Davis. He worked with me to learn this methodology and made an interesting finding while applying the ideas from this series to a component of PowerSploit’s PowerUp module. He was building a function chain for PowerUp’s Get-ProcessTokenPrivilege function, when he noticed that the function chain would change slightly depending on whether a specific parameter were specified by the caller or not.
PowerSploit/Privesc/PowerUp.ps1 at master · PowerShellMafia/PowerSploit
Nathan specifically noticed that the the Get-ProcessTokenPrivilege function took two optional parameters, Id and Special, as shown in the image below:
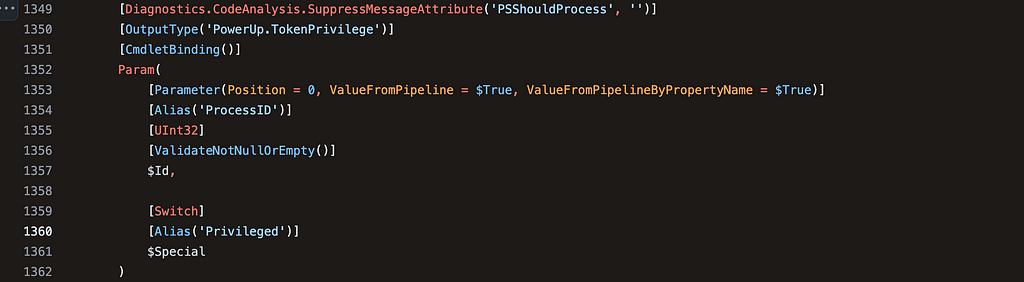
It is quite common for PowerShell functions or command line applications to accept arguments via the command line, but I had not properly considered how different parameters can affect what happens when the application or function is executed. The primary example that Nathan found is shown in the image below.
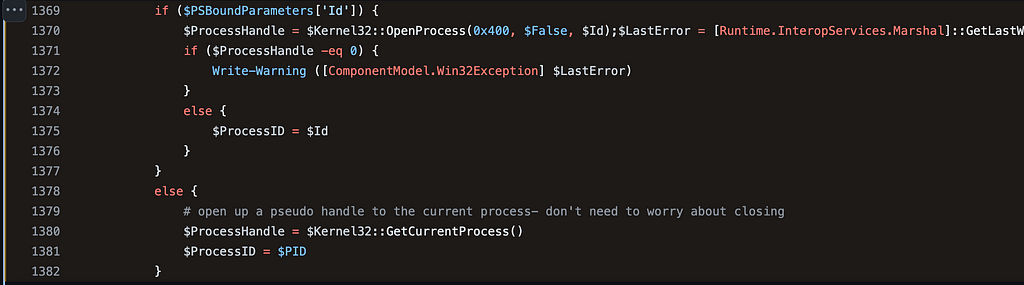
Notice that the snippet begins with an if statement which specifically checks whether the Id parameter was specified on the command line. PSBoundParameters is a special variable that contains a dictionary of the parameters that were passed to the function. Checking whether a parameter exists within the dictionary is a standard way of checking whether a parameter was specified in when the function was called. This means that the condition for the if statement is checking whether the caller passed the Id parameter. If the Id parameter was passed, then the kernel32!OpenProcess function would be called. However, the else statement indicates that if the Id parameter was not specified, the kernel32!GetCurrentProcess function would be called instead. This means that there are, at least, two paths that might manifest as a result of calling this one function.
Note: This seems obvious in retrospect, but I still think this is valuable exercise for folks to see as they delve into applying the On Detection model to their analysis of attacker tools and behaviors.
OpenProcess vs. GetCurrentProcess
At this point, we know that there are two possible functional variations depending on the Id parameter, but if you’ve made it this far into the series and are like me you are probably wondering just how different those two functional variations might be. Do both functions abstract to the same operation? If so, this function-level difference does not really affect our description of the tool. We see that the output of both functions is stored in the ProcessHandle variable, so they probably are not terribly different. Well, the only way to definitively answer that question is to dig into the function call stacks for both kernel32!OpenProcess and kernel32!GetCurrentProcess.
Note: This next section walks through the generation of function call stacks for both kernel32!OpenProcess and kernel32!GetCurrentProcess. For those that have read the entire series, this is probably repetitive. However, this provides necessary context for those readers that are just joining us AND it never hurts to get another repetition of analysis under our belt.
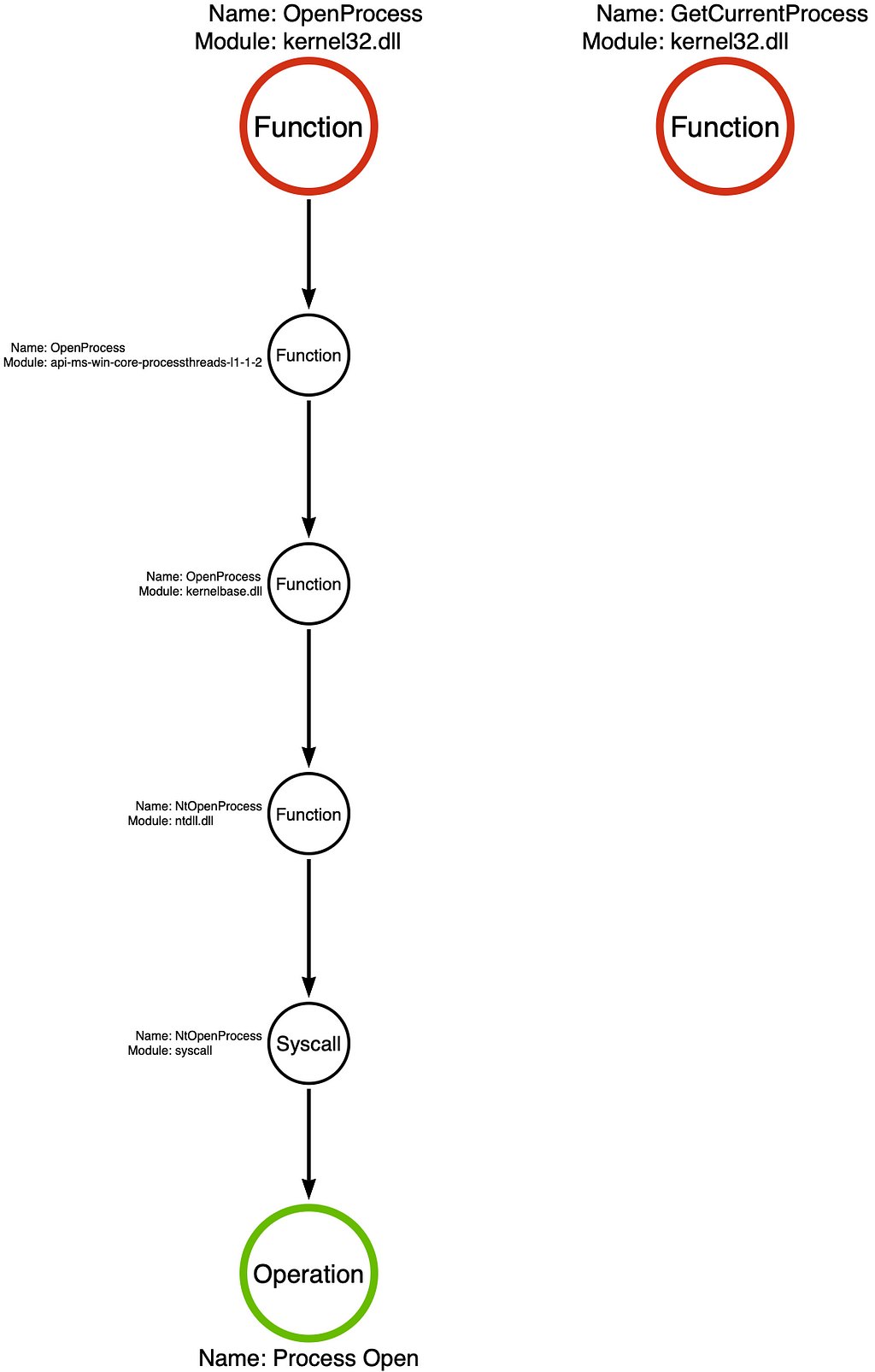
kernel32!OpenProcess
The first step to analyzing a function call stack is to open the specified DLL file in a disassembler (we are using IDA Free in this post). We derive the DLL file from the code on line 1370 in the proceeding image. It specifically refers to $Kernel32::OpenProcess which indicates that it calls the version of OpenProcess that kernel32.dll implements (otherwise known as kernel32!OpenProcess). I’ve included an image of the kernel32!OpenProcess function’s implementation below:
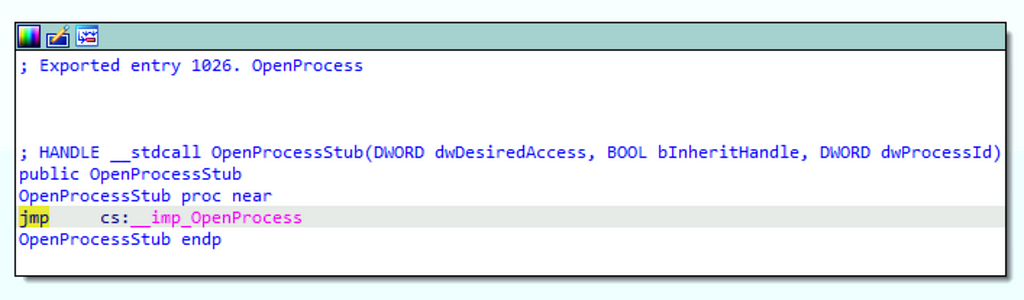
Notice the jmp cs:__imp_OpenProcess instruction. This indicates that execution should be redirected to an imported function (indicated by __imp_) named OpenProcess. The import table indicates that kernel32!OpenProcess redirects to api-ms-win-core-processthreads-l1–1–2!OpenProcess.
We can use the Get-NtApiSet function from James Forshaw’s NtObjectManager module to resolve the api-ms-win-core-processthreads-l1–1–2 ApiSet. In doing so, we find that the OS will redirect any calls to api-ms-win-core-processthreads-l1–1–2!OpenProcess to kernelbase!OpenProcess.

Next we can open kernelbase.dll in our disassembler and browse to its implementation of OpenProcess which is shown below:
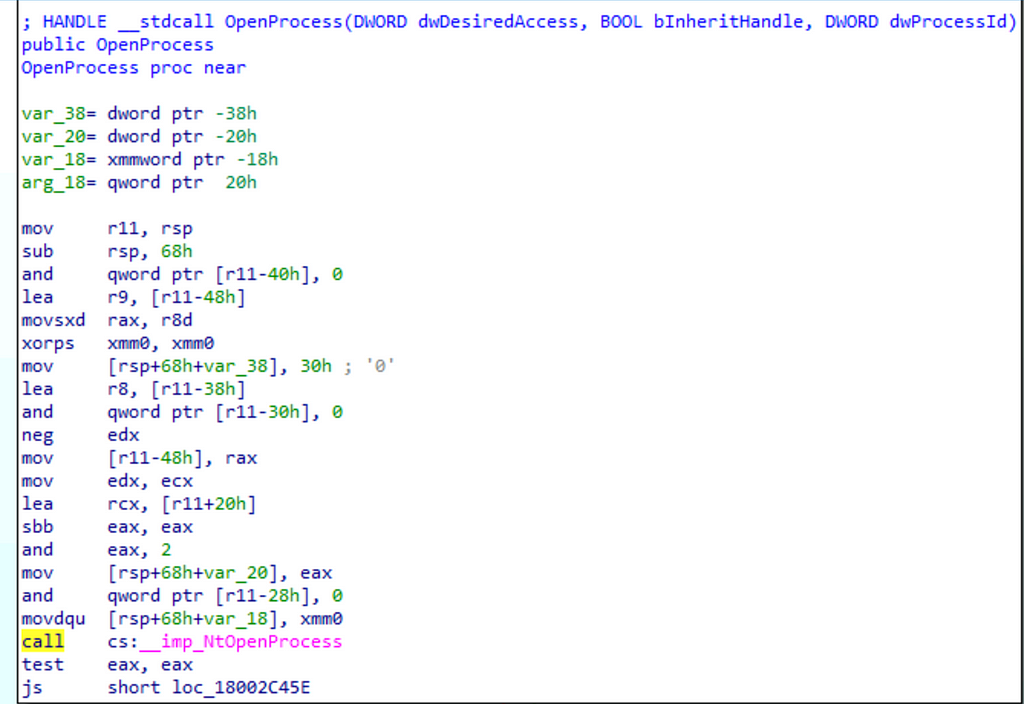
While kernelbase!OpenProcess appears to do a bit more work than kernel32!OpenProcess, we find that it very quickly calls another imported function (__imp_NtOpenProcess). After consulting the imports table, we find that NtOpenProcess is implemented in ntdll.dll. Finally we open ntdll.dll in the disassembler and browse to the implementation of NtOpenProcess, shown below:
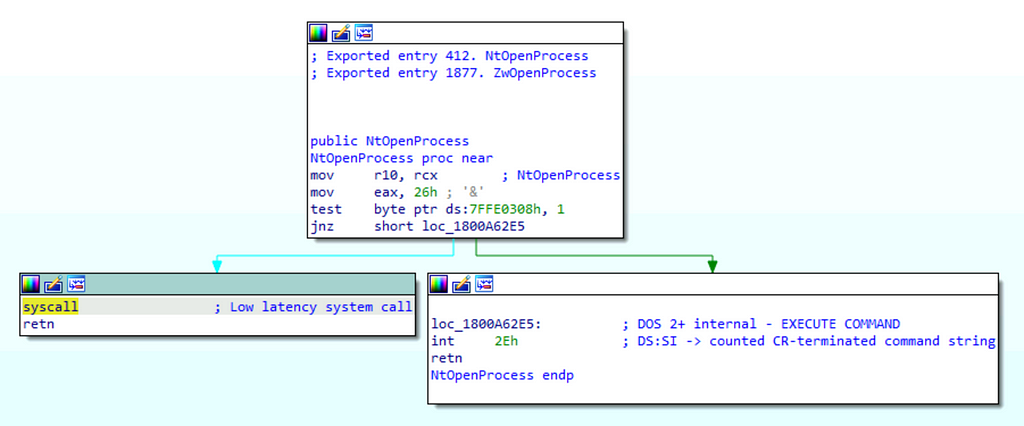
We see that ntdll!NtOpenProcess makes a syscall to a kernel-mode function that we will call NtOpenProcess. We can now use the syscall rule which allows us to summarize a function call stack that ends in a syscall using a single operation, in this case the Process Open operation. With our analysis complete, we can graph the relationship between these functions using a “function call stack” which is shown below. For more information about function call stack, I recommend reading Part 2 of this series.
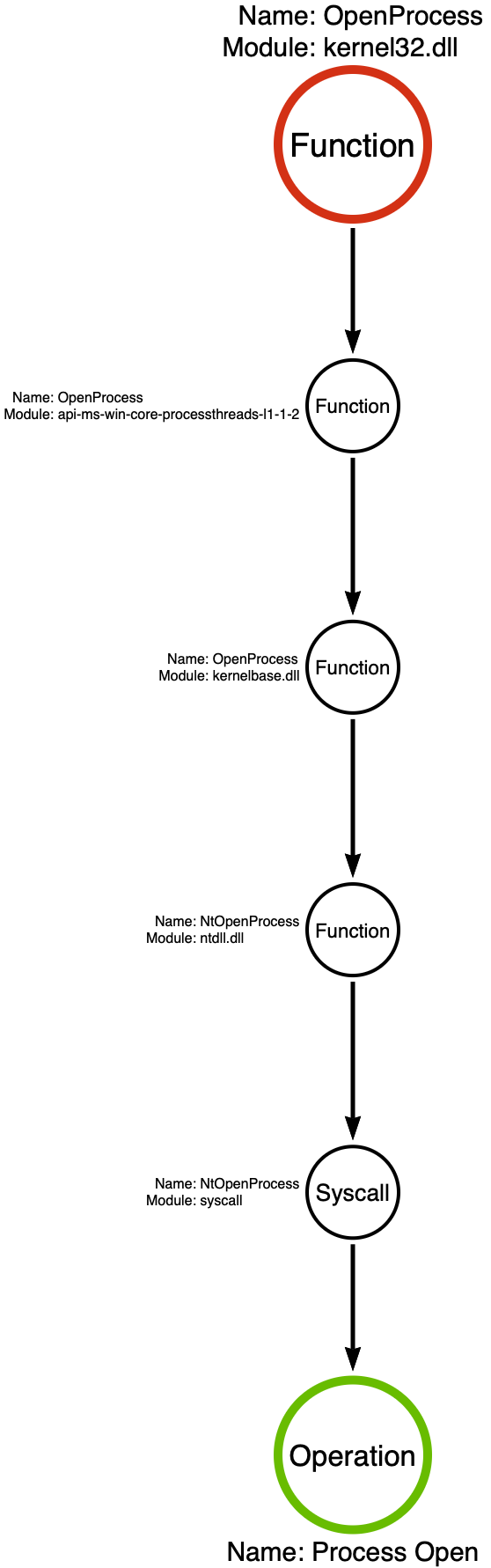
kernel32!GetCurrentProcess
Next we will analyze GetCurrentProcess which, according to line 1380 of the Get-ProcessTokenPrivilege code snippet that is shared above, is implemented by kernel32.dll. We’ve already loaded kernel32.dll into our disassembler, so we can use the Exports tab to view the GetCurrentProcess function’s implementation.
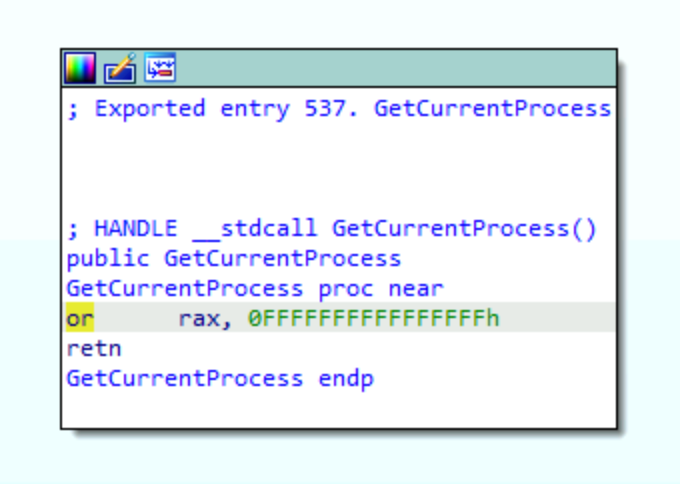
The first thing you should notice is that kernel32!GetCurrentProcess does not make a call or jmp of any kind. Instead, it sets the rax register, which is implicitly set to 0, to 0xFFFFFFFFFFFFFFFF (hex) or -1 (decimal) and returns the value. This means it does not make a syscall or remote procedure call, and therefore does not seem to implement an operation within the construct of our model. It turns out that -1 is considered a special “pseudo-handle” by Microsoft. Microsoft describes this pseudo-handle in the Remarks section of the GetCurrentProcess function documentation, “[it] is a special constant, currently (HANDLE)-1, that is interpreted as the current process handle.” This description indicates that it is possible for a developer to skip the call to kernel32!GetCurrentProcess altogether. If the developer is interacting with the calling process’s handle they can pass (HANDLE)-1 directly to the subsequent function call, which will be advapi32!OpenProcessToken in this case. However, the documentation states that Microsoft reserves the right to change this value, so kernel32!GetCurrentProcess provides a mechanism for programmer to avoid a breaking change.
This means that the “function call stack” for kernel32!GetCurrentProcess is quite simple as shown below:

If you are like me, you might be wondering, “if all kernel32!GetCurrentProcess does is return -1, then how am I supposed to observe that?” We don’t see a syscall. We don’t see a Remote Procedure Call. What should we be looking for? Unfortunately, the answer is that this activity will likely fly below the proverbial EDR radar. Of course one could hook the kernel32!GetCurrentProcess function, but that would probably be quite noisy and attackers can simply skip the call and pass (HANDLE)-1 directly. This is an example, though, that not all functions correspond to operations, and in those cases where they do not we can basically ignore them with respect to our model.
Comparison
Now that we’ve created the respective function call stacks for kernel32!OpenProcess and kernel32!GetCurrentProcess we can compare them to understand the difference between the two routes that Get-ProcessTokenPrivilege affords us. When a Process Identifier is specified to the Id parameter, the Process Open operation is executed, however, if the Id parameter is not specified then the function focuses on the calling process which can be done without a full operation.
OpenProcessToken and GetTokenInformation
After obtaining the handle, both paths converge. We first see, on line 1387, the ProcessHandle that was returned from either OpenProcess or GetCurrentProcess passed as a parameter to advapi32!OpenProcessToken. This is a simple function that opens a handle to the process’s primary token.
Next, on line 1389, we see a call to an internal function called Get-TokenInformation. Notice that the InformationClass parameter is set to “Privileges.” To learn more about the Get-TokenInformation function, we can browse to its source code which is located in the same file, but on line 936. If we look through the functions implementation, we eventually find some conditional branching that is interested in the InformationClass parameter. Remember that Get-ProcessTokenPrivilege passed the string “Privilege” to this parameter? Well on line 1043 we find the section of code that is executed when InformationClass equals “Privileges.”
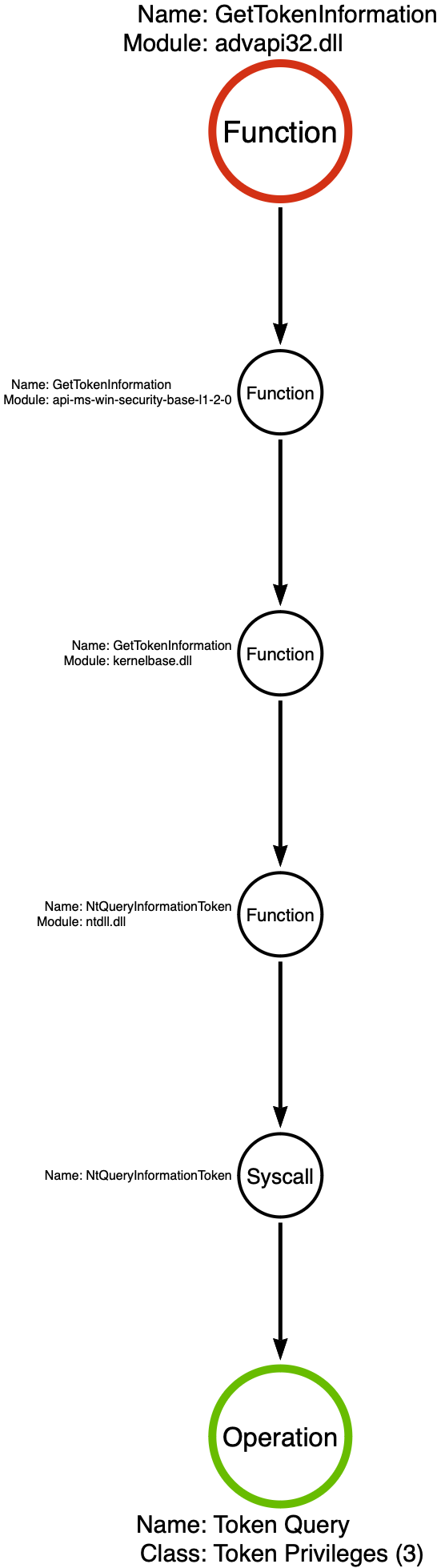
We immediately see two calls to advapi32!GetTokenInformation. This behavior of calling the function twice may seem strange at first, but it is following the function’s intended use case. The problem is that the size of the TOKEN_PRIVILEGES structure is variable, so the first call is to ascertain the size of the structure and the second call is to retrieve the values.
Notice that the second parameter passed to advapi32!GetTokenInformation is 3. This is the information class that corresponds with TokenPrivileges. When you hear information class, you should immediately start thinking about sub-operations. When we dig into advapi32!GetTokenInformation, we find that it eventually calls the NtQueryInformationToken syscall, as expected. This means that we would want to focus on the sub-operation which would be Token Query — TokenPrivileges. I’ve included the function call stack for those following along.
CloseHandle
Finally, we have another fork in the road based on the use of the Id parameter. If the Id parameter was specified by the caller kernel32!CloseHandle is called by the function. If not, the function does not call kernel32!CloseHandle. The reason for this is that the pseudo-handle does not have to be closed explicitly, while the real handle, opened with kernel32!OpenProcess should be.

Operation Chain Comparison
We can now compare the operation chains for the two routes that are afforded to us by Get-ProcessTokenPrivilege. The first path, top, occurs when a Process Identifier is passed to the function via the Id parameter. The Id is meant to specify a target process for whom’s token privileges should be checked. The second path, bottom, more or less represents the default behavior which is focused on the calling process. Notice that these two chains are identical for the middle three operations with the second chain missing the first, Process Open, and last, Handle Close, operations. We know from prior analysis that these differences are minimal in practice, so we should be able to design a detection strategy that handles both situations, given necessary telemetry.
Conclusion
While there are almost certainly better examples of a single parameter drastically changing the function/operation chains that are executed, this is a simple example that demonstrates that a tool cannot simply be described using a single chain. This is why questions like “What does mimikatz do?” are so difficult to answer. The proper response is that mimikatz is a tool that has numerous modules (i.e., sekurlsa, kerberos, dpapi, etc.) which have numerous commands (i.e., logonPasswords, tickets, pth, minidump), which have numerous parameters. Of course these parameters may or may not affect the function chain that is executed, but the idea stands. It is often not possible to describe what a tool does in one succinct answer. Given a specific command line, it is possible to produce the function chain that would be executed. It is also possible to use the module, command, parameter options to map all possible function chains that mimikatz might execute. It is, however, important to understand that using this approach we would be using the command line to derive the function chain which is a more abstract description and is therefore generalizable to many non-mimikatz implementations as well. So we should think of a command line as the beginning of a path to understanding the behavior rather than the end of the detection road.
On Detection: Tactical to Functional Series
- Understanding the Function Call Graph
- Part 1: Discovering API Function Usage through Source Code Review
- Part 2: Operations
- Part 3: Expanding the Function Call Graph
- Part 4: Compound Functions
- Part 5: Expanding the Operational Graph
- Part 6: What is a Procedure?
- Part 7: Synonyms
- Part 8: Tool Graph
- Part 9: Perception vs. Conception
- Part 10: Implicit Process Create
- Part 11: Functional Composition
- Part 12: Behavior vs. Execution Modality
- Part 13: Why a Single Test Case is Insufficient
- Part 14: Sub-Operations
- Part 15: Function Type Categories
Part 16: Tool Description was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.