LLMentary, My Dear Claude: Prompt Engineering an LLM to Perform Word-to-Markdown Conversion for Templated Content
TL;DR While LLMs can expedite parts of the technical writing/editing process, these tools still require human oversight and guidance to provide an accurate and helpful response.
Overview
Every report SpecterOps releases to a client goes through a stringent quality assurance (QA) process. As our in-house Technical Editor, I’m always the first step in that process. These reports contain (but are not limited to) the following sections:
- Findings – Vulnerabilities our assessment team uncovered that could cause damage if the affected organization does not mitigate them
- Positive Observations – Strengths our assessment team observed that partially or completely prevented their attack path
- Narratives – Steps our assessment team performed related to achieving assessment objectives
Our reports contain other sections, but these three are special because the content within them could appear in other assessments. SpecterOps maintains a library of findings, positive observations, and narratives our operators suspect they’ll encounter again so that they can manipulate a templated version versus writing the entire thing from scratch every time.

Once a report enters QA, I ask the writer and assessment lead whether they believe any of the narratives, observations, and (most commonly) new findings could appear in future assessments or if they are too client-specific to warrant capturing. If we decide to add them to our reporting library, I:
- Save a copy of the finalized report as the Assessment Number (e.g., PT-250612)
- Remove everything in the document except the library candidate content
- Sanitize the content to remove client-specific information (e.g., pod names, client names, user and domain names, etc.)
- Create a GitHub Enterprise issue with the assessment number as the title, attach the document, and assign it to a Service Architect for review
- Review the issue in the monthly Documentation Meeting for final approval
- Manually convert the Word content to Markdown content
- Add the content to a GitHub branch and submit a pull request so we can forward the content to Ghostwriter (our report writing software)
Unfortunately, as with all manual processes, Step 7 runs the risk of human error. For instance, Ghostwriter doesn’t like trailing spaces after periods on the end of a line. Since spaces are invisible (unless you show paragraph marks and other formatting symbols in Word), you might not catch that—or, perhaps, forget to list a programming language when converting a code block to fenced code.

Several of my coworkers released blogposts and whitepapers regarding their own adventures with large language models (LLMs) this year, so I figured I’d conduct my own experiments from the perspective of a technical editor. Could I, for example, prompt an LLM like Claude or ChatGPT to convert the Word versions of these findings into Markdown so I won’t have to manually format them?
The short answer is yes…but with caveats. Although the LLM I used (which came from Microsoft at https://github.com/microsoft/markitdown/tree/main/packages/markitdown-mcp) eventually gave me what I wanted, I ran into some “hiccups.” The next few sections document my experiments.
Experiment 1: Proofreading a Manually Converted Finding
For my first example, I gave the LLM a finding that I already attempted to convert to Markdown. For my prompt, I shared the following:
You are a kind and helpful developer assisting a technical writer with changing the contents of a Microsoft Word document into a Markdown format. If I provide the template, as well as an example, I would like assistance in the following ways:
- The portions marked with a # need to remain in the same order
- Keep all italics, bold, and other formatting as it appears in the example, but convert to Markdown styling
- Remove Markdown errors, such as trailing spaces at the ends of lines
Could you assist me with this?
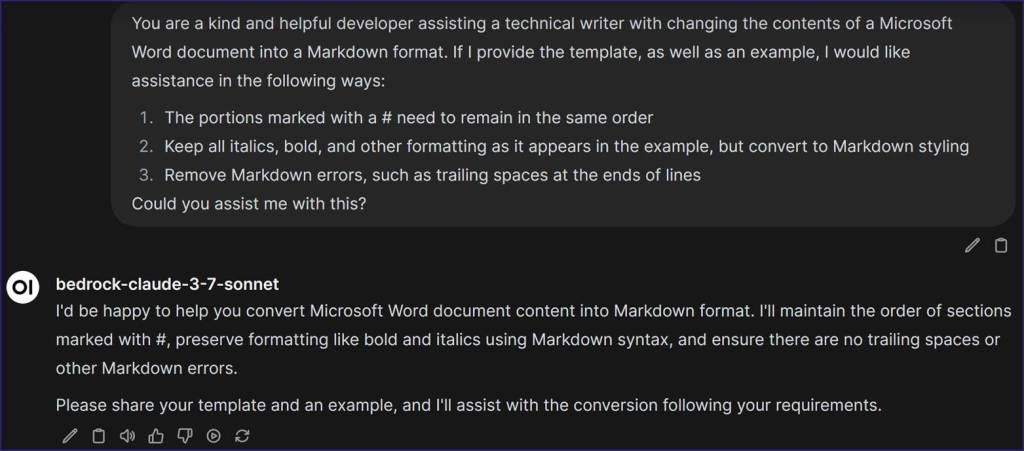
Our internal chatbot, which used AWS Bedrock and Claude 3.7 Sonnet, replied that it could assist me with this request. I then submitted the template on top (Note: The #s from my entry disappeared because the chatbot read it as a heading, just like in Markdown) and the finding I manually converted (i.e., “Insufficient Network Segmentation”) beneath it.

The LLM returned a similar response—verbatim, almost, save for some small changes. Can you see them? It took me a moment to spot the differences, so feel free to take some time.

When I asked the LLM what errors it located and resolved, it returned the following response:

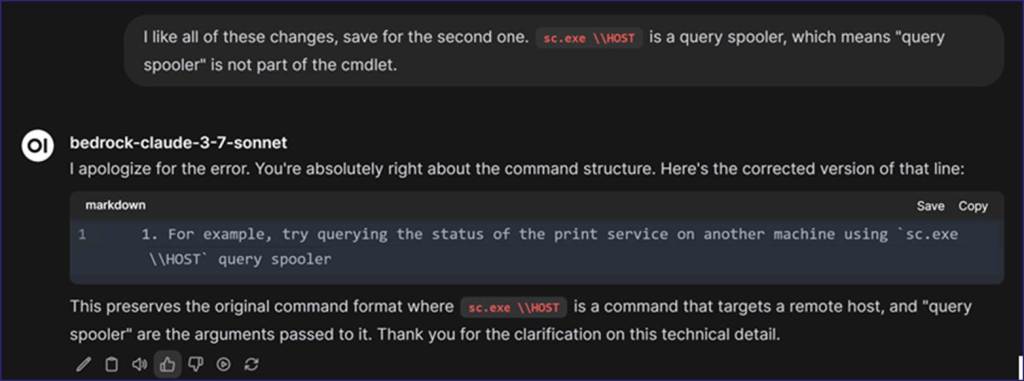
I’m happy with every change the LLM made except for the second one. The cmdlet it changed (i.e., sc.exe \\HOST) is a query spooler, which means it is a category versus a part of the code. I stated this to the LLM and received the following response:
A few other tests contradicted our Style Guide (e.g., changing file names from italics to inline code), so I’ll be sure to double-check the LLM when it converts findings. Let’s go ahead and proceed with Experiment 2: Will the LLM remember the template if I give it a different finding?
Experiment 2: Proofreading a Second Manually Converted File (With Mistakes) on the Same Conversation
Jumping straight from Experiment 1, I gave the LLM a different manually converted finding (i.e., “Insufficient Multi-Factor Authentication”) to see if it still followed the template I provided in my first example. I also deliberately added some known Markdown errors to see if the LLM would catch them. Specifically, I:
- Kept “— Low” on the same line as the “severity” heading
- Kept the bulleted list for “references” in the Word format
- Removed the “host detection techniques” and “network detection techniques” sections because this finding had neither

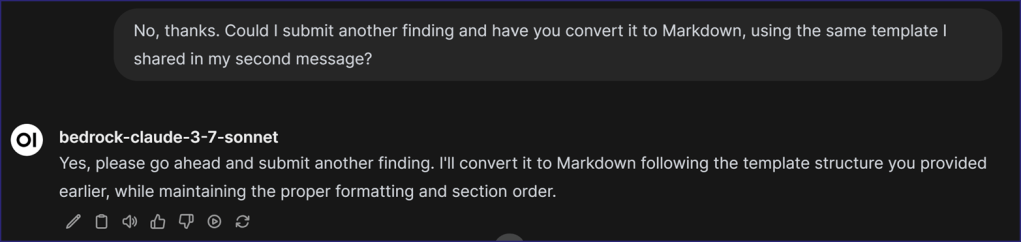
The LLM returned the following response, which I instantly noticed did what I hoped it would:

I asked the LLM to summarize the changes and received the following response:
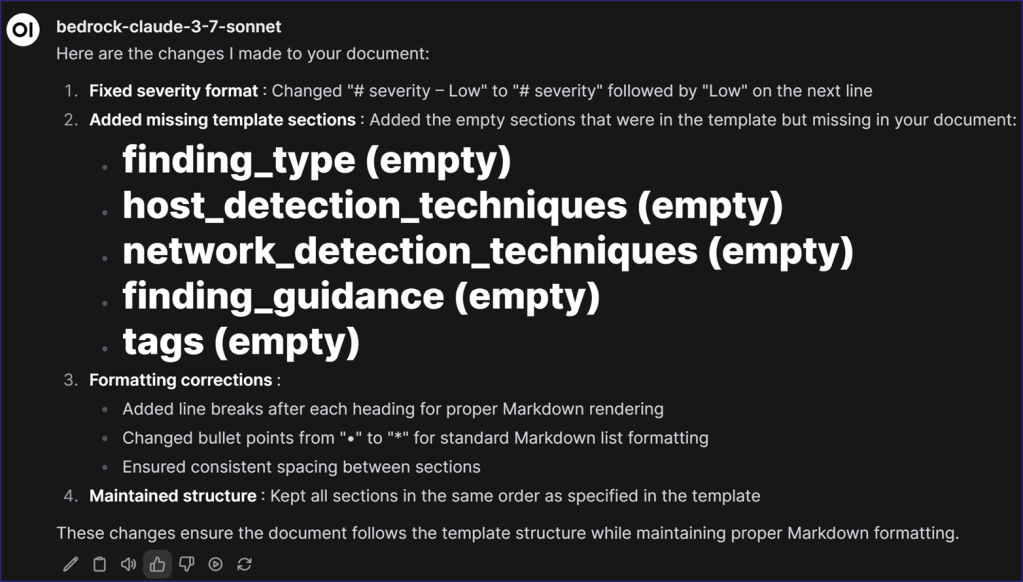
I was delighted that the LLM caught every “mistake” I tried to throw at it, but I wasn’t ready to let it off the hook. Instead, I threw a second example finding (i.e., “Insecure Password Storage Methods”) at it; this time with more complicated “mistakes.” Specifically, I:
- Omitted the space between “#” and “title”
- Kept “— Medium” on the same line as the “severity” heading
- Omitted the “id”, “finding_type”, “findings_guidance”, and “tags” headings
- Did not remove a heading that appears in our reports but not in our findings template (i.e., “Affected Entities”)
- Randomly entered programming languages for the fenced code examples, as our reports do not provide that information
- Did not provide a language at all for one fenced code example
- Left the bulleted list in Word format versus converting it to Markdown
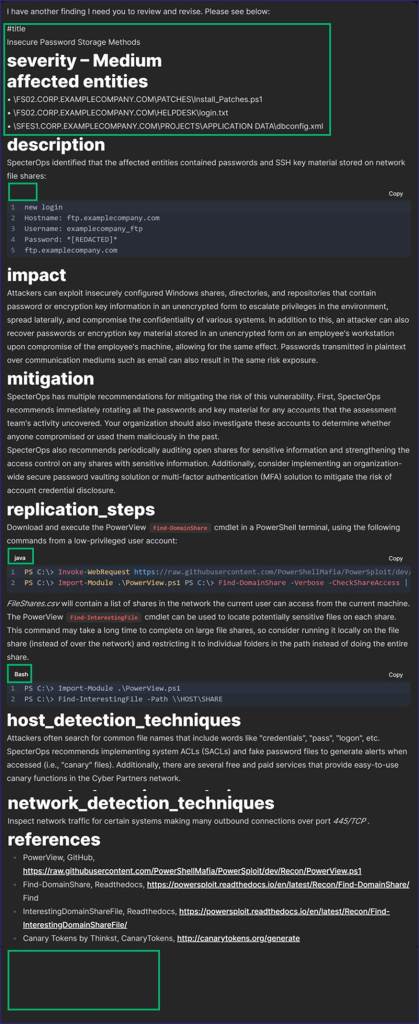
Not only did the LLM fix my “mistakes,” but it also changed the coding language for the fenced text.
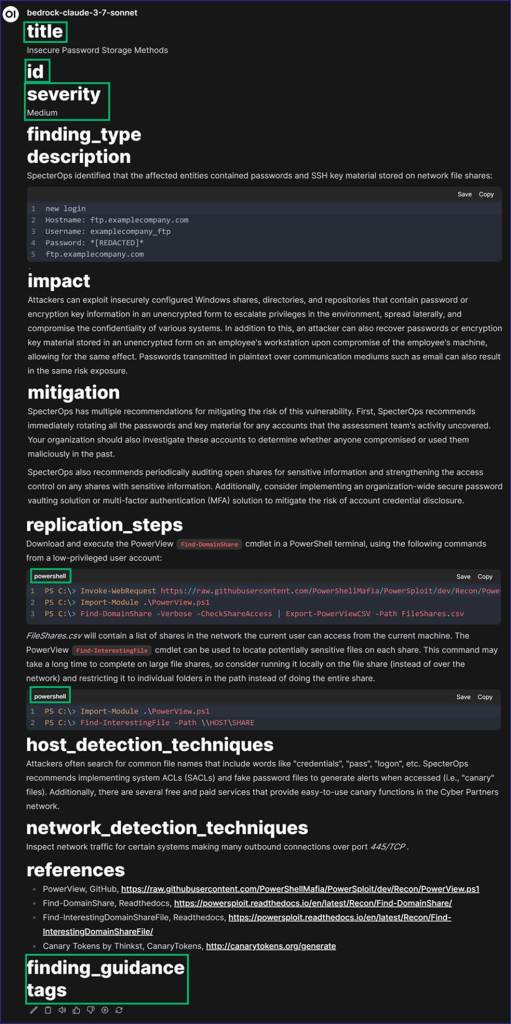
That caught my interest, so I asked the LLM to list and explain its changes. This time, it also managed to catch something I didn’t notice: a spacing issue with one of the reference URLs.
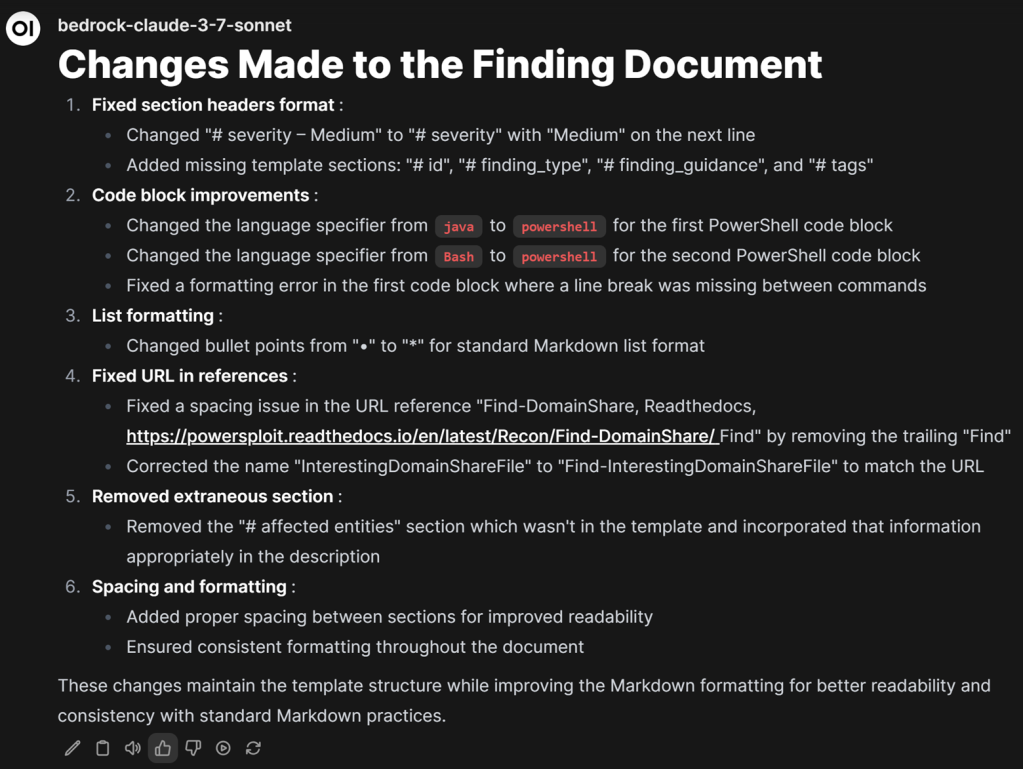
What caught my attention most was how the LLM changed my fenced text language to ““`powershell”. When reports come to me in Word format, we typically don’t capture which coding language they’re in. Below is an example of what I typically see, so I (or a Service Architect) have to guess the code when converting findings:

I guess this means I’ll need to submit a PR to get those coding languages changed! Whoops!

Experiment 3: Proofreading a Finding That is Still in Word Format
Jumping straight from Experiment 2, I decided to test how well the LLM converted a finding that was still in the Word format to Markdown.
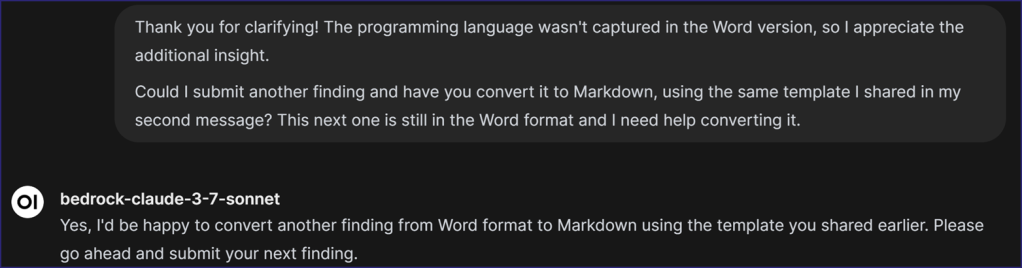
In this example, my copy-paste from the Word file did not have any of the Markdown formatting.

The LLM returned a good response, but I noticed a few things that did not conform to our Style Guide. Specifically:
- We italicize host, user, domain, and forest names
- Our reports list “Affected Entities” before “Description” (but they do not appear in the templated version, as those will vary from assessment to assessment)
The LLM also forgot to add a programming language to the fenced code in the “Mitigation” section.
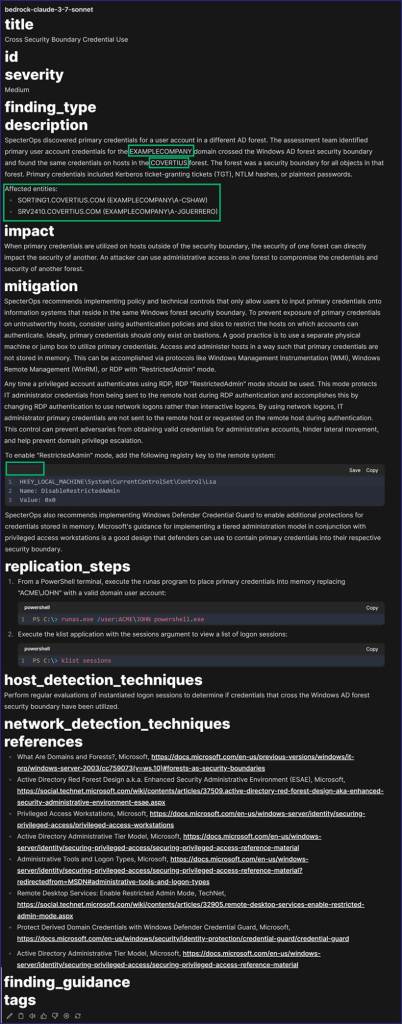
I provided this feedback to the LLM, requested that it make those changes, and also asked it to categorize the finding as either Network, Cloud, Mobile, Host, Physical, Web, or Wireless and explain why it chose that category.
Two things of interest happened. First, the LLM made my requested changes. As you can see below, it italicized host, domain, and forest names.

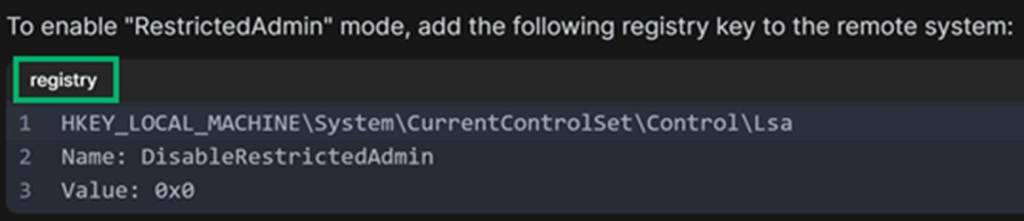
It also classified the language for the fenced code in the “Mitigation” section as “registry”.
And secondly, it classified the finding as a “Host” type. I asked it to walk me through how it came to that decision and received the following response:
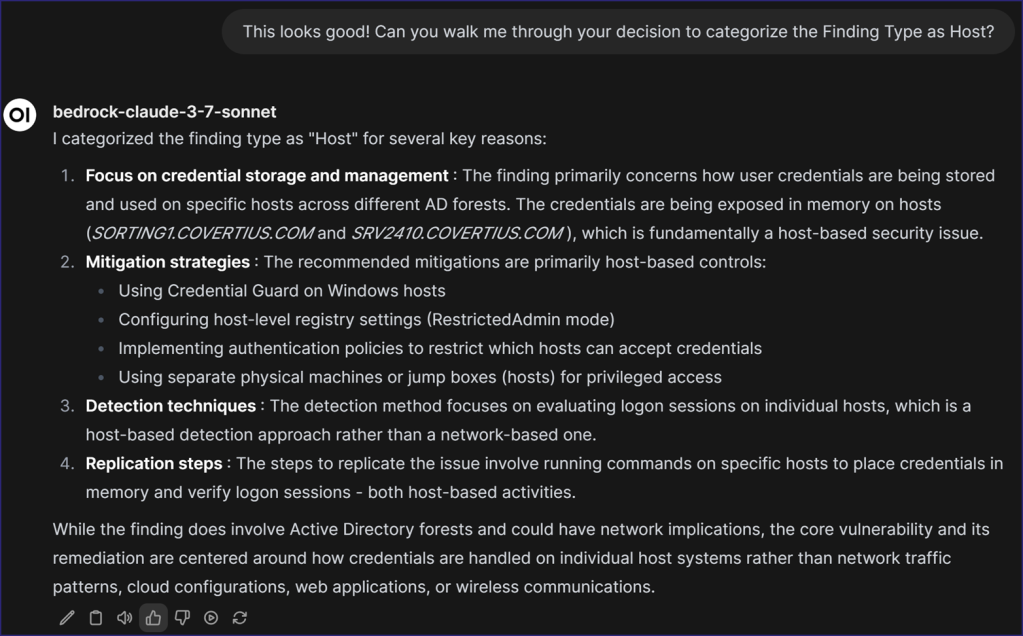
In reports, “Finding Type” has the opposite problem of “Affected Entities”; specifically, it’s something we use in the backend to organize our findings, but it doesn’t appear in reports. With the current process, it’s something that the Service Architect determines during their review. By using the LLM, I can save them that step and pre-classify findings without them!
But remember what I said about the Style Guide, and how the LLM didn’t follow it? That was because I “forgot” to share it. Let’s now proceed to Experiment 4 and see what happens once we give the LLM the context of the Style Guide.
Experiment 4: Uploading the Style Guide (Just to See What Happens)

While writing this article, I shared some of the memes with my coworkers and one of them suggested uploading the Style Guide to see if the LLM would follow it. I copy-pasted our Style Guide, created a .docx document called Style Guide File for LLM.docx, and uploaded it to our LLM. Then, just to make things interesting, I requested that the LLM follow the below stipulations:
- Re-review the finding in Experiment 3
- Adhere to the same template we used at the beginning of our chat
- Adjust the finding to better fit our Style Guide
Let’s see how well it does!
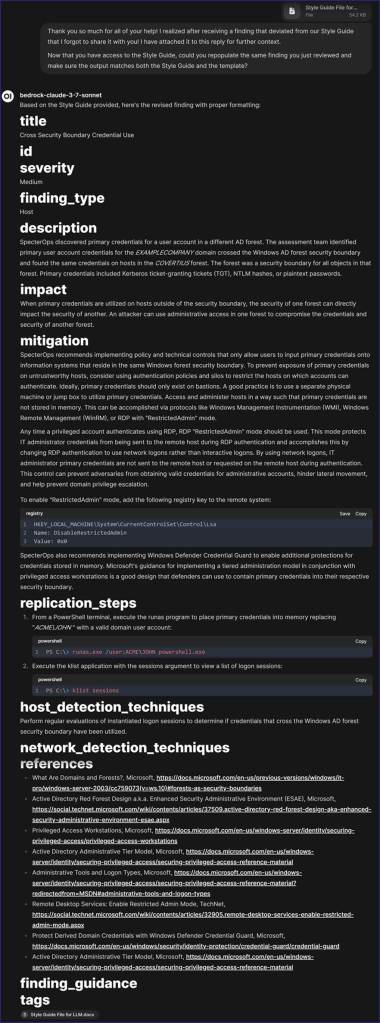
So…how did the LLM do? This time, extraordinarily well! I practically have our Style Guide memorized, so I reviewed the LLM’s changes and was pleased to see it complied 100%!
Unfortunately, upon copy-pasting the finding in GitHub, I realized that the hashes, asterisks, and other characters Markdown uses to indicate headings, italicize, or perform other actions did not transfer over. I asked the LLM to convert the content with the hashes and other characters visible so Markdown would understand it and received the following response:
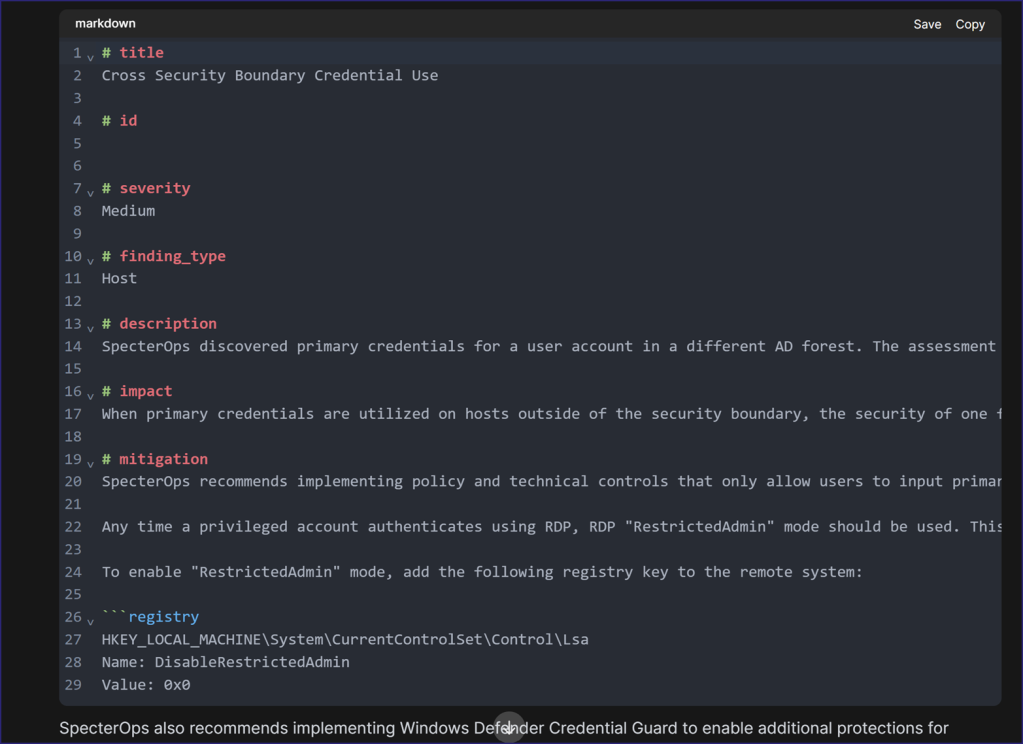
The LLM helped up to a point but hit a “snag” once it reached the fenced code in the “Mitigation” section. I attempted two to three refreshes, communicated the issue, and the LLM continued to make the same mistake. This may require some further testing, but I confirmed with other findings that the LLM parsed Word to Markdown just fine; this appeared to be an outlier.
Conclusion (i.e., “How Helpful was the LLM?”)

Earlier this year, I took Cherryleaf’s Using Generative AI in Technical Writing course and, beyond providing an expansive high-level dive into dozens of different AI/ML tools technical writers and editors can use to make their jobs easier, the course’s greatest takeaways were as follows:
- LLMs can dramatically reduce the amount of time writers spend on brainstorming and drafting, but they may hallucinate and return inaccurate results
- Even if the LLM does not hallucinate, it returns the most statistically probable answer versus a guaranteed accurate one
- To ensure the final draft is correct (and adheres to the correct parameters), writers (and SMEs working alongside writers) should always double-check LLM outputs
- Most importantly, even though LLMs are helpful and useful tools, security professionals like SpecterOps need to assume by default that (unless otherwise specified) clients do not consent to their data being submitted to LLMs; always check your organization’s data security policies prior to using LLMs (or, at the very least, make a conscious effort to sanitize/genericize data prior to submitting it)
In short, LLMs are an absolute boon when used correctly but require some handholding and human oversight to ensure you aren’t creating something inaccurate, false, or even potentially illegal. That bot may be your copilot, but it is still a writer’s duty to pilot.