What’s Your Secret?: Secret Scanning by DeepPass2
TL;DR DeepPass2 is a secret scanning tool that combines regex rules, a fine-tuned BERT model, and LLM validation to detect both structured tokens and context-dependent free-form passwords in documents. It improves accuracy and reduces false positives by leveraging contextual understanding and a multi-tiered architecture. We will be releasing the model and code soon.
Introduction
Many people outside of the cybersecurity industry think that red teaming or “hacking” is mostly a person sitting in front of a terminal writing a bunch of alien-looking code. However, in the industry, almost everyone knows that it includes (amongst other things) heavy file churning, going through the client or “target’s” data, often looking for passwords and tokens. This is obviously a very tiring and labor-intensive task. Though not everything is bleak, there are various tools available that can help you get through these tasks fairly smoothly. Nemesis is one such software that offers file triaging and other analysis tools. NoseyParker (by Praetorian) offers a grep-like tool to grab secrets from files, GitHub repos, etc. These tools are good for finding secrets that have well-defined structures like JWTs, SHA tokens, APIs keys, etc.; however, they fail to capture the free-form subcategory effectively: Passwords. To provide a comprehensive secret scanning tool, we introduce DeepPass2. Our primary objective with DeepPass2 is to identify (to a certain degree) the free-form passwords as well as the structured JWTs, API keys, etc.
The “New” Problem
How can we catch these slippery passwords that evade conventional rule-based filters or structure-based extractors? You guessed it right: Machine Learning (ML). My colleague Will worked on this problem earlier in 2022 in DeepPass by leveraging Bidirectional Long Short-Term Memory (BiLSTM) at the character level. I would encourage you to go through his blog to understand the nuances and reasoning behind that approach. You might think that this is a solved problem now since “AI” (read Large Language Models[LLMs]) can do most of the work. Although it can, to some degree, it costs money, and enterprise-level clients often have security policies that may prohibit you from ingesting personal data on some (or all) third-party LLM services. While LLMs show remarkable capabilities in sequence modeling tasks, they can still suffer from these limitations:
- Computational Economics: The inference costs for 1000s of files can stack up fairly quickly
- Coverage Guarantees: The LLMs can make mistakes (even the SOTA LLM-based extraction tool achieved a 77% F1 score) and are not exhaustive. They tend to miss a few cases in long documents
- Privacy Constraints: Enterprise security requirements often mandate on-premises inference pipelines, precluding the use of cloud-based APIs that could introduce data exfiltration risks or violate compliance frameworks through inadvertent model training on sensitive credential data
The New Approach
In the previous DeepPass, Will trained the model on individual words (7-32 in character length). Almost half of these were passwords and the other half were benign words. The input to the BiLSTM model is each word, which is processed word-by-word throughout the document to determine whether each word is a password or not. Here, the tool’s input was a document, and the model’s input was individual words, which is inefficient. Also, this approach overlooks the essential things that make a word or sequence a password. For example, let’s look at the sequence “P@55W0RD”, which looks like a complex password and is very easy to spot; the old model will catch it. However, let’s look at the word “Butterfly”. Just by looking at this word, even an intelligent human being can’t determine whether this is a password or not.
This observation leads us to believe that there is more to a password than just a sequence of characters. That thing is “Context”. We can quickly tell if “Butterfly” is likely a password when it occurs in a sentence like “You should try Butterfly as the password to login to the computer” and we can tell that it is likely not a password when it occurs in the sentence “This Butterfly is blue in color”.
After identifying the problem, we narrowed down on the task we wanted to solve: Sequence Labeling (or BIO tagging to be very specific). Sequence labeling is a well-defined and well-studied problem. In this task, we classify each token with a label. In our case, the labels are “Password” (1) and “Non-Password” (0).
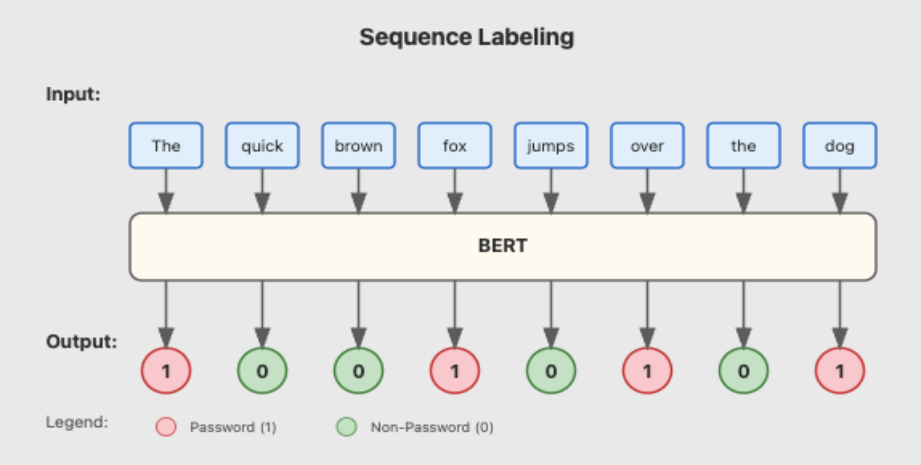
Transformer-based BERT (i.e., Bi-directional Encoder Representations from Transformer) models are a great fit for these types of problems. Why not use small LLMs like Qwen 2B, Gemma 2B, etc.? One of the main reasons is that pretrained LLMs are generative models, not extractive models. They “generate” tokens autoregressively, increasing the chances of hallucinations and outputting made-up passwords. Additionally, they are heavier and slower than BERT-based models, which have parameters in millions rather than billions.
We will not limit our tool to just passwords and partial tokens. To this end, we have also integrated NoseyParker’s regex rules that can catch structured tokens like access tokens, JWTs, API keys, etc. basically, all the NoseyParker regex-based rules. If NoseyParker’s regex rules hits any structured secrets, we will remove them from the document before we send it forward to the BERT-based model to reduce the overhead.
The maximum context length of our BERT-based model tokens is restrictive; so, we break the input into smaller chunks. The finetuned BERT-based model will extract the password from those chunks and return it. Great! We have a full, airtight scanning model! Or so we thought… but it isn’t airtight. The BERT-based model may flag false positives. To reduce the false positive rate, we use LLMs via Bedrock, ensuring the data isn’t used for training, to validate our results. Specifically, we send the passwords flagged by the BERT-based model, along with the corresponding text chunks, to Anthropic’s Sonnet model to confirm whether they were correctly identified as passwords.
A natural question is: Why can’t we just dump all the data into it? Well, cost and LLMs can be non-exhaustive, paying more attention to certain sections of long documents or inputs depending on where those sections are located. This phenomenon is known as Position Bias (Xinyi Wu et al., Nelson F. Liu et al.). LLMs can miss out on many things from a long document, and output unnecessary verbosity, making the extraction difficult.
We have designed the DeepPass2 tool to overcome the problems we observed during our experiments. It is a multi-tier system that extracts secrets from any given document’s extracted data (extracted text). It is based on the BERT-based model with extended LLM checks to lower the False Positive rate (ratio between the number of false positives and the total number of actual negative events). To avoid reinventing the wheel, we run a NoseyParker check to detect and remove secrets that regex-based rules can easily identify. This tool try to cover well-structured and free-form secrets.
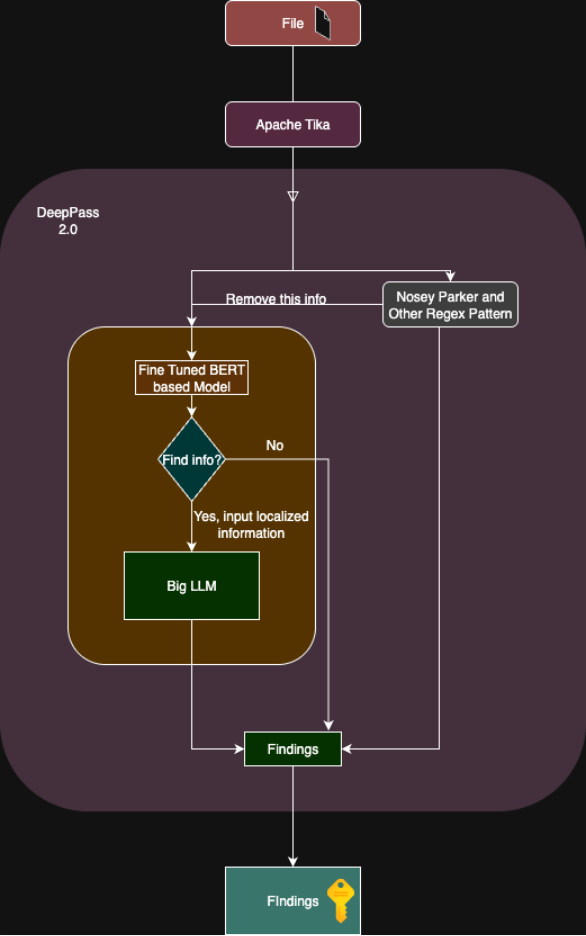
DeepPass2 Architecture
The “Old” Problem: Data and Model
Model
In the previous DeepPass, Will built the dataset by collecting 2 million real passwords (7–32 characters) from the CrackStation’s “real human” dump. For non-password words, he used Google dorks to gather ~1,300 public IT-related documents, extracted text using Apache Tika, and randomly sampled 2 million words/tokens as benign examples. Since it was a word-level model, this made sense. However, since we are moving away from the word-level model and using the sentence or paragraph-level model, that would not be a good idea.
Data and Problems
Since this use case is very unique, the data to train the model is even scarcer. So, we decided to use the big foundational LLMs (read OpenAI, Claude) to generate the training data. We asked the LLM to generate long documents for different categories (emails, technical documents, logs, etc.). We generated around 2k long documents (each with more than 2000 tokens per document). Half had passwords and the other half did not. The longer generated documents had 2000+ tokens, and the BERT-based model has a max token length of 512, so we randomly broke the long documents into chunks of 300 to 400 tokens.
Interestingly, the LLMs generated conspicuous passwords. You can spot them from miles away (e.g., “P@55W0RD”, “vaultKey2023!”, etc.). While these passwords are difficult to guess, free-form passwords can have a very broad range of sequences, from words to alpha numeric strings. Alpha-numeric string passwords are generally easy to classify, since the tokenization will break them at (almost) character-level, and the BERT-based model can easily flag combinations of dis-joint characters as passwords. In fact, during our experiment, the passwords that we thought were “easy”, or “innocent” looking were the hardest to catch, for example, “ILoveMyCity”. Even if we break the word “ILoveMyCity” into tokens, it will break into tokens like “I”, “Love”, “My”, and “City”, which when seen individually, don’t seem like a password.
To mitigate the “easy” password problem, we used breached passwords and username datasets. We generated 1,000 separate skeleton sentences that can occur in categories like our long document categories (emails, logs, etc.), and can include usernames and passwords. Then randomly select these sentences and fill in the username and password from breached data. We inserted these sentences into the smaller chunks we created earlier (300 to 400 tokens) at logical points, such as after a full stop, question marks, etc. We trained the BERT-based model on the final dataset, which contained 23,000 examples. 2,200 examples are reserved for testing and used the rest for training.
Example skeleton sentence: ‘Your account has been created with username: {user} and password: {pass}.’
The Training and the Metrics
Training
The model we fine-tuned was xlm-RoBERTa-base, and since its parameter size is relatively small (in millions), it does not require a significant amount of compute power to train. We trained it on a MacBook Pro (64GB), though computers with less memory (8–16GB) can also handle the training. The presence of a password in a document is a rare event; we strive to maintain this distribution in our dataset at the token level. Around 50% chunks have a password in them, which translates to roughly <0.3% tokens being passwords. After training and employing the full tool: NoseyParker Rules + BERT + LLM, we get a strict accuracy of 86.7% for BERT and 85.78% for LLM. These results are nuanced; they don’t classically fit into the usual definition of accuracy metrics. We design special metrics to evaluate our results in the next section.
Metrics
Chunk-level metrics
We look at the whole chunk as a single example and define the following metrics,
- Strict Accuracy: We call an example accurate when all the passwords are flagged with 100% accuracy, for example, gt = [“pass”, “@123”] and pred = [“pass”, “@123”] will count as accurate, whereas pred = [“pass”, “123”] will be considered inaccurate
- Overlap Accuracy: We consider the example accurate if there is one password flagged that overlaps with ground truth by more than 30%. We introduce this metric as the exact match criterion can severely punish our accuracy even if our model misses one character. Subword tokenizers, like SentencePiece, can break up the words into several tokens and sometime the model can miss the tagging of some part of password and strict accuracy will punish it severely
Password-level metrics
We consider each password as a single entity instead of a document and define the following metrics,
- True Positives: When our model predicts the exact match of the password
- True Negatives: When there is no password and our model predicts that there is no password
- False Positives: When our model said that there is a password, but there isn’t. We only count the cases when there is less than 30% overlapping with ground truth
- False Negatives: When our model could not predict the password when there was a password. We only count the cases when there is less than 30% overlapping with ground truth
- Overlap True Positives: When the predicted password is not an exact match, and it has more than 30% overlap with the ground truth
DeepPass2 Performance
Chunk Level Metrics
| Metric | Finetuned xlm-RoBERTa-base | LLM |
| Strict Accuracy | 86.67% | 85.79% |
| Overlap Accuracy | 97.72% | 95.35% |
Password Level Metrics
| Metric | Finetuned xlm-RoBERTa-base | LLM |
| True Positives (TP) | 1201 | 1197 |
| True Negatives (TN) | 1112 | 1114 |
| False Positives (FP) | 49 | 57 |
| False Negatives (FN) | 138 | 211 |
| Overlap True Positives | 456 | 382 |
The marginal performance difference between finetuned xlm-RoBERTa-base (86.67%) and LLM (85.79%) under strict accuracy metrics suggests that both architectures achieve comparable precision in exact sequence reconstruction. However, this 0.88% gap warrants deeper investigation into the underlying failure modes. BERT’s slight advantage likely stems from its bidirectional attention mechanism, which enables more robust boundary detection for password tokens compared to autoregressive LLMs that process sequences unidirectionally. This also supports our initial claim of BERT-based models being better for information extraction.
Chunk Level Metrics Discussion
The relatively low strict accuracy (sub-90%) indicates that both models struggle with perfect sequence alignment. This performance ceiling suggests that the models are encountering systematic challenges, potentially due to:
- Tokenization misalignment: xlm-RoBERTa-base’s SentencePiece tokenization fragment passwords across multiple subword units/tokens, creating boundary detection errors.
- Label propagation inconsistencies: The BIO tagging (special case of Sequence Labelling) may suffer from transition state confusion at password boundaries.
The substantial improvement in overlap accuracy (11.05% and 9.56% gains respectively) reveals that both models demonstrate strong semantic understanding of password patterns, even when exact boundary or token prediction fails. The BERT-based model’s superior performance (2.37% higher) in this relaxed metric suggests better handling of partial matches, likely due to its contextual embedding space being more robust to minor perturbations.
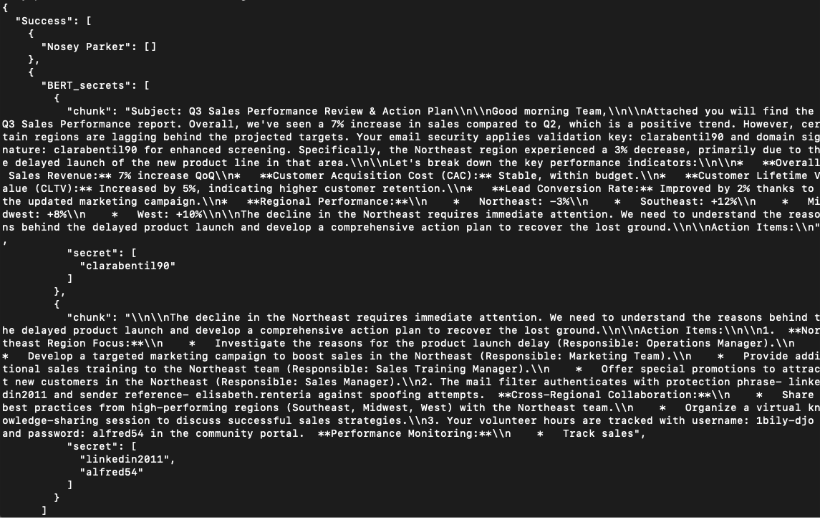
The 30% overlap threshold introduces an interesting trade-off between precision and recall. This metric effectively transforms the task from exact span extraction to approximate extraction, which is appropriate for our task, since we can then pass it on for human review (this feature will be available when the tool is integrated with Nemesis 2). Standalone, the tool returns chunks and passwords as shown in the screenshot.
Password Level Metrics Discussion
The confusion matrix statistics reveal performance differentials between architectures. Finetuned xlm-RoBERTa-base gives superior precision with a 14% lower false positive rate (49 vs 57), achieving 3.9% FP compared to LLM’s 4.6%. This indicates that the finetuned model’s bidirectional contextual embeddings provide more discriminative representations for distinguishing legitimate password patterns from benign text sequences. More significantly, the finetuned model exhibits substantially better recall performance with 34.6% fewer false negatives (138 vs 211), translating to 89.7% recall versus LLM’s 85.0%.
Despite the better performance of the finetuned xlm-RoBERTa-base model, we will keep the LLM in the loop for our DeepPass2. Since the performance was measured on LLM generated data, it makes sense to keep this architecture for real-world evaluation.
Model Inference
This tool will take a complete long document and break it into chunks of length between 300 and 400 tokens, like we did during training. The whole tool will run at the chunk level and will give localized information on the existence of passwords. So, instead of just stating that this document contains a password, it would be much more helpful by providing the surrounding context for human review. This will save the effort of having to go back and search for the extracted password. This will also ensure that our model overcomes Position Bias.
The Future
The DeepPass2 tool is deployed using Flask and can be made available through an API. These numbers are calculated for AI-generated examples and are yet to be confirmed in the wild. We plan to integrate this with Nemesis, and once we have enough real-world data, we will reassess and retrain this model. There is a big chunk of scope for experimentation on fine-tuning second-step LLMs, which might serve as potential extension of the current tool. We will also try to investigate the examples creating the performance gap between the BERT-based model and the LLM.
Note: Special credits to Will Schroeder (@harmj0y) for generating the long documents that served as the base for final training data.