AI Red Teaming Still Comes Back to Identity, Access, and Attack Paths
Introduction
Most enterprise AI system risk is not a novel model failure; it’s familiar security failure modes showing up in systems with broader access, more autonomy, and more ways to touch sensitive data. However, I don’t want to discount that there are unique risks and attacks to AI systems.
The short version is simple: AI did not make secure-by-default, deny-by-default, or least privilege less important. It made ignoring them more consequential.
A lot of the real risk in AI systems that I’m seeing is not some exotic model breakout. It is familiar security failure modes showing up in systems that now have more reach, more autonomy, and more ways to touch sensitive data.
I recently joined Patrick Gray on the Risky Business podcast to talk about AI and identity security. Below is an abridged version of our conversation.
The Risky Business Interview: A Recap
Patrick: When people say “AI red teaming,” what are they actually testing?
Russel: That depends on who is using the term.
Sometimes people mean model testing: jailbreaks, adversarial inputs, bias, safety, alignment, and all the rest. That work matters.
But in most enterprise environments, that is not the main thing being assessed.
Most organizations are not building foundation models. They are building applications around models. That usually means a web front end, APIs, identity providers, data stores, SaaS integrations, browser sessions, internal tooling, and some model provider behind all of it.
So when I talk about AI red teaming, I’m usually talking about testing the full system. The model matters, but the real attack surface is everything around it.
Patrick: What do these systems usually look like in practice?
Russel: Usually some version of a chatbot.
That sounds less interesting than people expect, but it is what many teams are actually deploying. A user types into a web app. The app sends prompts to a model provider. Sometimes there is a RAG component. Sometimes it is connected to internal data, ticketing systems, email, Salesforce, GitHub, cloud APIs, or other services.
At that point, it is not really “just a chatbot.” It is a front end to a chain of identities, tokens, trust relationships, and permissions.
That is where the useful security questions start.
Patrick: Is this mostly new work for offensive teams, or familiar tradecraft on a new stack?
Russel: A little of both.
The AI piece is new. Prompt injection is new. The probabilistic behavior is new. You do have to understand those things.
But the rest of the system is not new. The web servers are not new. The databases are not new. The identity stores are not new. The access tokens are not new. The attack paths are not new.
A lot of the tradecraft still looks familiar:
- Compromise an identity
- Figure out what it can access
- Steal a token or session
- Pivot into the next system
- Keep moving until you reach the objective
That is not a new offensive model. The difference is that AI systems tend to concentrate access and make it easier to wire multiple platforms together in one place.
Patrick: So are you mostly finding novel AI failures, or old mistakes in new packaging?
Russel: Mostly the second one.
A lot of organizations are moving fast because they want value from AI right now. To make those systems useful, they connect them to everything. That is where they start quietly backing away from security principles they already know matter.
They stop caring about least privilege.
They stop caring about separation of duties.
They stop caring about tight review before deployment.
They stop caring about whether a token should really exist with that scope.
Then later someone is surprised that the AI system can reach too much, do too much, or expose too much.
That is why I keep coming back to the same point: AI did not make secure-by-default, deny-by-default, or least privilege less important. It made ignoring them more dangerous.
Patrick: What is actually new here from a testing perspective?
Russel: Prompt injection is the biggest one.
That is the part that feels meaningfully different. But even there, the better mental model is closer to social engineering than to a classic memory corruption bug.
You are trying to get the model to do something it should not do. That is not the same as convincing a person to hand over a password, but the shape of the problem is similar. You are working through language, context, and persuasion. You are trying to find what gets the system to comply.
The other important difference is that the behavior is nondeterministic.
That changes how you test. With a traditional vulnerability, you usually expect a clean reproduction path. With prompt injection, you might send the same thing multiple times and get different outcomes.
So the workflow has to adjust:
- Log inputs and outputs carefully
- Retry attacks multiple times
- Capture the conditions around successful behavior
- Do not assume a one-shot reproduction tells you how reliable the attack really is
If your testing process assumes deterministic outcomes, you are going to miss things or misunderstand the risk.
Patrick: Why does identity keep coming up in these conversations?
Russel: Because useful AI systems need access.
A model by itself is not that interesting from an enterprise security perspective. The interesting part is when the system can read email, search documents, update tickets, talk to Salesforce, call cloud APIs, open browser sessions, or execute actions on a user’s behalf.
That means every deployment tends to create or depend on more non-human identities, more OAuth authorizations, more service accounts, more tokens, and more opportunities to pivot.
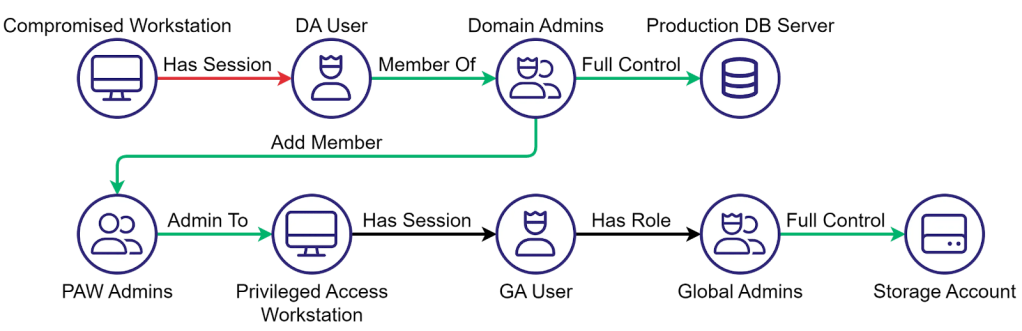
This is one reason identity attack path analysis matters so much here. Once an agent or chatbot gets compromised, the question is not just whether the AI app was insecure. The real question is what that identity can touch next.
That is the blast radius problem.
Patrick: Can you give a concrete example of how that plays out?
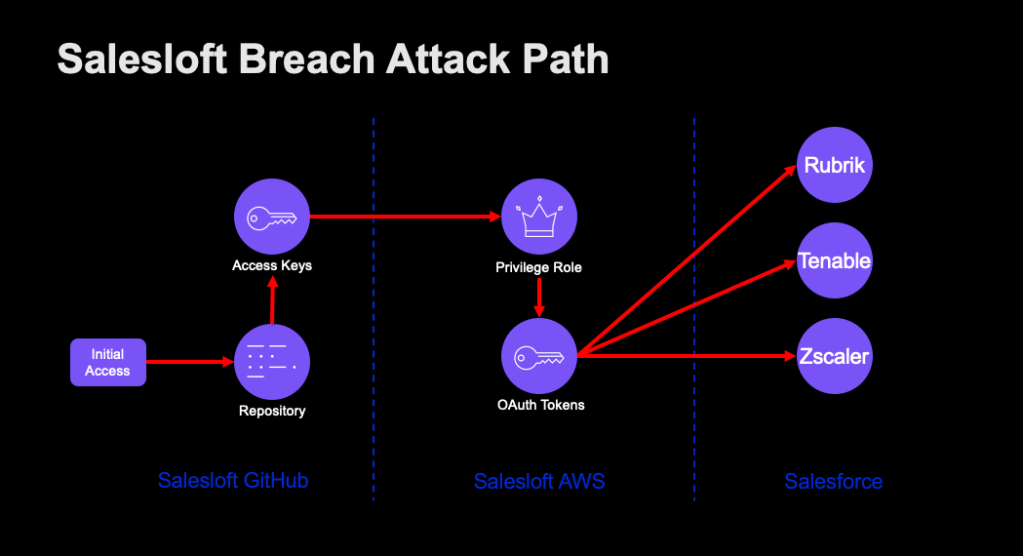
Russel: Take the SalesLoft Drift incident for example.
The reason it matters is not because it started with some magical AI-specific exploit. The pattern looked much more familiar: compromise one environment, obtain credentials, pivot, steal OAuth material, and then use that access to reach additional systems and sensitive data.
In that case, the chatbot’s access path mattered because once the relevant credential was exposed, it opened the door to much more than just the bot itself.
That is the lesson people should take away. When an AI system is connected to business systems, the credential behind it matters just as much as the prompt in front of it.
Patrick: Are there other examples that are useful for defenders to think about?
Russel: The Cline “Clinejection” example is useful for a different reason.
That one shows how indirect prompt injection and software supply chain problems can overlap. If a system is reading untrusted content and is also allowed to take action, the gap between “read” and “execute” becomes the whole problem.
The moment you allow arbitrary actions in the environment, you are creating attack paths you may not fully understand yet.
That is where teams get into trouble. They focus on whether the output looks safe and spend less time on what the system is actually allowed to do.
Patrick: Why are browser-based agents getting so much attention?
Russel: Because the browser is already a good target before you add AI to it.
Browsers hold post-MFA session material, cookies, tokens, and access to a lot of systems users do not think about very often. Offensive teams have gone after that for years. Dumping browser material or reusing authenticated sessions is not new.
What changes with AI is that you now have another natural-language-driven layer trying to act through that same environment. That can make the browser more useful to people, but it also makes it more useful to attackers.
That is why I am skeptical of AI browsers.
The browser is already full of identity material. Adding more automation and more trust to that same space does not make me more comfortable. It makes me want tighter controls.
Patrick: What should security teams do right now?
Russel: Start with the fundamentals and apply them more aggressively, not less.
A few things matter immediately.
- Inventory the identities: Figure out which non-human identities exist, what created them, what they are connected to, and what they can access.
- Review effective access: Look closely at OAuth scopes, API tokens, service accounts, browser-held sessions, and delegated permissions. Most teams underestimate how much reach these systems accumulate over time.
- Map the attack paths: Do not stop at one platform. AI deployments tend to cross multiple stacks: IdP, SaaS, cloud, browser, code repositories, ticketing, internal knowledge systems. You need to understand how compromise in one place becomes access somewhere else.
- Reduce default trust: The principle of least privilege and the clean source principle isn’t negated by AI. They are exactly the kinds of controls that become more valuable when environments move at machine speed and scale.
- Be careful what actions you expose: If the AI can execute code, take administrative action, or use broad delegated access, that is not just a product feature. That is a security decision.
Patrick: What is the main takeaway for practitioners and leaders?
Russel: The main thing that has changed is not the need for security fundamentals. It is the cost of getting them wrong.
The systems are moving faster. There are more of them. They are connected to more things. Adversaries can use AI to scale their own work too. That means the room for sloppy access design, permissive defaults, and weak identity hygiene keeps shrinking.
If you want to understand the risk in an AI deployment, start here:
- What identity did you give it?
- What can it read?
- What can it do?
- What happens when that access is abused?
That is still where most of the useful findings are going to come from.
The biggest fixes here are not glamorous. They are the same ones security teams have needed for a long time: tighter permissions, better separation, better observability and visibility, and fewer trust decisions made for convenience.
That is still the work.