Part 7: Synonyms
“Experience is forever in motion, ramifying and unpredictable. In order for us to know anything at all, that thing must have enduring properties. If all things flow, and one can never step into the same river twice — Heraclitus’s phrase is, I believe, a brilliant evocation of the core reality of the right hemisphere’s world — one will always be taken unawares by experience, since nothing being ever repeated, nothing can ever be known. We have to find a way of fixing it as it flies, stepping back from the immediacy of experience, stepping outside the flow. Hence the brain has to attend to the world in two completely different ways, and in so doing to bring two different worlds into being. In the one, we experience — the live, complex, embodied, world of individual, always unique beings, forever in flux, a net of interdependencies, forming and reforming wholes, a world with which we are deeply connected. In the other we ‘experiences’ our experience in a special way: a ‘re-presented’ version of it, containing new static, separable, bounded, but essentially fragmented entities, grouped into classes, on which predictions can be based. This kind of attention isolates, fixes and makes each thing explicit by bringing it under the spotlight of attention. In doing so it renders things, mechanical, lifeless. But it also enables us for the first time to know, and consequently learn and to make things. This gives us power.”
– Iain McGilchrist¹
Introduction
Welcome back to the On Detection: Tactical to Functional series. In this article, I hope to continue my investigation into whether I believe that detection engineering efforts should be focused on the procedural level. Last time, we defined procedures as “a sequence of operations that, when combined, implement a technique or sub-technique.”² With this definition in mind, we’ve established a hierarchy that includes functions, operations, procedures, sub-techniques, techniques, and tactics. This hierarchy allows us to talk about attacks at numerous levels of resolution or abstraction, but what does that ability provide for us? I opened this article with a quote from Iain McGilchrist in his seminal work on neuroscience titled, “The Master and His Emissary.” In the book, McGilchrist explores the two hemispheres of the brain and how they “experience” the world differently. As he says in the quote, the right hemisphere experiences the world in motion, where everything is unique and constantly changing. One could argue that even inanimate objects like mountains are constantly changing, but at a rate that is difficult, if not impossible, to perceive.
On the other hand, the left hemisphere experiences objects categorically or as forms. It represents a combination of bricks, wood, furniture, etc., as a house instead of the component parts. McGilchrist posits that there is almost certainly a reason why our brains are split this way and that this phenomenon is not unique to humans but to many other animal species. In the quote, he mentions that the power of the left brain is that by seeing literally unique instances of objects through the categorical or gestalt lens, we can see their similarity rather than differences. This feature allows us to experience a world that we understand. Without it, everything would be new, unique, and anomalous. Understanding these categories enables us to predict how they might act in different scenarios. Prediction is the key benefit of the ontological structure we’ve been working to uncover.
This post will introduce a new fundamental layer to our ontology. A layer that represents the instance or literal manifestation of a given tool. Just like our brain, we must realize that every instance of every tool is unique in its own way, but we must simultaneously understand how we can see similarities between unique instances and the implications of said similarities. I will then discuss a cognitive tool that helps me to categorize instances and make decisions for different use cases like detection rule evaluation or purple teaming. I hope you enjoy the post, and as always, I would love to hear your feedback! What resonates with you, what do you agree with, what do you disagree with, etc.
The Literal Level
Thus far in the series, we’ve focused on categories that allow us to appreciate the different variations of a given attack technique or sub-technique, but I feel that we’ve neglected to discuss the instances themselves and create terminology to facilitate this discussion. I want to take a moment to introduce what I call the LITERAL level. As McGilchrist pointed out, from one perspective, everything we encounter in the world is constantly changing and, therefore, always new or different. Traditionally, we might think of two tools (files) as different if they have different cryptographic hash values. This is certainly one measure of difference, but that might not be the only way in which two tools can be differentiated. What if we considered a time element like when the file was created. How about a metadata element, such as who owns the file or what is the file’s name. Alternatively, we might consider a location element such as what system the file exists on. From this perspective, there is an infinite set of possible variations. If we only could view the world this way, we wouldn’t have a concept like ATT&CK, everything would be unique, and we wouldn’t have the ability to categorize what we encounter.
There are literally an almost infinite number of ways in which any attack technique can be manifested. Bytes can be added or subtracted, they can be substituted, and they can be changed to present themselves differently in the world. This is the problem we face as defenders. How do we allocate our finite attention to a relatively infinite problem? The key is abstraction, the power of the left hemisphere. The key is to not confuse the instances with the forms. These literal manifestations of an attack are simply reflections of the Platonic form in our world. However, abstraction allows us to shed the specificity of the literal and understand instances based on their similarities instead of their differences. This world of forms is what we’ve been exploring thus far in this series. With this understanding of the distinction between the instances (the literal) and the forms (the functional, operational, procedural, sub-technical, technical, and tactical), we can reduce the infinite variability of the problem we face to something that is hopefully more manageable. Let’s look at how we can classify the literal instantiation of the LSASS Memory sub-technique into the different levels of forms.
Synonyms
While the ideas posed by McGilchrist, about two different ways to experience the are interesting, there’s a question of practicality. How exactly do we measure the difference? Again, one way to view the world is that everything we encounter is different and constantly changing. While this perspective might technically be more closely related to how the world actually is, it makes detection engineering quite tricky. For that reason, it is helpful to consider the tools as static entities that can be grouped based on similarities, but how do we measure similarity?
One tool in our tool kit is cryptographic hashing algorithms like SHA256. These algorithms are excellent for determining whether two files or, more specifically, two sets of data are the same or different. You can submit data to the algorithm, and a resulting “hash” will be produced. The algorithm will generate the same value every time the same input data is provided. The cool thing is that even small changes to the input data produce significant changes to the output value. The SHA25 algorithm can determine if two tools are the same, at least in the sense of their file’s content. The problem is that a hash algorithm only determines if the files are identical or different. It is a binary result. We cannot determine how similar the files are from the files’ hash values.
Maybe we should ask whether a similarity metric even exists in the first place. Imagine we have two sets of two files. The first set consists of two files; the only difference is one byte that was changed. The second set consists of two files that have no bytes in common. These sets will have different SHA256 hash values and are, therefore, literally different, but we can intuitively say that the files in the first set are more similar than those in the second set. This hypothetical situation is meant to present the limit case because it makes the question easier to answer, but what if there were two sets of two files with one hundred bytes changed? Would they ALWAYS have the same amount of similarity? My answer to this question is, of course, “it depends” (what can I say? I’m a consultant). I think it depends on what the changed bytes represent and how it was changed. Maybe the bytes represent a bunch of unused code and don’t actually change the tool’s functionality, but perhaps they are related to its core functionality and make it act entirely differently when executed. So if files can be more or less similar, is there a way to objectively determine similarity?
To answer this question, I’m introducing a concept called “synonyms.” In language, synonyms are two words that, while literally different, have the same meaning. For example, the words “close” and “shut.” The definition for close is “move or cause to move so as to cover an opening,” while the definition of shut is “move something into position so as to block an opening.” As you can see, one can say “please shut the door” or “please close the door” without losing meaning. I was inspired to think about synonyms in a new way while reading Michael V. Wedin’s “Aristotle’s Theory of Substance: The Categories and Metaphysics Zeta.” ³ Wedin tells us that Aristotle opens The Categories by describing the three Onymies, homonym, synonym, and paronyms. Aristotle tells us that two words are synonyms, “when not only they bear the same name, but the name means the same thing in each case — has the same definition corresponding. Thus a man and an ox are called ‘animals.’ The name is the same in both cases; so also the statement of essence. For if you are asked what is meant by their both of them being called ‘animals,’ you give that particular name in both cases the same definition.”⁴
Now I must admit that initially, this both inspired and confused me. I had previously come up with the idea that Out-Minidump⁵ and Sharpdump⁶ were more similar than Out-Minidump and Mimikatz sekurlsa::logonpasswords⁷, but I didn’t have a way to express this idea propositionally. Synonyms seemed to be the key to unlocking a potential solution, but the condition put forth by Aristotle is that both the NAME and the STATEMENT OF ESSENCE be the same. Out-Minidump and Sharpdump don’t seem to fulfill the first condition, the name being the same for both instances, so does this idea fit the example? Let’s look at Aristotle’s example to see if we can better understand the concept. He describes a situation where both “man” and “ox” can equally be described as “animals.” This refers to the nested reality where all things simultaneously exist in many categories. In this case, man and ox are one level of resolution, but “animal” is a higher, or superordinate, category that describes both man and ox equally. So it seems that if two ideas can be described similarly at a higher level of abstraction, we can refer to them as synonyms.
What if we apply this idea to our current understanding of the ontological hierarchy we’ve been building, where there is a literal, functional, procedural, sub-technical, technical, and tactical level of analysis for all instances? Could it be said, for example, that two tools, or instances, are literally different but functionally synonymous? Or maybe tool tools are both literally and functionally distinct, but they are procedurally synonymous. I believe this idea can help us understand the degree to which two tools diverge from each other, which might have significant implications for our ability to build and evaluate detection rules. For instance, it seems reasonable to assume that a detection rule that detects two tools that are functionally different but are procedural synonyms is a more robust detection rule than one which can only detect two tools that are functional synonyms. Let’s look at a few examples to see exactly how this concept plays out within the OS Credential Dumping: LSASS Memory⁸ sub-technique and potentially beyond.
Functional Synonyms
The first level of categorization within our hierarchy is the functional level. Here we are concerned with the API functions a tool calls to accomplish its tactical objectives. While there are an infinite number of variations at the literal level, categorization allows us to conceptualize these literal variations as a finite set. In part 5, we calculated 39,333 unique functional variations for the LSASS Memory sub-technique.⁹ While 39,333 represents a significant reduction relative to the presumptively infinite number of variations at the literal level, it is still a daunting value. That being said, the functional level is also the first at which we encounter the synonym phenomenon. We find that two tools can be literally different but functionally synonymous. This means that when the code is analyzed to determine which API functions are called, both tools would be seen to call the same functions in the same order. These tools would therefore be “functional synonyms.”
Example
To help make this idea concrete, we can analyze two tools which are literally different, but functionally the same.
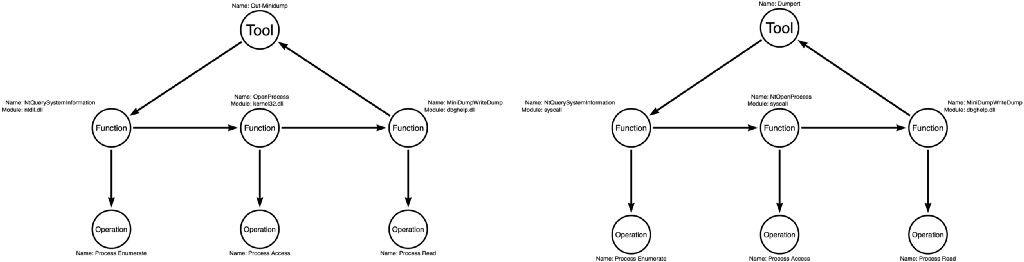
Out-Minidump is a PowerShell script written by Matt Graeber that leverages a technology called “reflection” to allow direct, in-memory, Win32 function calls from PowerShell. Reflection is a popular way for attackers to extend the default functionality of PowerShell. Out-Minidump takes a process identifier and opens a read handle to the target process using kernel32!OpenProcess and uses that handle to create a minidump via dbghelp!MiniDumpWriteDump (Notice that because the process identifier is provided as an argument to Out-Minidump, we don’t know what function was used to enumerate processes, but for simplicity’s sake, we will assume it was ntdll!NtQuerySystemInformation).
Sharpdump is a C# binary that is purpose-built for generating a minidump for the LSASS process. To accomplish this task, Sharpdump calls ntdll!NtQuerySystemInformation to enumerate running processes and find the process identifier for the LSASS process, kernel32!OpenProcess to open a read handle to LSASS, and dbghelp!MiniDumpWriteDump to create the dump file.
The key takeaway here is that although Out-Minidump and Sharpdump are literally different tools, they have different hash values, one is a PowerShell script, and the other is a C# binary, they both rely on the exact same function calls to achieve their outcome. Therefore, we can say that these tools are “functional synonyms,” meaning that from the functional point of view, they are the same. Figure 1 shows an analysis of both tools at the functional level and we can see that they do indeed call identical functions.

Procedural Synonyms
In part 3 of the series, I introduced the function call graph, which among other things, demonstrates that developers are spoiled for choice when it comes to selecting API functions to accomplish a task.¹⁰ It turns out that for any task, many functions can often be used to achieve the desired outcome. We saw this, for example, with kernel32!ReadProcessMemory and ntdll!NtReadVirtualMemory. Most tasks have ~6 function options, but we’ve found some tasks with up to 30 related functions. We found it useful to introduce an abstraction layer called operations to allow us to speak about a set of functions that perform a task instead of being stuck with individual functions. This is helpful because saying 30 different function names every time is a mouth full, and sometimes we are more concerned with the outcome than the specific function. We then discovered that operations rarely occur by themselves. Developers typically combine operations to accomplish a technique. These sequences of operations are called procedures, and this is the next level of analysis where we encounter synonyms.
Procedural synonyms are two tools that are literally and functionally different. They neither have the same cryptographic hash nor call the same functions. However, they do sequence the same operations in the same order as each other. Thinking about the detection problem in terms of procedures may be helpful because while there are 39,333 known functional variations, we have only discovered 4 procedural variations. Notice that the number of variations is exponentially reduced with each layer of abstraction! We can therefore say that procedural synonyms are more different from each other than functional synonyms. We can start to see why these distinctions are useful. If one wants to maximize the difference between two test cases, it would be advantageous to use procedural synonyms instead of functional synonyms. Let’s take a look at an example.
Example
In this example, we will compare Out-Minidump to a new tool called Dumpert.¹¹ Dumpert, a tool introduced earlier in the series, was written by the team at Outflank in the Netherlands. The key feature employed by Dumpert is that instead of calling the Win32 functions like Out-Minidump, it does (almost) everything via syscalls. This means that instead of calling ntdll!NtQuerySystemInformation, kernel32!OpenProcess, dbghelp!MiniDumpWriteDump like Out-Minidump, Dumpert calls syscall!NtQuerySystemInformation, syscall!NtOpenProcess, dbghelp!MiniDumpWriteDump (I told you ALMOST everything).
So unlike the comparison between Out-Minidump and Sharpdump, where the tools were literally different but functionally synonymous, Out-Minidump and Dumpert are both literally and functionally different but procedurally synonymous. That’s because ntdll!NtQuerySystemInformation and syscall!NtQuerySystemInformation both implement the Process Enumerate operation, kernel32!OpenProcess and syscall!NtOpenProcess both implement the Process Access operation, and dbghelp!MiniDumpWriteDump, which both tools use, executes the Process Read operation.
In Figure 2, I’ve added an additional layer to represent the operations corresponding to each function. Notice that the functions are different, but the operations are the same, and importantly, their sequence, from left to right, is the same.
Sub-Technical Synonyms
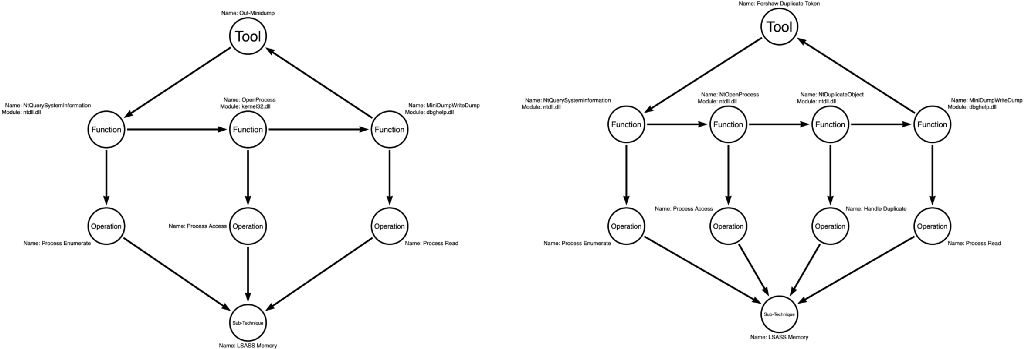
This type of comparative analysis can continue at the next level. We previously defined procedures as “a sequence of operations that, when combined, implement a technique or sub-technique.” This means that for any sub-technique, there will be at least one but likely many procedures that can be used to implement it. This is the last step before transitioning from a micro, intra-technique level to a macro, inter-technique level of analysis. Tools that differ at the procedural level, meaning they choose and sequence operations differently, but still implement the same sub-technique, can be referred to as sub-technical synonyms. This seems to be the highest level at which an instance (tool) would be relevant to a detection rule because most detection rules don’t transcend the technique, but there are likely exceptions to that rule. Let’s look at an example of two tools that are literally, functionally, and procedurally different but still implement the same sub-technique and are thus sub-technical synonyms.
Example
In this example, we compare Out-Minidump to the approach that James Forshaw introduced in his “Bypassing SACL Auditing on LSASS” post.¹² This procedure can be implemented using James’ NtObjectManager PowerShell module,¹³ but there are a relatively infinite number of possible implementations. The exciting thing is that James went further than Outflank did with Dumpert. Instead of simply changing the function calls, James changed the operations he used to achieve the outcome. While Out-Minidump approaches the problem by sequencing Process Enumerate, Process Access, and Process Read together to implement LSASS Memory Dumping, James adds Handle Copy to the sequence, which in turn becomes Process Enumerate, Process Access, Handle Copy, and Process Read. In the process of adding an operation to the orthodox procedure, James created a new procedure. This small change evades Microsoft’s SACL on LSASS. Therefore, Out-Minidump and NtObjectManager differ at the procedural level but converge at the sub-technical level. This makes them sub-technical synonyms.
Figure 3 compares the tools at the functional, procedural, and sub-technical levels. Notice that despite taking different routes, both tools eventually implement the LSASS Memory sub-technique.
Technical and Tactical Synonyms
From a detection perspective, I believe that after the sub-technical level, we begin to transition from a micro to a macro focus, and as a result, the utility of comparisons at the higher levels of the ontological structure is diminished. However, I thought it might be interesting to conceptually explore how technical and tactical synonyms would manifest. Technical synonyms are tools that perform the same technique (OS Credential Dumping) but differ at all lower levels of the hierarchy. Similarly, tactical synonyms belong within the same tactic grouping (Credential Access) but differ at the technical level and below. This section provides two examples, one demonstrating technical synonyms and one showing tactical synonyms. I found that the graphics begin to lose their impact at this level, so the examples below only include descriptions, which I think adequately demonstrates the point.
Technical Example
A fourth example compares Out-Minidump to Mimikatz’s lsadump::dcsync command.¹⁴ While Out-Minidump implements the LSASS Memory sub-technique, Mimikatz’s lsadump::dcsync goes a different route, establishing its own sub-technique, called DCSync¹⁵. While the LSASS Memory sub-technique focuses on dumping credentials stored in the LSASS process’s memory, DCSync imitates a Domain Controller to fool a legitimate Domain Controller into sending credential information to the compromised system. These tools not only differ literally, functionally, and procedurally, but they differ sub-technically as well. However, while they differ at all those analysis levels, they implement the same technique, OS Credential Dumping. This means that we can refer to these tools as technical synonyms.
Tactical Example
Lastly, we can compare Out-Minidump to Invoke-Kerberoast.¹⁶ Interestingly, both tools are written in PowerShell, but that’s where their similarities end. As we’ve discussed previously, Out-Minidump is a tool specifically used to perform the LSASS Memory sub-technique of the OS Credential Dumping technique. Invoke-Kerberoast, on the other hand, does not implement either the LSASS Memory sub-technique or the OS Credential Dumping technique. Instead, it executes the Kerberoasting sub-technique¹⁷ of the Steal or Forge Kerberos Tickets technique. However, these tools converge at the tactical level as they both implement the Credential Access tactic. When an attacker is interested in obtaining a particular set of credentials, both Out-Minidump and Invoke-Kerberoast are valid choices depending on the details of the user account of interest and other tradecraft considerations. We can now say that Out-Minidump and Invoke-Kerberoast are tactically synonymous because they both implement the Credential Access tactic.
Conclusion
Let us consider why or how this concept of synonyms might be practical. Imagine that you created a detection rule to detect the OS Credential Dumping: LSASS Memory sub-technique. A common strategy for evaluating the efficacy of the resulting detection rule is to test it using many different tools. The idea is that if the detection rule can detect a diverse set of tools that implement the sub-technique, it must be robust. However, we have to be careful because the traditional view of “different” is generally limited to the LITERAL level of analysis. We might look at threat reports and find different tools made by different people that accomplish the same sub-technique and run them, but we never consider just HOW different these tools are from one another.
It is actually quite common in my experience for this process to result in a test where four tools are used to evaluate a detection rule, but the four tools are functional synonyms. This means the tools only differ at the literal level, the most superficial level of analysis. Remember that at the functional level of analysis, we’ve discovered 39,333 variations, and there are probably more that remain to be found. This means that our test using four different tools only evaluates 1 out of 39,333 possible functional variations. So maybe the first step should be to ensure that when we select four tools to test, the four tools should be procedural synonyms. This means that the tools would implement different functional variations. However, that is still only 4 of 39,333 functional variations. It stands to reason that of all the possible sets of four functional variations, some sets are better representatives of the range of possibilities than others. We can think of this as population sampling in a medical trail. So how might we choose the optimal set?
My proposal is that we look higher in the ontological hierarchy. While we’ve uncovered 39,333 functional variations thus far in our analysis of OS Credential Dumping: LSASS Memory, we’ve only uncovered 4 procedural variations. I’d propose that if we want to maximize the representation of the possible variations for this sub-technique, it would be ideal to select instances (tools) that are procedurally distinct, meaning they would be sub-technical synonyms. This would maximize the diversity of the tools while still maintaining a sub-technique focus. I think of this as basically triangulating the detection because we can’t achieve a perfect picture, but we can estimate how well our detection rule performs. Of course, there is probably still room for nuance during test selection. For instance, within a given procedure, there is likely an ideal functional variation to maximize the value of the test. I haven’t figured out how to determine this yet, but it seems intuitively likely. Let me know what you think.
References
[1]: McGilchrist, Iain. (2009). The master and his emissary: The divided brain and the making of the western world. Yale University Press.
[2]: Atkinson, Jared C. (2022, September 8). Part 6: What is a Procedure?. Medium.
[3]: Wedin, Michael V. (2000). Aristotle’s theory of substance. Oxford University Press.
[4]: Aristotle. (1938). Categories (H.P Cooke, Hugh Tredennick, Trans.). Loeb Classical Library 325. Harvard University Press.
[5]: Graeber, Matthew. Out-Minidump. (2013). GitHub repository.
[6]: Schroeder, William. Sharpdump. (2018). GitHub repository.
[13]: Delpy, Benjamin. Mimikatz sekurlsa::logonPasswords. (2014). GitHub repository.
[8] Williams E., Millington E. (2020, February 11). LSASS Memory. MITRE ATT&CK.
[9]: Atkinson, Jared C. (2022, August 18). Part 5: Expanding the operation graph. Medium.
[10]: Atkinson, Jared C. (2022, August 9). Part 3: Expanding the function call graph. Medium.
[11]: Outflank. Dumpert. (2019). GitHub repository.
[12]: Forshaw, James. (2017, October 8). Bypassing SACL Auditing on LSASS.
[13]: Forshaw, James. NtObjectManager. (2016). GitHub repository.
[14]: Delpy, Benjamin; Le Toux, Vincent. Mimikatz lsadump::dcsync. (2017). GitHub repository.
[15]: Le Toux, Vincent; ExtraHop. DCSync. (2020, February 11). MITRE ATT&CK.
[16]: Schroeder, William. Invoke-Kerberoast. (2016). GitHub repository.
[17]: Praetorian. Kerberoasting. (2020, February 11). MITRE ATT&CK
On Detection: Tactical to Functional Series
- Understanding the Function Call Graph
- Part 1: Discovering API Function Usage through Source Code Review
- Part 2: Operations
- Part 3: Expanding the Function Call Graph
- Part 4: Compound Functions
- Part 5: Expanding the Operational Graph
- Part 6: What is a Procedure?
On Detection: Tactical to Functional was originally published in Posts By SpecterOps Team Members on Medium, where people are continuing the conversation by highlighting and responding to this story.