Reactive Progress and Tradecraft Innovation
Detection as Prediction
The overarching goal of a security operations program is to prevent or mitigate the impact of an attacker gaining unauthorized access to an IT environment. In service of this mission, information security professionals must make predictions about what that access can look like, what an attacker can do with that access, and how those actions can be observed.
While outright prevention via protective controls is always an admirable and necessary goal to strive for, information security (infosec) professionals largely operate under the premise that a competent adversary with ample time and resources will inevitably evade those controls. This dynamic means that an outsized portion of our daily responsibilities have shifted towards identifying instances where protective controls have failed.
Every security operations program employs detection rules in some way in their daily work, whether they write those rules themselves or rely on vendors to provide them as part of various detection and response products. Every detection rule is a prediction and contains a set of assumptions about how the world around us works. More specifically, every detection rule represents a set of assumptions about the nature of offensive tradecraft and the nature of the telemetry that results from that tradecraft.
Detection rules force us to make predictive statements that boil down to, “This is what an attacker is likely to do with access to my environment and this is the telemetry that will be generated when they take those actions.”
For individuals directly responsible for their organization’s detection and response capabilities, there is seemingly no end to their mission. Infosec is an inherently adversarial discipline where attackers and defenders are locked in a reactive cycle of innovation and evasion in pursuit of dominance over one another. The question of what a given attacker might do with access to your environment is inherently slippery, nuanced, and subject to uncertainty in every direction. The subsequent questions surrounding the observability of those actions are similarly fraught with uncertainty and opacity, frustrating our ability to make accurate predictions in the form of detection rules.
The efficacy of an organization’s detection capabilities is measured in degrees of likelihood, filled with caveats, and taken in the context of resource constraints. Nonetheless, a detection engineer must be confident that their current rule base would be likely to identify and notify relevant parties if an attacker were to gain unauthorized access to an IT system under their purview.
But how are those individuals expected to establish and justify that confidence when basically every piece of the puzzle is opaque and uncertain? The short answer is that they can’t and shouldn’t. Instead, they should identify what they are uncertain about and detail how that uncertainty may have an impact on the detection rules they employ in their environment. In other words, confidence in the efficacy of our detection rule base(s) does not stem from determining that a given rule is ‘correct’ or ‘infallible.’ Ironically, confidence is established by outlining what you are likely WRONG about.
This post outlines some of the sources of uncertainty that increase the likelihood that our predictions will be incorrect and offers a strategy to cut through the fog that obscures the world around us.
Predictions, Assumptions, and Uncertainty
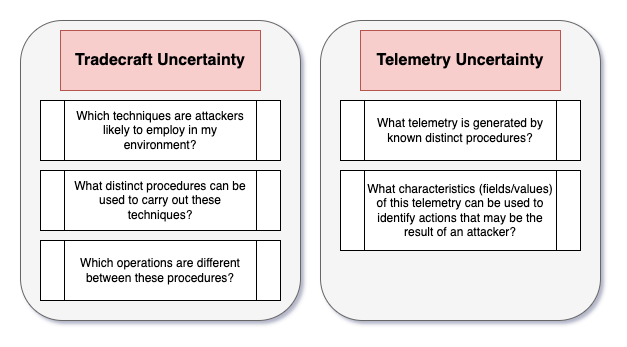
Every prediction must contend with the unique sources of uncertainty that are germane to the problem set we are addressing. When attempting to make predictions in the form of detection rules, defenders must make correct assumptions related to two main categories of uncertainty:
- Tradecraft uncertainty
- Telemetry uncertainty
Tradecraft uncertainty stems from the difficulty of determining what subset of known offensive tradecraft is likely to be employed in a given environment at any time. While this conversation normally revolves around which techniques attackers are employing in the wild as per public threat reporting, it is also necessary to make assumptions about the possible distinct procedures for those techniques and how they differ. It is not enough to say that attackers are likely to attempt to retrieve credential material from local security authority subsystem service (LSASS) memory. Defenders must also attempt to identify the different ways that an attacker can retrieve that credential material.
Telemetry uncertainty stems from both the technical complexity of modern telemetry generation as well as the opacity of detection and response products. While there are a finite number of telemetry generation mechanisms on Windows hosts, they rely on low-level operating system (OS) components that take a significant amount of time and effort to understand. Additionally, it is not always clear how detection and response products make use of these mechanisms or the kinds of additional filtering constraints they apply to the data they produce.
It is important to note that because telemetry generation is relative to the procedures and operations that an attacker carries out, correct assumptions about telemetry require correct assumptions about the nature of offensive tradecraft.
The remainder of this post will discuss the nature of tradecraft uncertainty and how to reduce its impact on the efficacy of the rules detection engineers create. Later posts will dig further into telemetry uncertainty and attempt to put all of the pieces together.
Defining Tradecraft Uncertainty
Detection rules must make assumptions about the nature of tradecraft, but that tradecraft is difficult to describe, compare, and predict with an adequate level of detail. The advancement of tradecraft occurs within an adversarial and reactive context, where innovations in defensive capabilities trigger a direct response from adversaries. Game theorists often refer to these kinds of interactions between adversaries as “reaction correspondences.”
In infosec, attackers develop offensive tradecraft and tooling to achieve a shifting set of operational objectives. In response to these innovations, defenders implement relevant protective controls and detection strategies. In turn, attackers modify tradecraft to account for those defensive measures whether that entails new distinct procedures, variations on existing procedures, or shifting capability to a new technique entirely. There are many aspects of modern tradecraft that can be explained by tracing this tit-for-tat cycle of innovation back through time: the shift from PowerShell tooling to other .NET-mediated languages, the shift towards in-memory execution techniques, and countless other tradecraft preferences that have become virtually unanimous at this point.
This ever-advancing development of offensive tradecraft can be predicted, but not known with any reasonable degree of certainty. We can make predictions based on what is observed “in the wild,” but we need a reliable mechanism to discern whether those observations are representative of what is possible. There is no guarantee that the subset of tradecraft that is observed and shared publicly is wholly representative of what a given attacker operating in an arbitrary environment with unique constraints is likely to do at any time.
If we want to predict what is likely, we must be able to describe what is possible.
Likelihood is a comparative measure. If we want to make statements about the likelihood that a given event will occur in the future, we have to say that it is more or less likely than some other event. A defensible estimation of likelihood necessarily entails having a thorough account of other possible events to compare to.
Information about what has been observed in the wild is invaluable to the creation and evaluation of detection rules, but it is only the start of the process of making defensible predictions about what is likely to occur in the future.
Combatting Tradecraft Uncertainty
If we want to describe what is possible, we need a more thorough account of the specific procedures that can be used to carry out a given attack technique. In most accounts of offensive tradecraft, there is very little grounds to compare distinct procedures to one another because there is no concrete definition of what a procedure is. Tactics and techniques are categorical labels that describe the intended outcome of an attacker executing some series of lower-level actions, but the procedure layer is intended to describe how those lower-level actions are carried out. However, procedures can be anything from an attack tool, a specific command, or a high-level description of an approach to a given technique. This lack of consistency frustrates our ability to survey known tradecraft effectively, let alone predict what is possible.
Describing the differences between procedures requires the articulation of a lower-level set of observable actions that, when combined, represent a series of steps that can be used to execute a specific attack technique. I like to refer to these lower-level actions as “operations,” which means that a procedure can be defined as, “An ordered set of operations that, when combined, achieve some specific outcome.”
To provide an example, we could describe the “canonical” example of LSASS credential theft (as represented by the Mimikatz module sekurlsa::logonpasswords) using the following set of operations, each representing an “action” that targets a specific “object”:
- Obtain the process ID (PID) of lsass.exe
- Open a handle to the lsass.exe process with the necessary access rights
- Read lsass.exe process virtual memory

I have published a web application, Cartographer, that seeks to display this information for this procedure along with several other distinct procedures that can be used to retrieve credential material from LSASS virtual memory.
While this may seem like an unnecessary level of detail, the power of this conceptual model becomes clear in two particular situations:
- When attempting to determine the difference between multiple tools that purport to implement the same attack technique
- When attempting to determine which operations known detection strategies and protective controls typically target
In other words, describing procedures in this manner provides clarity on not only how currently known tooling carries out some specific technique but also the specific operations that are likely to be the focus of future reaction correspondences. If the set of operations above represent one known procedure for LSASS credential theft, then any tool that replaces or skips these operations represents a distinct procedure and may require modifications to defensive measures that assume this is the only way to carry out the technique.
Predicting Reaction Correspondences
Imagine that you are tasked with determining if your organization’s current detection rule base effectively “covers” all known approaches to LSASS credential theft. You may have a single rule that purports to detect LSASS credential theft generically or several rules that purport to detect multiple distinct procedures, but how do we make sense of these varying detection strategies?
Let’s discuss some common approaches to LSASS credential theft in a historical context. Mimikatz has been around for over a decade at this point and has been the driver of large leaps in capability related to both stealing credential material and defending against it. As defenders began to focus on the detection and prevention of specific operations, attackers updated their credential theft tradecraft in lock-step.
Detection Strategy: Detect Unmodified Mimikatz on Disk
The first class of detection strategies relate to detecting the execution of Mimikatz, rather than the operations it must carry out to access credential material. They rely on the identification of file characteristics (e.g., file hash, file names, etc.). These detection strategies are often brittle because they assume that the following is true:
- Attackers are likely to execute Mimikatz on an already infected Windows system
- Attackers are likely to execute a Mimikatz portable executable (PE) that was compiled without straightforward modifications like file name or PE header attributes
- Attackers are likely to write a Mimikatz PE compiled without these modifications to disk
We can think of this category of detection rules as overly-narrow in scope, extremely brittle, and attempting to solve a problem that protective controls already likely account for. It’s easy to see the situations in which these assumptions can be falsified and the level of effort required to produce a falsifying sample is trivial.
Detection Strategy: Using PowerShell Reflective Loading to Detect Mimikatz Execution
Attackers quickly learned that writing an unmodified Mimikatz PE to disk was an untenable approach to credential theft, regardless of what types of credentials they sought to steal or which command they chose to run to steal them. PowerSploit added the Invoke-Mimikatz PowerShell script in October 2013, which gave attackers a straightforward method to load Mimikatz into memory.
Almost ten years later, I still see detection rules that use various types of PowerShell logging to identify keywords related to in-memory Mimikatz execution via PowerShell. Like the first category of detection rules, detections focused on PowerShell logging don’t make any assumptions about the underlying operations that Mimikatz carries out on our behalf. Instead, they rely entirely on making accurate predictions about the way that Mimikatz will be delivered to, and executed on, an already-infected host. So what are the assumptions that drive this prediction?
- Attackers are likely to execute Mimikatz on an already infected Windows system
- Attackers are likely to avoid writing an unmodified Mimikatz PE to disk and executing that written file
- Attackers are likely to use PowerShell to reflectively load Mimikatz into memory and cannot avoid using specific keywords to do so
- PowerShell transcript, script-block, and module logging are likely to record those specific keywords in a way that can be queried in near real-time
We can already begin to see the reactive nature of advancements in offensive tradecraft and the ways in which those advancements are often scoped in terms of the specific detection and prevention strategies that defenders employed. Attackers were well aware that defenders had begun to focus their detections around a PE being executed from disk and developed an approach that did not carry out that operation in particular.
However, PowerSploit’s Invoke-Mimikatz and similar implementations only sought to modify the installation and execution of Mimikatz. Even if the authors of these tools were aware of other ways to implement the operations abstracted by Mimikatz’s sekurlsa::logonpasswords command, they seemingly did not feel as though the level of effort to move beyond in-memory execution would pay off because they perceived that defenders were not paying attention past that point.
Detection Strategy: Detect a Process Opening a Handle to LSASS with Alternative Access Rights
With the benefit of hindsight and a little knowledge of how securable object access rights work, it’s easy to see how attackers were able to evade a detection strategy that focused on default access rights. Sometime after this approach became common, Benjamin Delpy modified this call to OpenProcess so that instead of an access mask of 0x1410, it supplied a value of 0x1010 as the dwDesiredAccess parameter. This change in requested access rights had no impact on the functionality of Mimikatz, but did serve to evade any detection strategies that assumed that this value could not be changed without changing the nature of the procedure.
While this change did represent a successfully seized evasion opportunity, it does not represent a distinct procedure. No operations were skipped or replaced, so we are still looking at the same set of ordered operations that we have termed “Direct Open and Read.” Instead, this change in access rights can be considered a “variation” of an existing procedure because it does represent an approach that is intended to evade specific detection strategies and protective controls.
Years later, it is trivial to find many examples of detection rules that attempt to identify several different sets of access rights that offer sufficient permissions to read LSASS process memory. These rules are generally sufficient to detect this particular procedure, but make some important core assumptions:
- Attackers are likely to attempt to open a handle to the running lsass.exe process in order to access credential material stored in its virtual memory
- Attackers are likely to open that handle with at least the PROCESS_VM_READ access right included, but there are multiple possible access mask values that can be used to do so
- Attackers are unable to read the virtual memory assigned to the running lsass.exe process without opening a handle with these access rights included
Protective Control: Windows 10 Local Security Authority (LSA) Protections
While detection strategies began to focus on different combinations of handle access rights that could be used to call Win32 API functions like ReadProcessMemory or MiniDumpWriteDump, Microsoft began to take a more preventative approach in the early 2010s and introduced two important changes to the way lsass.exe ran on Windows systems.
First, lsass.exe could now optionally run as a Protected Process Light (PPL) with some minor registry changes (the RunAsPPL value in HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlLsa). PPL is an addition to the larger Protected Process (PP) framework and was intended to prevent userland processes from tampering with various types of critical system processes. The PPL model defines a hierarchy of “Signer’’ types that add an additional privilege requirement when attempting to interact with a process running as PPL. In other words, when lsass.exe runs as PPL, attackers are severely limited in their ability to open a handle with the PROCESS_VM_READ access right. I won’t get too into the details of the PPL model as they are thoroughly covered elsewhere, but it’s safe to say that this mitigation effectively kills an attacker’s ability to open useful handles to lsass.exe that could be used to read virtual memory. Additionally, the PPL model introduces strict signing requirements for any library files or other resources that a PPL-protected process wants to load.
Second, Microsoft also added a default system access control list (SACL) entry to the lsass.exe process when launched at startup. This SACL entry generated an audit event any time that a user in the EVERYONE group attempted to open or use a handle to lsass.exe that included the PROCESS_VM_READ access right. This change allowed defenders to tap into audit events (EID 4656 and EID 4663) that they would have been otherwise unable to configure themselves.
Just like detection rules, protective controls also represent predictions about what attackers are likely to do and come with their own set of baked-in assumptions. Taken together, these two new protective controls Microsoft provided made the following assumptions:
- Attackers are likely to attempt to open a handle to the running lsass.exe process in order to access credential material stored in its virtual memory
- Attackers are likely to open that handle with at least the PROCESS_VM_READ access right included, but there are multiple possible access mask values that can be used to do so
- Attackers are unable to read the virtual memory assigned to the running lsass.exe process without opening a handle with these access rights included
- Attackers are unlikely to open or use a handle for lsass.exe from a process that is running as PPL with a signer level greater than or equal to PsProtectedSignerLsa
- Defenders are likely to enable the RunAsPPL feature for lsass.exe
Beyond Handle Acquisition: Distinct Procedures
So far, we’ve really only discussed the back-and-forth surrounding directly opening a handle to lsass.exe up until the point where Microsoft decided to release protective controls and telemetry generation mechanisms directly targeting this operation. One of the things I find most interesting about this technique is that this years-long narrative only touches on a single distinct procedure according to my definition (“a distinct set of ordered operations”). While we have discussed multiple ways to open a handle to lsass.exe, we haven’t discussed any of the procedures that skip this step entirely. I will not attempt to discuss these in chronological order as the release of LSA protections like RunAsPPL, default SACL entries, Credential Guard, and other OS features seems to have kicked off several lines of innovation on the offensive side of things.
In a world where defenders exerted a significant amount of effort on the handle acquisition operation, attackers were left with two primary options:
- Determine a way to read process memory without requesting a new handle with the PROCESS_VM_READ access right included
- Find a way to extract credential material from lsass.exe’s virtual memory without reading memory directly (since those functions require a handle with the PROCESS_VM_READ access right)
At this point, attackers likely had a collective realization that they would have to take these new defensive measures into account if they wanted to continue to interact with lsass.exe on a compromised system.
Duplicate Handle and Read
In a world where attackers could no longer guarantee that they would be able to directly open a new handle to LSASS that included the PROCESS_VM_READ access right, attackers began to find other ways to acquire a handle that could be used to call memory and read Win32 APIs. One option was to identify and duplicate an already existing handle to lsass.exe that had the PROCESS_VM_READ access right. Let’s take a look at the operations for this procedure to determine if it is distinct from the Direct Open and Read procedure we have discussed so far:
- Enumerate currently open handles to identify a handle that has the PROCESS_VM_READ access right assigned to it
- Open a handle to the process that has the currently open handle we want to duplicate
- Duplicate the handle while specifying the correct access rights for the duplicated copy of that handle
- Validate that the newly duplicated handle points to lsass.exe
- Read lsass.exe process virtual memory using the duplicated handle
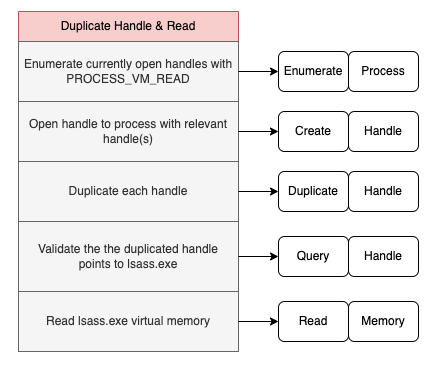
It’s clear to see that this is a distinct procedure because it requires a unique set of ordered operations. Specifically, it replaces the Open Handle operation by enumerating currently open handles and determining whether they have the correct access rights and point to lsass.exe.
This procedure invalidates the assumption that attackers must open a new handle to lsass.exe in order to read virtual memory. Duplicating a handle does not trigger the SACL entry for lsass.exe and does not issue a function call like OpenProcess that may be subject to function hooking. While this procedure does still require the use of a handle to lsass.exe with the PROCESS_VM_READ access right, attackers do not have to create that handle themselves.
While this procedure is interesting, its biggest downside is that you are unlikely to find a handle to lsass.exe with the PROCESS_VM_READ access right that doesn’t belong to lsass.exe itself. However, there are several handle leaking procedures documented online that are distinct from handle duplication but follow a similar train of thought.
Process Forking/Snapshotting
But what if we don’t have to avoid opening a new handle entirely and can still get access to lsass.exe’s virtual memory without including the PROCESS_VM_READ access right? This set of distinct procedures is centered around creating children or snapshots of lsass.exe that have a full copy of the virtual memory of the original lsass.exe. Because SACL entries are not inherited in this context, a newly opened handle to the cloned or snapshotted version of lsass.exe with the PROCESS_VM_READ access right would not generate an audit event.
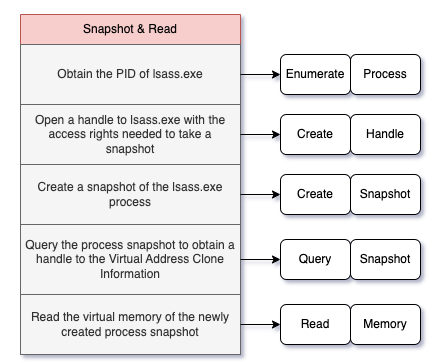
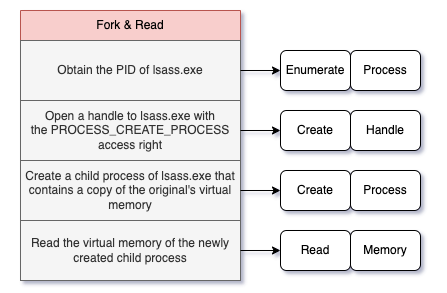
The operations for process snapshotting are:
- Obtain the PID for lsass.exe
- Open a handle to lsass.exe with the access rights needed to take a snapshot
- Create a snapshot of the lsass.exe process
- Query the process snapshot to obtain a handle to the Virtual Address Clone Information
- Read the virtual memory of the newly created snapshot process
The operations are similar for Process Forking, but an attacker would create a child process of lsass.exe instead of a snapshot. These procedures invalidate assumptions about the need to open a new handle to lsass.exe that includes the PROCESS_VM_READ access right. While these procedures do require a new handle to lsass.exe, that handle only needs the PROCESS_CREATE_PROCESS and PROCESS_QUERY_LIMITED_INFORMATION access rights. Attackers will need to open a new handle with the PROCESS_VM_READ access right, but it will be related to the new clone/snapshot that is not subject to the same SACL-based auditing as the original lsass.exe process.
Predicting Evasive Tradecraft
We’ve now devoted a significant amount of time to discussing the ways in which advances in LSASS credential theft procedures have largely focused on a specific operation: the opening of a handle to lsass.exe. Realistically, we’ve only discussed a portion of the distinct procedures for this technique, leaving out driver-based tradecraft, security support provider (SSP) injection, indirect dumps through the Windows Error Reporting service, and other distinct procedures.
This post is not intended to be an exhaustive account of every distinct procedure for this technique. Instead, it intends to show that innovation in infosec is inherently reactive and cyclical. If this tenet is true, it means that we can begin to predict future advancements in offensive tradecraft if we are able to focus on the right portions of known tradecraft. This approach requires two capabilities:
- The ability to describe tradecraft in a way that is comparative and sufficiently detailed
- The ability to compare known procedures for a given technique and identify which operations present evasion and detection opportunities
If we can do both of these tasks effectively, we can build detection strategies that are more resilient to evasion and offensive tooling that is more likely to go undetected.
This post is the first in what will likely be a series that traces reaction correspondences for well-known attack techniques. The overall goal is to explore the ways in which attackers and defenders can combat uncertainty in both tradecraft and telemetry. This post focused exclusively on tradecraft uncertainty, but future posts will explore how Cartographer’s data model can be used to combat telemetry uncertainty as well.
Cartographer is available at https://cartographer.run.
For additional information about Cartographer and how it can be used to predict evasive tradecraft, watch my x33fcon talk introducing it:
https://medium.com/media/1b40ec8cdb365bfff1969b56588e3b8a/href
Reactive Progress and Tradecraft Innovation was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.