Into The Rainbow: Google’s NTLMv1 Rainbow Tables Explained in a Bit Too Much Detail
Author
Skyler Knecht
Read Time
10 mins
Published
Apr 16, 2026
TL;DR: Google published a blog post with accompanying rainbow tables targeting the Data Encryption Standard (DES) key space. The tables enable recovery of the NT hash used to generate the ciphertexts in NTLMv1 responses. We’ll dive into the tables, the recovery process, and ideally demystify any lingering questions.
Acknowledgements
There are many previous works on the subject, such as;
1. Nic Losby, his blog post, and the amazing work he has led over the past few years to generate the tables
2. Joe Testa and the rainbowcrackalack project, which inspired a lot of work within this blog
3. David Hulton and Moxie Marlinspike and their DEFCON 20 talk, shedding light on the weaknesses of MS-CHAPv2
4. Philippe Oechslin, who produced the original white paper on rainbow tables
5. Anyone I’ve worked with and collaborated with along the way
The Terms
For a deep dive into all things NTLM, please review this white paper by Elad Shamir. In this blog, I assume the reader understands the differences between NTLMv1 and NTLMv2 and the concept of an NT hash. Any time the term “NTLMv1 response” is used, I’m referring to the ciphertexts generated by the client during the “Authenticate” message. When the term “DES key” is used, we’re referring to one of three 7-byte keys, derived from the NT hash, used to encrypt the static challenge of 1122334455667788.
Introduction
NTLMv1 is a legacy authentication protocol that uses a cryptographically weak encryption algorithm, permitting operators to recover the NT hash used to generate the NTLMv1 response. Historically, operators obtained NTLMv1 responses using tools such as Responder and recovered the NT hash using third-party resources. Recently, however, a new attack primitive has been made available with the release of Valdemar Carøe’s DumpGuard and Google’s NTLMv1 rainbow table. Operators can now obtain NTLMv1 responses for the current user on Windows systems with Credential Guard enabled and recover the NT hash offline. I intend for this blog to demystify this recovery process and provide adequate tooling to perform it. First, we’ll start with a brief overview of the problem, the tables themselves, and the recovery process, which is broken into three phases: precompute, lookup, and check. From there, we’ll cover the tooling designed to operationalize the tradecraft and statistics from our testing. Lastly, we’ll cover the issue of anonymity, a common concern in public recovery services, along with closing thoughts.
The Problem
NTLMv1 uses DES, a weak encryption algorithm whose key space is small enough that all possible keys can be precomputed. During authentication, the client:
- Receives a challenge from the server
- Splits their NT hash into three 7-byte DES keys
- Encrypts the challenge with each key, producing three ciphertexts (CT1, CT2, CT3)
- Sends all three ciphertexts to the server
The rainbow table stores nearly every possible DES key for the static challenge 1122334455667788, along with the ciphertext (CT) each key produces. Given any CT encrypted with this challenge, an operator can use the table to recover the DES key used to encrypt it. Recover all three DES keys, recombine them, and you have the original NT hash.
Tables
It’s first important to note that the “rainbow table” is not just one table but 4,096 tables, each around 2.147 GB in size. Some quick math puts that at around 8.8 TB. If we download one of the tables, we’ll see a name like netntlmv1_byte#7-7_0 appended with 881168x134217668_0.rt. We only care about the second part. The first number, 881,168, is the length of each chain, followed by 134,217,668, the number of chains in each table. Each link in the chain covers exactly one DES key and its CT, giving us roughly 118,268,314,076,224 keys per table. Multiply that by 4,096 tables, and we land around 2⁵⁹ total DES keys, about eight times more than the full DES key space of 2⁵⁶ (see RFC 4772 Section 4). So why compute more? Rainbow tables are susceptible to collisions, so we overshoot the key space to effectively hit 99.9% of all possible keys. Does that mean we just store every DES key? Not exactly.
Let’s take a look at a simplified rainbow table structure shown below. In short, it’s a list of chains that start and end with a DES key. You take a key, do some magic stuff, get another key, and repeat.
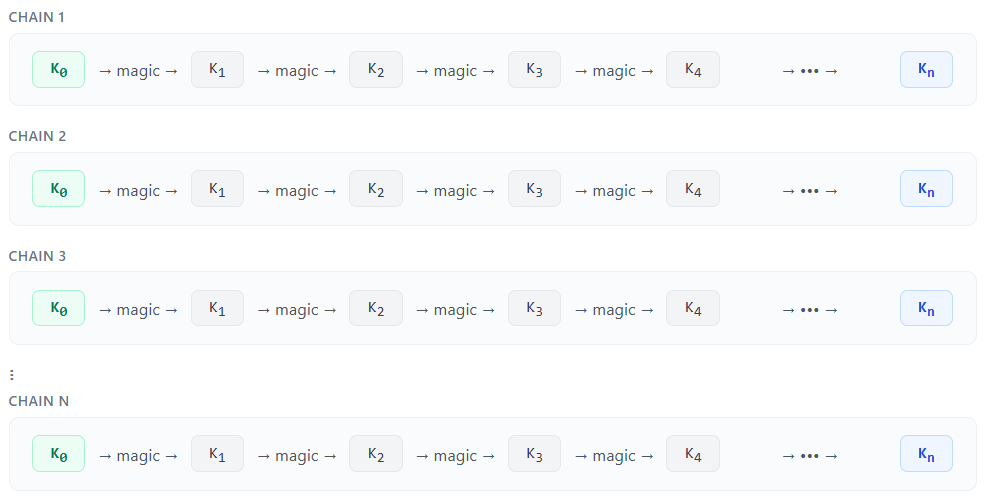
The “magic” is two operations. First, DES encryption using our key and a static challenge to produce a CT, followed by a reduction function. One link of a chain is shown below.

Notice how the reduction function produces the next key? This is intentional. The reduction function takes the CT, a static offset, and the current chain position to generate a new key that is unlikely to occur again. As mentioned before, if we repeat this process 881,168 times by 134,217,668 total chains for 4,096 tables, we’ll cover 99.9% of the total DES key space. Ideally, we’d store every DES key and its corresponding ciphertext, but at 15 bytes per link across 2^56 keys, that would require over 1,000 PB of storage. Instead, we store only the start and end for each chain. This might seem useless, but it’s enough that, given some computation, we can recover a ciphertext to the DES key that generated it.
Recovery Process
The recovery process includes three phases: precompute, lookup, and check.
Precompute
The precompute phase generates new chains, assuming the ciphertext is present at each position. For example, if our CT were at P0, what key would be produced when applying the reduction function? We then apply the DES function to the generated key to produce a new CT, and repeat until we reach the end of the chain. Once we reach the end, we store that key, called an endpoint. This means we’ll always generate 881,168 endpoints:, the total number of positions.
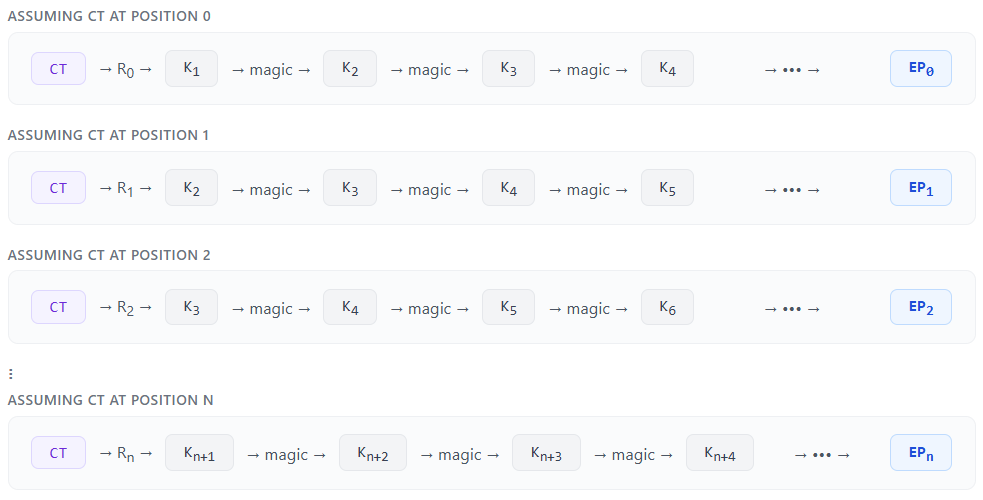
Lookup
The idea is that if one of our endpoints matches an endpoint inside the rainbow table (the last key in a chain), then we can conclude our CT exists at the position we used to generate that endpoint. More importantly, the key that produced this ciphertext is our key, right? Unfortunately, it’s not that simple due to collisions. Two unique CTs at the same position can yield the same endpoint. See the example below: two different ciphertexts, 535549550D915078 (CTtarget) and 3260DF30E5773FDA (CTactual), both exist at position 709,139 in their respective chains.
After applying the reduction function, R709139, we get completely separate keys Ka and Kb. But after 91,754 links, two different ciphertexts, 29ACCD0DFEA880EF (CT1) and 29ACCD0DFEA8804A (CT2), produce the same key 80A8FE0DD9E4A6 (Kmerge). From that point forward, the chains are identical and result in the same endpoint, 00AAF6AB1219EF (EP). So while CTactual ended with one of our target endpoints, it did not contain our CT, an unfortunate false positive.
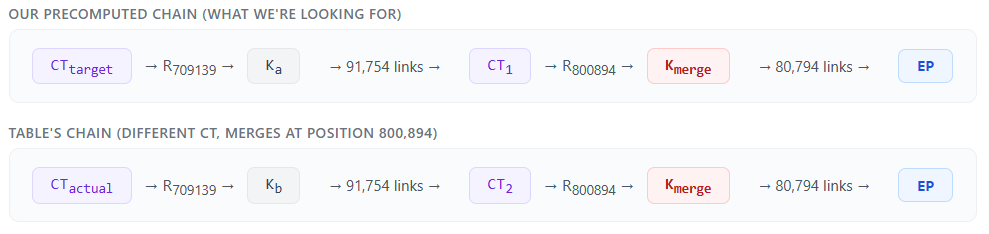
So instead, we conclude that every endpoint that matches an endpoint from our precompute phase indicates a chain that may contain our CT. This is called a candidate.
Check
How do we actually find our CT in these candidates? We use brute force by regenerating every candidate chain to the specified position and checking whether our CT is there. The difference is that we now have a few million candidates to check at specific positions, rather than regenerating all 549 billion chains at their full length. Once we identify which chain contains our CT, it’s as simple as taking one step back and examining the key that generated it. That’s our DES key!
Tooling
Overview
I’ve taken rainbowcrackalack, originally created by Joe Testa, then forked and extended with GPU support by Nic Losby, and split it into the phases above. The project is open-sourced here. There are four applications entitled gpu_lookup, precompute, candidate_lookup, and candidate_check. The latter three correspond to their respective phases. The first combines all the phases and executes them together. There is also an NTLMv1 assistant to aid in converting various parts of the process.
To begin, we’ll use DumpGuard to obtain an NTLMv1 response for the current logged-on user.

Next, we’ll use the NTLMv1 assistant to parse the response into three separate ciphertexts.
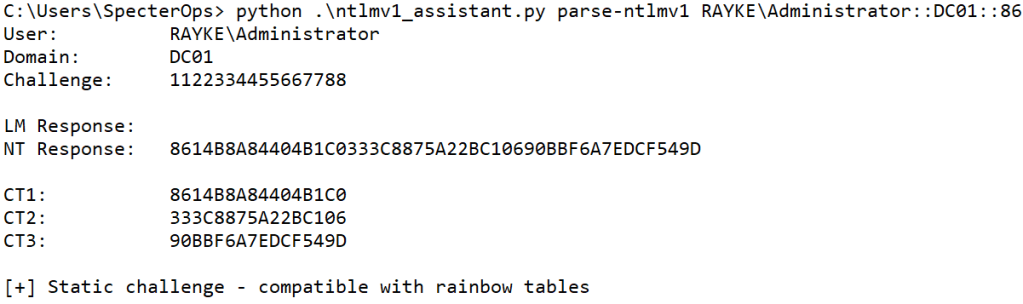
We can then perform our recovery process, starting with precompute. The precompute application takes a CT followed by an output filename for the computed endpoints.

Next, we have candidate lookup, the only phase that requires the tables. Candidate lookup uses the endpoints from the precompute phase to identify all chains in the table with the same endpoint. These are called candidates.

Lastly, we have our candidate check. With our candidates identified, we’ll need to recompute all chains to the stored candidate positions and verify whether our CT actually exists at those positions. If so, we can step back and identify our DES key.

We’ll need to repeat this process twice for both CT1 and CT2; however, CT3 is only two bytes with some padding, so it can be recovered with the NTLMv1 assistant.

With all three keys recovered, we can combine them to get the NT hash.

Statistics
In my experience, this process takes approximately one hour per ciphertext, using two NVMe drives and an RTX 3080 Ti, with precompute averaging 12 minutes, lookup averaging 45 minutes, and check averaging 12 minutes. Since the phases are decoupled, it’s entirely possible to parallelize work across multiple NVMe drives and GPUs. I observed a substantial performance improvement by splitting the tables across separate NVMe drives and running multiple candidate lookup processes to maximize disk bandwidth.
Anonymity
A common concern with public NTLMv1 recovery services is that a client name could be exposed from a cracked NT hash. If a service reconstructs the NT hash from the recovered DES keys and cracks it offline, the recovered plaintext password may include a client name, thereby revealing the target’s identity. With the decoupled approach, we present a potential solution: only the precompute and check phases require knowledge of the ciphertext. During the precompute phase, each candidate represents a potential match, but the vast majority are false positives. So while one of the candidate chains may contain your CT, it’s one of millions.
Additionally, without the ciphertext being provided during the check phase, the candidates are useless. You can regenerate every candidate chain to the position that should contain your CT, but it’s not guaranteed to be there. Therefore, even if you encounter the CT, without knowing which CT was used to generate the endpoints during the precompute phase, you have no way to determine which one is relevant. The anonymous lookup process would be as follows.
1. Run precompute locally and generate the endpoints on your own machine
2. Upload an anonymously named endpoints file to a candidate lookup service
3. Download the candidates and provide them to the check application along with the ciphertext you’re targeting
Closing Thoughts
Again, I hope this work inspires you to develop your own recovery system and operationalize the research. As Moxie Marlinspike and David Hulton originally mentioned at the end of their DEFCON 20 talk, and as Nic Losby noted in his blog, we’ll ideally break the cycle of legacy protocol usage by lowering the barrier to recovering an NT hash from NTLMv1 responses.