Lost in Translation: How L33tspeak Might Throw Sentiment Analysis Models for a Loop
TL;DR Sentiment analysis models are used to assess conventional use of language, but what happens when you engage with them using l33tspeak?
If you’ve been in the security space for some time, you may be familiar with l33tspeak, or 1337, where you replace letters with visually similar words or symbols that resemble the original letters. What if we employ this in adversarial text attacks against AI models? For example, typing “5p3ct3r0p5” instead of “SpecterOps” when passing a prompt would result in a visually similar word that, to a model, is not the same word. This carries weight, especially in the sentiment analysis space, where the paper “TextBugger: Generating Adversarial Text Against Real-world Applications” comes into play. In their research, Li et al show how text manipulations such as this one result in reduced accuracy when it comes to text classification. An interesting example is sentiment analysis for product and comment reviews.
Here’s a hypothetical example:

In this simulated example, the original text is intact and conveys a negative opinion about the stance presented in a book. In the adversarial prompt, 1337speak replaces the strongest words or “tokens.” The model is unable to interpret these values as the words they replaced and therefore cannot perform accurate sentiment analysis. To the average reader, the negative sentiment is still conveyed; However, the model cannot accurately process these tokens with the appropriate values and therefore misclassifies the review as positive.
Who is BERT?
For those who are unaware and before we proceed with testing, I want to elaborate a bit on BERT. BERT, or Bidirectional Encoder Representations from Transformers, is a natural language processing model that has been developed by Google since 2018. Many language models have encoding and decoding features, but BERT only employs the former unless specified, indicating the prioritization of only ingesting and comprehending language as opposed to generating it. The bidirectional aspect of BERT means that, as opposed to ingesting and contextualizing words sequentially and going from left to right to do so, BERT will assess the words to the left and right of the word it is assessing in order to enrich its context. Most relevant to this research is how BERT was trained: BERT was pre-trained on all of Wikipedia’s content as well as the content in the Brown Corpus, the first computer-readable compilation of modern English. BERT continues to learn via unsupervised learning, meaning the data it is provided is unlabeled and BERT must learn on its own without human guidance, and can be fine-tuned to meet its users needs. Some of the models I cover later in this blog post are branches off of BERT that have been fine-tuned to meet specific requirements set forth by the user.
L33t in Action
I decided to test some of this on my own and see how susceptible some of the sentiment analysis models available on HuggingFace are. For reference, I followed HuggingFace’s blog post by Federico Pascual on how to implement testing using Python and PyTorch (found here: https://huggingface.co/blog/sentiment-analysis-python). My initial batch of code looked like this:
| from transformers import pipeline sentiment_pipeline = pipeline[“sentiment-analysis”] data = [“I strongly disagree with the opinion presented by the author in this book: there was definitely enough room for both Jack AND Rose on that piece of wood”, “I str0ng1y disagr33 with the opinion presented by the author in this book: there was d3finite1y en0ugh room for both Jack AND Rose on that piece of wood.”] print(“Model: DISTILBERT”) print(sentiment_pipeline(data)) |
This employs the default sentiment analysis model distilbert/distilbert-base-uncased-finetuned-sst-2-english and the initial results looked like this:

So, out the gate, it looks like distilbert is not really susceptible to sentences where the sentimentally strongest tokens are converted to l33tspeak. I decided to add a few more models and see how it went:

These results were interesting for the following reasons:
- For the purposes of this test, distilbert is pretty ironclad with consistency
- Bertweet seems slightly susceptible, being that it categorized the original prompt as negative and the l33tspeak prompt as neutral
- Some models have limits, possibly impacted by choice in training sets or their size; the Google Play Sentiment Analysis model rated both prompts relatively close to each other, but didn’t find the original prompt to be negative
¿Hablas l33t?
As I browsed HuggingFace, I quickly caught onto the fact that the sentiment analysis models available seem to be trained to specific languages. I picked three Spanish language models and created a data set of my original prompts translated into Spanish with the same sentimentally strong words converted into l33tspeak. My code snapshot is below:
| from transformers import pipeline sentiment_pipeline = pipeline[“sentiment-analysis”] data = [“I strongly disagree with the opinion presented by the author in this book: there was definitely enough room for both Jack AND Rose on that piece of wood”, “I str0ng1y disagr33 with the opinion presented by the author in this book: there was d3finite1y en0ugh room for both Jack AND Rose on that piece of wood.”] esp_data = [“Estoy indudablemente en desacuerdo con la opinion presentada por el autor de este libro: definitivamente habia suficiente espacio para Rose Y TAMBIEN Jack en ese pedazo de madera.”, “Estoy indudabl3m3nt3 en d3sacu3rd0 con la opinion presentada por el autor de este libro: d3finitivam3nt3 habia sufici3nt3 espacio para Rose Y TAMBIEN Jack aen ese pedazo de madera.”] print(“Model: DISTILBERT”) print(sentiment_pipeline(data)) specific_model = pipeline(model=”finiteautomata/bertweet-base-sentiment0analysis”) print(“Model: Bertweet Base Sentiment Analysis”) print(specific_model(data)) add1_model = pipeline(model=”danielribeiro/google-play-sentiment-analysis”) print(add1_model(data)) esp1_model = pipeline(model=”VerificadoProfesional/SaBERT-Spanish-Sentiment-Analysis”) print(esp1_model(esp_data)) esp2_model = pipeline(model=”ignacio-ave/beto-sentiment-analysis-Spanish”) print(esp2_model(esp_data)) esp3_model = “pipeline(model=”UMUTeam/roberta-spanish-sentiment-analysis”) print(“Model: RoBERTa Spanish Sentiment Analysis”) print(esp3_model(esp_data)) |
The results were all over the place:
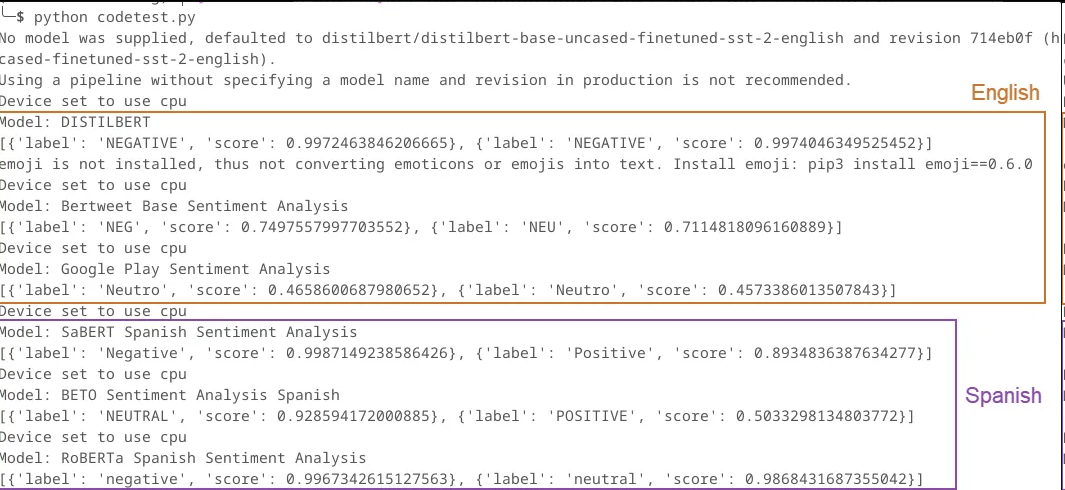
In all three Spanish-language test cases, the use of l33tspeak resulted in a completely different qualitative classification than the original prompt. These outcomes generated a few questions I’d like to share:
What do the training sets for all three models look like? Not all of the documentation on HuggingFace offers this context, but I can say that for the SaBERT Spanish Sentiment Analysis Model, it was trained on 11.5k thousand Spanish-language tweets that could be considered positive or negative. Seems small, right? Well, the distilbert sentiment model shown at the top of the output above was trained on the SST-2 dataset, which consists of 11,855 single sentences extracted from movie reviews. Granted, this specific model is a branch off of another distilbert model that was based on BERT, so there are layers of training in this model that maybe don’t exist or are at least unaccounted for in the SaBERT Spanish Sentiment Analysis model.
A follow-on question regarding SaBERT’s dataset is, how many of those tweets included some form of l33tspeak? Whether or not the model has had exposure to l33tspeak and has been trained to properly interpret and classify it is a key factor into how susceptible it may be. This may also be subject to how familiar Spanish speakers are with l33t and how frequently they use it in conversation that is ultimately used as training data.
An interesting point in the data is that in all three Spanish-language test cases, the l33tspeak prompt drifted away from negative classification. Even though the last model classified it as neutral, it moved away from the negative rating that the original prompt received. This could be due to dataset limitations, which could be an inherent byproduct of reduced l33tspeak usage among Spanish-speakers.
What’s the Point?
You may wonder, “Alright, I get it. You bamboozled a Spanish-language model into thinking your nerd-laden hot take of a Titanic book isn’t so bad. So what?” The point is, this can be leveraged for, at a minimum, mischievous purposes. If you go onto a public retailer site, you may observe that all of the reviews for the products being sold are summarized into a statement that offers a general gist of what folks’ opinions are. If you’re in marketing, you may already be using tools that ingest and summarize brand reputation information for your employer. Using something as simple as l33t against a susceptible model can result in damaging reviews and opinions about a product or brand flying under the radar and impacting bottom lines without stakeholder awareness. In basic terms, achieving a l33t bypass can result in someone communicating a piece of information that monitoring parties otherwise don’t detect. Outside of sentiment analysis, this has been observed to be useful in bypassing spam filters. Hopefully, organizations would be using more than a single layer of defense in these cases, but it can result in the delivery of malicious material to an end user and ultimately compromise an environment.
Future Research
Areas for research expansion on this project include testing against other models in languages that use the Latin alphabet. Additionally, having a grasp of how prevalent l33tspeak is in each of the languages tested would offer a reference point that could help us better understand the “why” of some model weaknesses. Lastly, obtaining stronger documentation on what the training sets look like for available sentiment analysis models could also offer insight into understanding where gaps may lie when it comes to digesting adversarial prompts in l33tspeak.