Crypto Census: Automating Cryptomining Domain Indicator Detections
Why does Crypto Census Exist?
In recent years, cryptojacking attacks have seen a dramatic rise in prevalence. In 2021 alone, CrowdStrike observed a four-fold increase in these types of attacks. To compound this threat, cryptojacking is insidious by nature. These attacks do not actively seek to damage systems or access sensitive data and allow attackers to profit as long as they remain undetected. This encourages threat actors to develop stealthy malware that exhibits behavior almost indistinguishable from benign applications. Thus, organizations face great difficulty generating well-crafted behavior-based detections and often focus more heavily on brittle, indicator-based defenses.
One common detection strategy involves observing outbound DNS queries or requested URLs to flag communications involving known cryptomining destinations. These detections are easily created and provide protection against less sophisticated attacks. However, the quality of these alerts depends heavily on the quality of the indicators selected. Thus, organizations which use such detections face two issues:
1. Sourcing accurate, up-to-date indicators
2. Maintaining the indicators
Crypto domain IOC lists are easy to come by, but identifying the source of any list is often an exercise in futility. Without understanding how the indicators were selected for the list, the accuracy of the list cannot be confirmed.
Additionally, many of the open-source crypto domain IOC lists are months, if not years, out of date. As the value of an indicator generally decreases over time, these lists may not provide coverage against emergent crypto domains.
My search for a fully open-source, self-maintaining, crypto domain indicator list led me to the creation of Crypto Census.

The Theory Behind Crypto Census
Cryptomining operations seek visibility. Crypto organizations, such as crypto pools, crypto coins, and crypto exchanges, generally see increased profit with increased users. Thus, they are incentivized to actively publicize themselves and other crypto tools they associate with. This behavior enables the enumeration of most, if not all, publicly advertised crypto-related sites through web crawling. Crypto Census uses term-based text classification to identify crypto sites, and capitalizes on this behavior to create a list of crypto-related sites.
Using Crypto Census
Crypto Census generates a text list of crypto-related domains as an output. As most cryptomining pools share root domains with other components in crypto operations, detections or deny lists built from this list greatly reduce the number of crypto pools available to any attacker.
As Crypto Census uses a term-based classification system, false positives are expected. Thus outright blocking or alerting on traffic destined to the domains from Crypto Census’ output is not recommended for networks where user web activity is a normal occurrence. Instead, the Crypto Census output is most effectively integrated when these domain indicators are combined with other indicators. Such detections include:
Suspicious Executable Followed by Connection to Crypto Domain
This detection would combine Crypto Census’ domain indicators with Carbon Black’s cryptomining filepath indicators to create a higher-fidelity detection for active cryptojacking operations.
Alert when:
File or process event
Where file path contains one of [\streamerData\, \streamer\, \cpuminer.exe, xmrig.exe, \mvlover\, \cpuchecker.exe, \newcpuspeedcheck\, C:\Windows\Taskhost.exe]
Followed by within 5 minutes
One network traffic event
Where requested domain ends with any of [domains in cryptomining_domains.txt]
Crypto Pool Beaconing
Cryptominers require constant communications with their crypto pools to submit their work and obtain mining jobs. Repeated requests to known crypto-related domains over time could indicate a coin miner is actively beaconing to a cryptomining pool.
Alert when:
5 or more network traffic events
Where requested domain ends with any of [domains in cryptomining_domains.txt]
AND
Where each event is seperated by 5 minutes
High Resource Usage Followed by Crypto Connection
High CPU or GPU utilization is an unavoidable behavior of cryptojacking. Although resource utilization detections can be hard to fine-tune, adding crypto domain indicators to high resource utilization alerts can generate higher-fidelity cryptomining detections. Note that such a detection augments, but does not replace the need for high resource utilization alerts.
Alert when:
(Abnormally high CPU usage event) OR (Abnormally high GPU usage event)
Followed by within 5 minutes
One network traffic event
Where requested domain ends with any of [domains in cryptomining_domains.txt]
Crypto Connection Over Common Mining Port
Cryptominers commonly use the same port when communicating with crypto pools. Crypto Census’ domains can be combined with common mining port detections to monitor for potential cryptojacking activity. The ports from this detection psuedocode come from Falco’s list of common mining ports.
Alert when:
One network traffic event
Where dest_port is one of [25, 3333, 3334, 3335, 3336, 4444, 5555, 5556, 5588, 5730, 6099, 6666, 7777, 7778, 8000, 8001, 8008, 8080, 8118, 8333, 8888, 8899, 9332, 9999, 14433, 14444, 45560, 45700]
AND
Where requested domain ends with any of [domains in cryptomining_domains.txt]
Tool Caveats
Crypto Census is not meant to be used as the sole cryptojacking defense in your environment. The list generated by this tool contains only subdomains of publicly broadcasted crypto operations and will not protect against relayed attacks, attacks that do not involve URLs, or attacks using private crypto infrastructure. The tool is meant to provide detection developers a layer of defense against unsophisticated cryptojacking operations and should be used in conjunction with other cryptojacking detections. Behavioral-based detections which target broader cryptojacking techniques, such as baselining and monitoring asset resource consumption for abnormal usage, are especially effective, as these detections are higher on the pyramid of pain and are significantly more difficult to evade.
Crypto Census should re-run on a at least a monthly basis to prevent the Crypto Census domain list from becoming stale. Stale indicator lists reduce the reliability of detections, thus leaving gaps in your defenses.
How does Crypto Census Work?
Crypto Census starts with a list of known crypto sites and crawls HTML <a href> links to search for crypto-related webpages. Each webpage Crypto Census classifies as crypto-related is then scraped for domain-like strings. The tool then queries the scraped domains to identify and log crypto-related domains.
Let’s break the tool down to its main components:
1. Web Crawler
2. Subdomain Validator
3. curl Handlers
4. Term Checker
5. Configuration Options
Web Crawler
The Web Crawler is responsible for identifying and crawling HTML crypto webpages. This component is comprised of the following:
1. HTML Validator
2. Term Checker
3. Link Extractor
4. Subdomain Extractor
The Web Crawler finds and passes all HTML <a href> links to a curl handler and checks the site data curl returns for crypto-related terms. If a site is classified as crypto-related, all links on this new site are passed back into the Web Crawler. Additionally, a positive crypto classification will cause the Web Crawler to pull all domain-like strings from the site to pass to the Subdomain Validator to identify crypto-related subdomains.
HTML Validator
The HTML validator is responsible for confirming the site data returned by curl is HTML data. The validator first checks the data to confirm the data size is non-zero, then checks for a HTML <!DOCTYPE> declaration. If the tag does not exist, the site data is discarded.
Term Checker
After confirming curl has returned HTML data, the document is passed to the Term Checker component to determine whether the site contains sufficient terms to be classified as crypto-related. If the site contains insufficient terms to meet such a classification, the site data is discarded.
Link Extractor
If a site has been classified as crypto-related, the Web Crawler uses regex to pull web links. These extracted links are then passed to the Web Crawler’s curl handler for further queries. The regex serves three purposes:
1. Identify web links
2. Isolate domain portion of the link
3. Filter out URL parameters from links
<a[^h>]*href=\”(([^:\/]*:\/\/([^\/”:?]+)|\/)[^”&=>#?]*)
Let’s break this regex down:
<a[^h>]*href=\”
The expression anchors on any anchor tag (<a>) it identifies, then reads until it finds the href attribute, or the end of the anchor tag. The expression then reads up until the start of the href attribute’s value.
(([^:\/]*:\/\/
The expression then begins a capture group for the URL and consumes the link’s protocol (ie: http://).
([^\/”:?]+)
If a protocol exists, the expression then creates another capture group to record the subdomain of the URL. The regex then reads until it finds the end of the domain portion of the URL.
|\/)
This logic handles the case of self-referencing links.
[^”&=>#?]*)
The expression continues to read until it hits the URL attribute’s end character “, or a character indicative of a URL parameter. Parameter characters include &, =, >, #, and ?. This logic exists to ensure the Web Crawler does not get stuck crawling the same webpage or webpages with little to no value to the Web Crawler.
To mitigate the risk of DoS conditions, the Web Crawler limits the number of webpages it pulls from any given subdomain. By default, the Web Crawler restricts the number of requests per subdomain to 150, but this option is configurable (see below). Additionally, to prevent stalling on any given webpage, the Web Crawler by default restricts the number of links it extracts from any webpage to 1000 links. Links with subdomains on the user-supplied exclusion list do not get crawled, and any such links found during link extraction are ignored.
Subdomain Extractor
Like the Link Extractor, the Subdomain Extractor uses regex to examine crypto-related webpages. This regex filters for any strings that appear to contain domains.
[^\w\.\-]([\w-]+?\.(([\w-]+?\.)+)?([a-zA-Z]+|XN--[A-Za-z0-9]+))
Let’s also break down this expression.
[^\w\.\-]
The expression first anchors on any character that cannot be part of a valid domain name.
([\w-]+?\.
The expression then captures until it encounters the character .. The captured string represents the leftmost part of the domain.
(([\w-]+?\.)+)?The regex then continues consuming additional potential subdomains and the domain.
([a-zA-Z]+|XN--[A-Za-z0-9]+))
The expression finally finishes by capturing characters representative of a TLD (Top Level Domain).
The Subdomain Extractor then checks each extracted domain’s TLD against the IANA list of known TLD’s. To increase the fidelity of the regex, the Subdomain Extractor ignores any extracted domain that is followed by the character (. This prevents the extractor from misinterpreting script functions as domains. Additionally, any domains on the user-supplied exclusion list are ignored by the Subdomain Extractor.
All validated domains are passed to the Subdomain Validator.
Subdomain Validator
Term-based site classification is prone to misidentifying sites. For example, if a news article were to contain sufficient terms to trigger a crypto classification, the Web Crawler would treat the entire subdomain as a crypto site. The Subdomain Validator is tasked with increasing the fidelity of the crypto classifications. The validator accomplishes this by pulling HTML data from the root of the subdomain. If this HTML data contains sufficient crypto-related terms, the subdomain is classified as a crypto site. This validation process filters out most news agencies, search engines, forums, and other content hosting platforms.
Like the Web Crawler, the validator uses curl to make web requests, then uses the Term Checker component to identify crypto terms. Any subdomains classified as crypto-related are written to output.txt. Crypto Census focuses on subdomains, as opposed to domains, as this allows for more granular classifications.
curl Handlers
Crypto Census is built on top of two curl handlers, one for the Subdomain Validator, and one for the Web Crawler. These handlers use the libcurl multi interface to manage asynchronous web requests. The handlers accept URLs via input queues and output the site data via output queues. By default, Crypto Census uses the following libcurl configurations when making web requests:
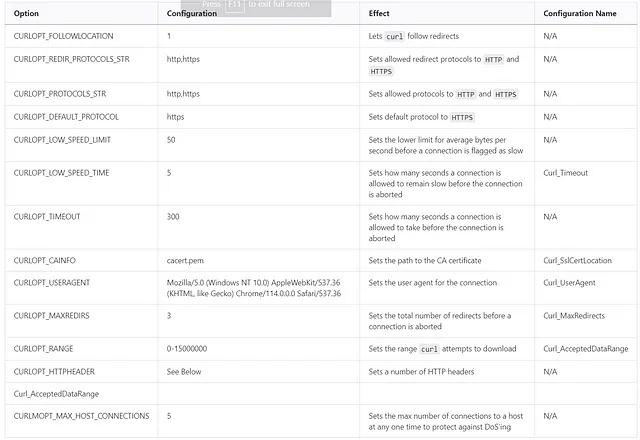
Additionally, to encourage more sites to accept requests from Crypto Census, the following HTTP headers are sent with every request:

When a curl handler receives site data, it stores the data as a vector of strings in a siteData struct. Each string contains a max of 100,000 characters. This boosts the efficiency of string and regex operations when processing larger websites.
The Web Crawler and Subdomain Validator curl handlers can theoretically support as many concurrent connections as your computer will allow. By default, the Web Crawler is allowed up to 1,000 connections, and the Subdomain Validator is permitted up to 2,000 connections. Both numbers are configurable, but for every Web Crawler connection, two connections should be allocated to the Subdomain Validator. This prevents excessive RAM usage.
Term Checker
The Crypto Census Term Checker component is used to discern between crypto and non-crypto sites. Terms are stored in terms.txt and are delineated by the newline character. When Crypto Census attempts to classify a webpage, it will search the whole webpage for each term found in terms.txt, until it finds enough unique terms to classify the site as a crypto-related or runs out of terms to check. These checks are not case sensitive. The number of unique terms used in the classification is determined by the configuration TermMatcher_NumRequiredTerms. For the best results, use the default TermMatcher_NumRequiredTerms setting and the terms.txt list found in the GitHub. If you wish to provide your own terms, supply a large number of terms to terms.txt, and set TermMatcher_NumRequiredTerms to 5 or more.
Required Configurations
Terms
Crypto Census uses terms from terms.txt in both the Web Crawler and Subdomain Validator to classify sites as crypto-related. Crypto Census will check each webpage for each term supplied in the terms list. This terms list must exist in the same directory as the Crypto Census executable under the filename terms.txt. Terms are not case sensitive, but must be line-delineated.
Initial Domains
The tool must be provided an initial list of subdomains. These subdomains are passed to the Web Crawler to kick off the crawling process. This initial list is read from a sources.txt file in the same directory as the Crypto Census executable. The subdomains are line delineated and case sensitive. Examples of acceptable subdomain syntax includes:
• domain.com
• subdomain.domain.com
• uk.subdomain.domain.com
For the best results, each supplied subdomain should contain a large number of links to other crypto sites. Additionally, users should try to include a variety of sites to the Web Crawler. Crypto exchanges make for great sources.
Optional Configurations
Exclusions
Term-based classification is prone to false positives. Crypto Census allows users to explicitly exclude subdomains from any querying. These line-delineated subdomains are pulled from the exclusions.txt file in the same directory as the Crypto Census executable. Exclusions are case sensitive. Additionally, excluding a root domain will not exclude all subdomains.
Examples of acceptable excluded subdomain syntax includes:
• domain.com
• subdomain.domain.com
• uk.subdomain.domain.com
TermMatcher_NumRequiredTerms
This number determines how many unique crypto terms from terms.txt Crypto Census must find from any given webpage before it classifies the page as crypto-related.
Crawler_MaxExtractedLinksPerPage
Crypto Census uses this config to determine the maximum number of links to crawl for each page.
Crawler_MaxRequestsPerDomain
Crypto Census uses this config to restrict the total number of requests made for any given subdomain. This config is meant to prevent accidental DoS’ing.
Crawler_MaxConnections
This integer determines the max number of active connections the Web Crawler curl handler is allowed to have at any given time.
Searcher_MaxConnections
This integer determines the max number of active connections the Subdomain Validator curl handler is allowed to have at any given time. To prevent high memory usage, Searcher_MaxConnections should be at least twice as great as Crawler_MaxConnections.
Curl_UserAgent
Crypto Census uses the string provided in this configuration as the user agent for all connections.
Curl_SslCertLocation
This configuration determines the path of the SSL certificate used by curl. For example, if a value of cacert.pem is provided, Crypto Census will attempt to look for the SSL certificate cacert.pem in Crypto Census’ working directory.
Curl_AcceptedDataRange
This integer configuration determines the max amount of data accepted by curl.
Curl_MaxRedirects
This configuration determines the maximum number of redirects curl will follow before the connection is aborted.
Usage Warnings
Crypto Census indiscriminately pulls data from sites with unknown reputations. The tool should not be executed within the trusted network.
The Crawler_MaxRequestsPerDomain setting is designed to prevent DoS conditions. If the user supplies too high a number, Crypto Census is likely to flood crypto-related sites with requests.
The Subdomain Validator is expected to pursue a large of sites during the validation process. Thus, Searcher_MaxConnections should be set to twice that of Crawler_MaxConnections.
If the tool begins consuming excessive system resources, try reducing the following options:
Curl_BytesToReadCrawler_MaxExtractedLinksPerPageCrawler_MaxConnectionsSearcher_MaxConnections
If the tool’s RAM usage balloons, it’s likely the Subdomain Validator has not been allocated enough connections.
Planned Changes
Crypto Census is currently in alpha testing. These are a few of the planned changes:
• Better DoS prevention mechanisms
• Root domain exclusions
• Pooled curl connections